No.277 - 視覚心理学と絵画 [アート]
No.243「視覚心理学が明かす名画の秘密」と No.256「絵画の中の光と影」で、九州大学名誉教授の三浦佳世氏が書かれた「視覚心理学が明かす名画の秘密」(岩波書店 2018)と「絵画の中の光と影 十選」(日本経済新聞。2019年3月。10回連載のエッセイ)の "さわり" を紹介しました。今回はその「視覚心理学と絵画」というテーマの補足です。
2013年にアメリカの「Scientific American誌 特別版」として発行された、
という本があります。著者の2人はアメリカのバロー神経学研究所に所属する神経科学者で、本の日本語訳は、
です(以下「本書」と記述)。本書は20のトピックごとの章に分かれていて、その中に合計187の錯視・錯覚・イルージョンが紹介されています。ここから絵画に関係したものの一部を紹介したいと思います。
視覚は脳の情報処理
まず具体的な絵画に入る前に、人間の視覚の本質の話です。人間の視覚は「脳が行う情報処理の結果」だと言えるでしょう。本書にも、はじめの方に次のように書いてあります。
我々はどうしても「眼」と「カメラ」のアナロジーで考えてしまいます。水晶体がレンズの役割をにない、網膜がフィルム(ないしは半導体センサー)に相当していて、そこに像が結ばれ、その像がすなわち視覚だと ・・・・・・。
しかしそのあとがあります。脳は網膜の像をもとに様々な処理を加えて視覚という認識ができあがる。カメラの画像でも、デジタル画像であればアプリでさまざまな加工が可能です。たとえば顔を若く見せたり、小顔にしたり、肌を綺麗にしたりといったことができる。人間の「眼球」は確かに「カメラ」かもしれないが、「視覚」は「カメラ + 画像加工アプリ」に相当するのです。
その、脳が網膜の画像をどのように "加工して" 視覚を生み出すのか、その結果が現実の物理的実体とずれているのが錯視です。以下に絵画に関係した錯視を2つあげます。
脳が生み出す輝度と色
まず、No.243「視覚心理学が明かす名画の秘密」でも取りあげた "エーデルソン錯視" です。この錯視において A のマス目と B のマス目は違った明るさ(=輝度)に見えますが、実は全く同じ明るさです。2つのマス目の間に無理矢理ブリッジを作ると、同じ明るさであることがわかります。
なぜこの錯視が生まれるのでしょうか。まず、A は白っぽいマス目に囲まれていて、B は黒っぽいマス目に囲まれています。人間の脳は周囲が白いと対象をより黒く、周囲が黒いと対象をより白く認識するのです。
さらに大きな理由は B は「影の中にある」と認識できることです。人間の脳は、影の中にあるものについては本来の輝度を復元しようとして輝度を上乗せして認識するのです。
無理矢理ブリッジを作った図を見て同じ輝度だとわかったとしても、エーデルソン錯視を再び眺めると同じ輝度だとは絶対に感じられません。白と黒としか見えない。これは知識ではコントロールできない脳の視覚系の情報処理であり、極めて強固な情報処理だということがわかります。
エーデルソン錯視は物体の明るさ(輝度)に関するものですが、同様の錯視は色についても起こります。その例を次にあげます。名称にした「ロット・パーベス錯視」は一般的ではないし本書にも載っていませんが、発見者(錯視の作成者)の名前をとって便宜上そう呼ぶことにします。
この図において矢印を付けた、上面の茶色に見える正方形と側面のオレンジ色に見える正方形は、実は全く同じ色です。しかし人間の眼には、同系統の色には違いないが全く異なった色に見えます。これもエーデルソン錯視と同じで、周りの色の状況と影の中かそうでないかの違いで起こります。2つのタイルの間に無理矢理ブリッジを作ると同じ色であることが分かります。
エーデルソン錯視とロット・パーベス錯視でわかることは、物体の輝度や色は周囲との関係によって知覚され、その場の状況や前後関係で変わって認識されるということです。それはちょうど、文章における単語の意味が文脈によって変わることに似ています。話言葉だと「話し方」によっても同じ単語の意味が変わる。
優秀な画家はこのような視覚における脳の働きを(意識的に、または無意識に)熟知していて、色の配置を決め、影の表現をしています。
脳が生み出す遠近感
脳は遠くにあるものと近くのものをどうやって認識しているのでしょうか。実際に眼で現実の風景を見る場合は両眼視ができるので、視差から距離の判別が可能です。では、2次元の絵画や写真の「奥行き」はどうやって感じるのか。
絵画で有名なのは遠近法(線遠近法)です。実世界で平行なもの(平行だと想定できるもの)が画面上で次第に狭まっていくと、狭まる方向が「遠い」「深い」と認識できます。
また、遠くのものは小さく、近くのものは大きく見えるという原理もあります。常識的に考えて同程度の大きさのものが2つあり、その大きさが違うと遠近感が出ます。さらに、遠くのものがぼやけて見え、近くのものがはっきり見えることで遠近感を感じることもあります。絵画では空気遠近法(大気遠近法)と呼ばれます。
もちろんそれ以前に、遠くの物体が近くの物体の陰になって見えないという「遮蔽」も、当然ですが遠近感を生み出します。
以上のように脳はさまざまな方法で遠近感を知覚していますが、これらの中で、平行線による遠近法に関連してで起こる脳の錯覚が「斜塔の錯視」です。
この画像はイタリアの有名な「ピサの斜塔」で、下から斜塔を見上げて撮影したものです。従って画像の上の方がより遠くにあると認識されます。斜塔の2つの側面は実世界では平行ですが、写真では遠くになるにつれて狭く見える。これはストレートな遠近法による奥行きの知覚です。
しかしこの写真を2枚左右に並べると、右の写真の斜塔がより右に傾いて見えます。明らかに錯視です。なぜそうなるのかと言うと、左右の斜塔が画面上で平行だからです。斜塔の右側の線も左側の線も、同一の写真なのだから2枚で平行なのはあたりまえです。一方で脳は、写真の上の方が遠くにあると認識している。ということは、遠くになるほど2つ斜塔は広がっていないと画面上で平行にならない。このため、右の斜塔が左の斜塔よりも右の方に傾いて見えるわけです。
この錯視は「ピサの斜塔」の写真を用いて初めて発表されたので「斜塔の錯視」と呼ばれていますが、斜塔でなくても起こります。次の画像は線路の写真での例です。線路によって人間の眼は左上に向かって遠くになっていると強く認識します。そのため、左の写真の線路と右の写真の線路は斜めの角度が違って見えます。右の写真の線路の傾きがよりゆるく見える。
この線路の写真は、地面上の2本の平行線が左右にありますが、平行線は上下にあっても斜塔の錯視が起こります。本書にはありませんが、次の図は No.112、No.123 に画像を掲載した古代ローマの水道橋、ポン・デュ・ガール(フランス)です。遠近感がはっきりした写真を上下に並べると、水道橋の傾きが違って見えます。
斜塔の錯視は「遠近感がない」と認識できる絵や写真では起こりません。次の絵は本書に掲げられているものですが、2人の女の子は同一の角度で傾いています。
斜塔の錯視でわかるのは、2次元平面(絵画、写真、イラストなど)の遠近感は、平行線による遠近法の効果が強烈であることです。実世界において平行と想定できる2つの線が次第に狭くなっていくと奥行きを強く感じる。もちろん画家は、これを最大限に活用して3次元空間を絵の中に閉じこめてきたわけです。それは消失点が1つの「1点透視」による遠近法でなくてもかまわない。No.243「視覚心理学が明かす名画の秘密」に "1点に収斂しない透視図法" の例として、フェルメール『牛乳を注ぐ女』とデ・キリコ『街の神秘と憂鬱』を引用しました。
以上、視覚は脳の情報処理であることを例とともにあげましたが、以降は本書に示されている「視覚と絵画」に関係したトピックを4つだけ紹介します。
輝度の秘密:モネ
下の画像はモネの『印象・日の出』(1872。パリのマルモッタン美術館蔵)です。ルアーブルの港の風景を描いたこの絵は、印象派の名前の由来になった絵で、誰もが知っている超有名絵画です。この絵画にはある秘密があります。
引用で「太陽があたかも現れたり消えたりするように見える」とあります。もちろん絵の全体を眺めているときは「現れたり消えたりする」ことはないでしょう。しかし、この絵の左下にあるモネのサインのあたりを中心視でじっと見つめると、周辺視している太陽が消えてしまうように感じないでしょうか。
一般的に言って「輝度が同じものは、やや判別しにくい」(本書)のです。この絵は「日の出」というタイトルどおり太陽がアクセントになっています。しかし "全体に漂うボーッとして混沌とした雰囲気" を作り出している一つの要因が「太陽と朝の空が同じ輝度」ということでしょう。
ピカソの色拡散
"色拡散" とは聞き慣れない言葉ですが、色が本来あるべき形をはみ出し、滲み出して、周りに拡散している状況を言っています。次のピカソの絵について、本書では次のように解説されています。
この絵は「形」がいろいろと省略されていると同時に、子どもの足が典型ですが、形が単純化されています。しかし省略や単純化をしても、我々の視覚は本来あるべき線を補い、本来の形を想像して受け取ります。絵画ではよくあることです。
それに加えてこの絵の特徴は、形に付随しているはずの色が、形から滲み出し、はみ出し、あたりにボーッと広がっている(拡散している)ことです。こうなっても我々の視覚は全く違和感を感じません。解説にあるように、形にちゃんと色を割り当てて見ているのです。
これは水彩画によくある手法ですが、ピカソのこの絵は油絵です。油絵ではあるが、水彩のような淡い色調が使ってある。それが "色拡散" で違和感を感じない原因の一つになっているのでしょう。
しかしこの絵は単に「水彩の技法で描いた油絵」ではありません。"色拡散" で描くことによって「母が子を優しく包み込んでいる感じ」や「母と子が融合して一体化している感じ」がよく出ています。画家が表現したかった精神性と使った絵画手法が不可分にマッチしているところが、この作品の価値だと思います。
デュフィの色拡散
「本書」では色拡散の例としてピカソの作品があげてありますが、そもそも色拡散を多用して作品を作ったのはラウル・デュフィ(1877-1953)です。三浦佳世氏の「視覚心理学が明かす名画の秘密」(No.243)にその解説があるので、それを引用します。下線は原文にはありません。漢数字を算用数字にしたところと、ルビを追加したところがあります。
デュフィの絵の全部を「色拡散」という言葉でくくってしまうのは不適切なのかもしれません。"拡散" というと、形の中に閉じ込められていた色が周りに滲みだし、はみ出て広がっていくイメージです。ところが上の作品などは「色に形を添えた」絵に見えるわけです。
さらに三浦氏は脳神経科学の知見をもとに「形」と「色」と「動き」を認識する脳の不思議なメカニズムに言及しています。
我々はデュフィやピカソの "色拡散" の絵を見ても違和感を全く感じないのですが、それは "意外にも" 脳の働き方とマッチしているからなのでしょう。
顔を認識する脳の働き
「本書」に戻ります。イタリア出身でウィーンで活躍したジュゼッペ・アルチンボルドは、果物、野菜、動植物などを寄せ集めた肖像画を描いたことで有名です。
人間の眼は顔の認識に特に敏感で、顔ではないものにも顔を見つけようとします。よく "人面魚" などの「動物の模様が顔に見える」のが話題になったりします。いわゆる "心霊写真" もそうだし、月や火星のクレーターの写真が顔に見えることもある。「私たちの脳が、わずかなデータに基づいて顔の造作と表情を検知し、認識し、見分けるようにできている」と引用にありますが、まさにその通りで、それこそが人間の社会生活にとって必須の能力だからでしょう。
モナリザの微笑みの秘密
本書には "世界で一番有名な絵" である、ルーブル美術館の『モナ・リザ』についての解説もありました。モナ・リザの「謎の微笑」についての神経科学からの説明です。微笑んでいるのか、いないのか、そのはざまにあるような微妙な表情ですが、次のように解説してあります。
要約すると、
ということでしょう。本書には参考のために次の図が提示してあります。これは周辺視を疑似する目的でモナ・リザを画像処理でぼかしたものです。右が視野の周辺での見え方で、左が視野の端の方での見え方に相当します。視野の端に行くにつれて、我々はより微笑んでいるように感じている。これが「謎の微笑」を生み出しているという分析でした。
モナリザが "世界で一番有名な絵" になった理由は、まさに「謎めいた表情」だと思います。その「謎」に人々は引き込まれる。この「謎」を作り出している絵画技法が、スフマートというのでしょうか、絵の具の薄い層を幾重ともなく塗り重ねて、全く境目がない色と輝度の変化を作り出したことでしょう。ダ・ヴィンチの天才が神経科学の面からも裏付けられたということだと思います。
2013年にアメリカの「Scientific American誌 特別版」として発行された、
| Scientific American Mind 187 Illusions」 | |
| マルティネス = コンデ(Susana Martinez-Conde)、マクニック(Stephen Macknik)著 |
という本があります。著者の2人はアメリカのバロー神経学研究所に所属する神経科学者で、本の日本語訳は、
| 脳が生み出すイルージョン ── 神経科学が解き明かす錯視の世界」(別冊日経サイエンス 198) |
です(以下「本書」と記述)。本書は20のトピックごとの章に分かれていて、その中に合計187の錯視・錯覚・イルージョンが紹介されています。ここから絵画に関係したものの一部を紹介したいと思います。
なおタイトルに「視覚心理学」と書きましたが、もっと一般的には「知覚心理学」です。さらに医学・生理学からのアプローチでは「神経生理学」であり、広くは「神経科学」でしょう。どの用語でもいいと思うのですが、三浦佳世氏の著書からの継続で「視覚心理学」としました。
視覚は脳の情報処理
まず具体的な絵画に入る前に、人間の視覚の本質の話です。人間の視覚は「脳が行う情報処理の結果」だと言えるでしょう。本書にも、はじめの方に次のように書いてあります。
|
|

しかしそのあとがあります。脳は網膜の像をもとに様々な処理を加えて視覚という認識ができあがる。カメラの画像でも、デジタル画像であればアプリでさまざまな加工が可能です。たとえば顔を若く見せたり、小顔にしたり、肌を綺麗にしたりといったことができる。人間の「眼球」は確かに「カメラ」かもしれないが、「視覚」は「カメラ + 画像加工アプリ」に相当するのです。
その、脳が網膜の画像をどのように "加工して" 視覚を生み出すのか、その結果が現実の物理的実体とずれているのが錯視です。以下に絵画に関係した錯視を2つあげます。
脳が生み出す輝度と色
| エーデルソン錯視 |
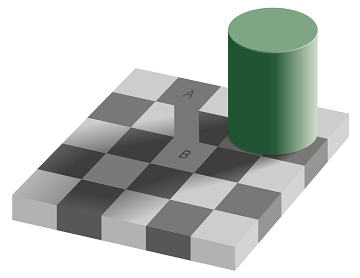
まず、No.243「視覚心理学が明かす名画の秘密」でも取りあげた "エーデルソン錯視" です。この錯視において A のマス目と B のマス目は違った明るさ(=輝度)に見えますが、実は全く同じ明るさです。2つのマス目の間に無理矢理ブリッジを作ると、同じ明るさであることがわかります。

|
エーデルソン錯視 |
マサチューセッツ工科大学の視覚研究者、エーデルソン(Edward H. Adelson)が作成した錯視。A と B は同じ輝度であるが、そうは絶対に見えない(上の図)。Wikipediaより。 |
なぜこの錯視が生まれるのでしょうか。まず、A は白っぽいマス目に囲まれていて、B は黒っぽいマス目に囲まれています。人間の脳は周囲が白いと対象をより黒く、周囲が黒いと対象をより白く認識するのです。
さらに大きな理由は B は「影の中にある」と認識できることです。人間の脳は、影の中にあるものについては本来の輝度を復元しようとして輝度を上乗せして認識するのです。
無理矢理ブリッジを作った図を見て同じ輝度だとわかったとしても、エーデルソン錯視を再び眺めると同じ輝度だとは絶対に感じられません。白と黒としか見えない。これは知識ではコントロールできない脳の視覚系の情報処理であり、極めて強固な情報処理だということがわかります。
| ロット・パーベス錯視 |
エーデルソン錯視は物体の明るさ(輝度)に関するものですが、同様の錯視は色についても起こります。その例を次にあげます。名称にした「ロット・パーベス錯視」は一般的ではないし本書にも載っていませんが、発見者(錯視の作成者)の名前をとって便宜上そう呼ぶことにします。

|
ロット・パーベス錯視 |
ロンドン大学のロット(R. Beau Lotto)とデューク大学のパーベス(Dale Purves)が作成した錯視。矢印で示した2つのタイルは全く同じ色である。本書より。 |
この図において矢印を付けた、上面の茶色に見える正方形と側面のオレンジ色に見える正方形は、実は全く同じ色です。しかし人間の眼には、同系統の色には違いないが全く異なった色に見えます。これもエーデルソン錯視と同じで、周りの色の状況と影の中かそうでないかの違いで起こります。2つのタイルの間に無理矢理ブリッジを作ると同じ色であることが分かります。

|
ロット・パーベス錯視(説明) |
2つのタイルの間に無理矢理ブリッジを作ると、同じ色であることが分かる。この図では同じ色だが、オリジナルのロット・パーベス錯視(上図)を再び見ると違った色に見える。 |
エーデルソン錯視とロット・パーベス錯視でわかることは、物体の輝度や色は周囲との関係によって知覚され、その場の状況や前後関係で変わって認識されるということです。それはちょうど、文章における単語の意味が文脈によって変わることに似ています。話言葉だと「話し方」によっても同じ単語の意味が変わる。
優秀な画家はこのような視覚における脳の働きを(意識的に、または無意識に)熟知していて、色の配置を決め、影の表現をしています。
脳が生み出す遠近感
脳は遠くにあるものと近くのものをどうやって認識しているのでしょうか。実際に眼で現実の風景を見る場合は両眼視ができるので、視差から距離の判別が可能です。では、2次元の絵画や写真の「奥行き」はどうやって感じるのか。
絵画で有名なのは遠近法(線遠近法)です。実世界で平行なもの(平行だと想定できるもの)が画面上で次第に狭まっていくと、狭まる方向が「遠い」「深い」と認識できます。
また、遠くのものは小さく、近くのものは大きく見えるという原理もあります。常識的に考えて同程度の大きさのものが2つあり、その大きさが違うと遠近感が出ます。さらに、遠くのものがぼやけて見え、近くのものがはっきり見えることで遠近感を感じることもあります。絵画では空気遠近法(大気遠近法)と呼ばれます。
もちろんそれ以前に、遠くの物体が近くの物体の陰になって見えないという「遮蔽」も、当然ですが遠近感を生み出します。
| 斜塔の錯視 |
以上のように脳はさまざまな方法で遠近感を知覚していますが、これらの中で、平行線による遠近法に関連してで起こる脳の錯覚が「斜塔の錯視」です。

|
ピサの斜塔 |
(本書より) |
この画像はイタリアの有名な「ピサの斜塔」で、下から斜塔を見上げて撮影したものです。従って画像の上の方がより遠くにあると認識されます。斜塔の2つの側面は実世界では平行ですが、写真では遠くになるにつれて狭く見える。これはストレートな遠近法による奥行きの知覚です。
しかしこの写真を2枚左右に並べると、右の写真の斜塔がより右に傾いて見えます。明らかに錯視です。なぜそうなるのかと言うと、左右の斜塔が画面上で平行だからです。斜塔の右側の線も左側の線も、同一の写真なのだから2枚で平行なのはあたりまえです。一方で脳は、写真の上の方が遠くにあると認識している。ということは、遠くになるほど2つ斜塔は広がっていないと画面上で平行にならない。このため、右の斜塔が左の斜塔よりも右の方に傾いて見えるわけです。

|
斜塔の錯視 |
全く写真を2枚左右に並べると、右の写真の斜塔がより右に傾いて見える。本書より。 |
この錯視は「ピサの斜塔」の写真を用いて初めて発表されたので「斜塔の錯視」と呼ばれていますが、斜塔でなくても起こります。次の画像は線路の写真での例です。線路によって人間の眼は左上に向かって遠くになっていると強く認識します。そのため、左の写真の線路と右の写真の線路は斜めの角度が違って見えます。右の写真の線路の傾きがよりゆるく見える。

|
斜塔の錯視 (線路の写真での例) |
2枚の写真の線路は同じ傾きであるが、そうだとは絶対に見えない。本書より。 |
この線路の写真は、地面上の2本の平行線が左右にありますが、平行線は上下にあっても斜塔の錯視が起こります。本書にはありませんが、次の図は No.112、No.123 に画像を掲載した古代ローマの水道橋、ポン・デュ・ガール(フランス)です。遠近感がはっきりした写真を上下に並べると、水道橋の傾きが違って見えます。

|
斜塔の錯視 (ポン・デュ・ガールの例) |
斜塔の錯視は「遠近感がない」と認識できる絵や写真では起こりません。次の絵は本書に掲げられているものですが、2人の女の子は同一の角度で傾いています。

|
奥行き感がないイラスト画 |
女の子の「赤い服らしきもの」は左上に向かって狭まっているが、曲線が含まれていて平行線ではない。また、狭まった先にあるのは顔であり、これでは奥行きは感じない。従って2枚を並べても「斜塔の錯視」は起こらない。本書より。 |
斜塔の錯視でわかるのは、2次元平面(絵画、写真、イラストなど)の遠近感は、平行線による遠近法の効果が強烈であることです。実世界において平行と想定できる2つの線が次第に狭くなっていくと奥行きを強く感じる。もちろん画家は、これを最大限に活用して3次元空間を絵の中に閉じこめてきたわけです。それは消失点が1つの「1点透視」による遠近法でなくてもかまわない。No.243「視覚心理学が明かす名画の秘密」に "1点に収斂しない透視図法" の例として、フェルメール『牛乳を注ぐ女』とデ・キリコ『街の神秘と憂鬱』を引用しました。
以上、視覚は脳の情報処理であることを例とともにあげましたが、以降は本書に示されている「視覚と絵画」に関係したトピックを4つだけ紹介します。
輝度の秘密:モネ
下の画像はモネの『印象・日の出』(1872。パリのマルモッタン美術館蔵)です。ルアーブルの港の風景を描いたこの絵は、印象派の名前の由来になった絵で、誰もが知っている超有名絵画です。この絵画にはある秘密があります。
|

|
モネ「印象・日の出」 |
カラー画像とグレイスケール画像を対比させたもの。グレイスケール画像では太陽とその海面への反映が判別しづらくなる。本書より。 |
引用で「太陽があたかも現れたり消えたりするように見える」とあります。もちろん絵の全体を眺めているときは「現れたり消えたりする」ことはないでしょう。しかし、この絵の左下にあるモネのサインのあたりを中心視でじっと見つめると、周辺視している太陽が消えてしまうように感じないでしょうか。
一般的に言って「輝度が同じものは、やや判別しにくい」(本書)のです。この絵は「日の出」というタイトルどおり太陽がアクセントになっています。しかし "全体に漂うボーッとして混沌とした雰囲気" を作り出している一つの要因が「太陽と朝の空が同じ輝度」ということでしょう。
ピカソの色拡散
"色拡散" とは聞き慣れない言葉ですが、色が本来あるべき形をはみ出し、滲み出して、周りに拡散している状況を言っています。次のピカソの絵について、本書では次のように解説されています。
|

|
パブロ・ピカソ(1881-1973) 「母と子」(1922) |
(ボルチモア美術館) |
この絵は「形」がいろいろと省略されていると同時に、子どもの足が典型ですが、形が単純化されています。しかし省略や単純化をしても、我々の視覚は本来あるべき線を補い、本来の形を想像して受け取ります。絵画ではよくあることです。
それに加えてこの絵の特徴は、形に付随しているはずの色が、形から滲み出し、はみ出し、あたりにボーッと広がっている(拡散している)ことです。こうなっても我々の視覚は全く違和感を感じません。解説にあるように、形にちゃんと色を割り当てて見ているのです。
これは水彩画によくある手法ですが、ピカソのこの絵は油絵です。油絵ではあるが、水彩のような淡い色調が使ってある。それが "色拡散" で違和感を感じない原因の一つになっているのでしょう。
しかしこの絵は単に「水彩の技法で描いた油絵」ではありません。"色拡散" で描くことによって「母が子を優しく包み込んでいる感じ」や「母と子が融合して一体化している感じ」がよく出ています。画家が表現したかった精神性と使った絵画手法が不可分にマッチしているところが、この作品の価値だと思います。
デュフィの色拡散
「本書」では色拡散の例としてピカソの作品があげてありますが、そもそも色拡散を多用して作品を作ったのはラウル・デュフィ(1877-1953)です。三浦佳世氏の「視覚心理学が明かす名画の秘密」(No.243)にその解説があるので、それを引用します。下線は原文にはありません。漢数字を算用数字にしたところと、ルビを追加したところがあります。
|
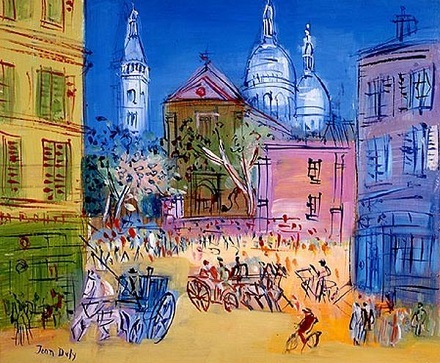
|
ラウル・デュフィ(1877-1953) 「モンマルトルのサン・ピエール教会とサクレクール寺院」 |
(個人蔵) |
デュフィの絵の全部を「色拡散」という言葉でくくってしまうのは不適切なのかもしれません。"拡散" というと、形の中に閉じ込められていた色が周りに滲みだし、はみ出て広がっていくイメージです。ところが上の作品などは「色に形を添えた」絵に見えるわけです。
さらに三浦氏は脳神経科学の知見をもとに「形」と「色」と「動き」を認識する脳の不思議なメカニズムに言及しています。
|
我々はデュフィやピカソの "色拡散" の絵を見ても違和感を全く感じないのですが、それは "意外にも" 脳の働き方とマッチしているからなのでしょう。
顔を認識する脳の働き
「本書」に戻ります。イタリア出身でウィーンで活躍したジュゼッペ・アルチンボルドは、果物、野菜、動植物などを寄せ集めた肖像画を描いたことで有名です。
|

|
ジュゼッペ・アルチンボルド(1527~1593) 「庭師」 |
(クレモナ市立 アラ・ポンツォーネ美術館) |
この絵は「ボウルの野菜、あるいは庭師」と呼ばれることもある。クレモナの美術館では「野菜」の見え方で壁に展示し、その下に鏡を置いて「庭師」が分かるようにしてある。 |
人間の眼は顔の認識に特に敏感で、顔ではないものにも顔を見つけようとします。よく "人面魚" などの「動物の模様が顔に見える」のが話題になったりします。いわゆる "心霊写真" もそうだし、月や火星のクレーターの写真が顔に見えることもある。「私たちの脳が、わずかなデータに基づいて顔の造作と表情を検知し、認識し、見分けるようにできている」と引用にありますが、まさにその通りで、それこそが人間の社会生活にとって必須の能力だからでしょう。
モナリザの微笑みの秘密

|
レオナルド・ダ・ヴィンチ(1452-1519) 「モナ・リザ」(11503-1519頃) |
(ルーブル美術館) |
本書には "世界で一番有名な絵" である、ルーブル美術館の『モナ・リザ』についての解説もありました。モナ・リザの「謎の微笑」についての神経科学からの説明です。微笑んでいるのか、いないのか、そのはざまにあるような微妙な表情ですが、次のように解説してあります。
|
要約すると、
モナリザの口もとを中心視でみると微笑みは微かだが、周辺視で見ると明らかに微笑んでいるように見える
ということでしょう。本書には参考のために次の図が提示してあります。これは周辺視を疑似する目的でモナ・リザを画像処理でぼかしたものです。右が視野の周辺での見え方で、左が視野の端の方での見え方に相当します。視野の端に行くにつれて、我々はより微笑んでいるように感じている。これが「謎の微笑」を生み出しているという分析でした。

|
モナリザをぼかした画像 |
右の画像は視野の周辺で見たモナリザを模擬した画像。左の画像は視野の端で見たモナリザを模擬している。視野の周辺から端に行くにつれてモナリザはより微笑んでいるように見える。本書より。 |
モナリザが "世界で一番有名な絵" になった理由は、まさに「謎めいた表情」だと思います。その「謎」に人々は引き込まれる。この「謎」を作り出している絵画技法が、スフマートというのでしょうか、絵の具の薄い層を幾重ともなく塗り重ねて、全く境目がない色と輝度の変化を作り出したことでしょう。ダ・ヴィンチの天才が神経科学の面からも裏付けられたということだと思います。
2020-01-26 15:16
nice!(0)
No.276 - AIの "知能" は人間とは違う [科学]
いままで合計16回書いたAI(人工知能)についての記事の続きです。まず、No.196「東ロボにみるAIの可能性と限界」を振り返るところから始めます。No.196 で紹介した「ロボットは東大に入れるか」プロジェクト(略称:東ロボ)の結論は、
というものでした(MARCH = 明治、青山学院、立教、中央、法政。関関同立 = 関西、関西学院、同志社、立命館)。つまりこのプロジェクトは「AIの可能性と限界を実証的に示したもの」と言えるでしょう。あくまで大学入試という限られた範囲です。しかし大学入試は10代後半の人間の知的活動の成果を試す重要な場であり、その結果で人生が左右されることもあるわけです。"人工知能" の実力を試すにはうってつけのテーマだったと思います。
では、なぜ東大合格は無理なのか。それは東ロボくんには得意科目もあるが、不得意科目があるからです。たとえば数学では、東大理科3類を受験する子なみの偏差値を出しました。しかし不得意もあって、その典型が英語のリスニング、「バースデーケーキの問題」でした(No.196 の「補記」参照)。この問題において東ロボくんは、英語を聞くことは完璧にできました(=音声認識技術)。しかし質問が「できあがったケーキはどれか、4つのイラストから選びなさい」だったため、そこが全くできなかった。国立情報学研究所の方の「絶対に無理」とのコメントがありました。「今のAIの方法論では今後とも絶対に無理」の意味です。要するに No.196 の「バースデーケーキ問題は」、
の複合問題であり、東ロボくんは ① が完璧、② が手も足も出ないという状況だったわけです。AIの可能性と限界を示す象徴的な例です。
そこで次の段階として、疑問が出てきます。
という疑問です。AIを "人工知能" と言うなら、その "知能" は "人間の知能" と似たようなものか、あるいは異質なものなのか ・・・・・・。
No.196 で東ロボ・プロジェクトのリーダの新井教授は「AIは意味を理解しない」と言っていました。人間が無意識にやっている「意味を理解する」とは非常に広範囲なことですが、たとえば、ある内容の記述を読んだり、発言を聞いたりしたときに、
などでしょう。もっとあると思います。もちろんその全部ではないでしょうが、人は多かれ少なかれ、そういうことを暗黙に想定しつつ記述を読み、発言を聞き、コミュニケーションをしています。意味を理解することこそ人間の価値であり、逆に言うと「意味を理解しないで過ごしているばかりだと、いずれ AI に取って代わられる」という警告でした。
では、「AIは意味を理解しない」こと以外に、AIの "知能" が人間と違うところはあるのでしょうか。そのことについて、理化学研究所・上級研究員の瀧 雅人氏が最近の雑誌に大変わかりやすい解説を書かれていましたので、是非、それを紹介したいと思います。「騙されるAI」(日経サイエンス 2020年1月号)という記事で、「騙す・騙される」という切り口から人間とAIの相違、人間にとってのAIの意味を明らかにしたものです。
以降の話は、AIに使われる各種の手法(ないしは数学モデル、アルゴリズム)のうち、ディープラーニングに話を絞ります。ディープラーニングは、2010年代の「AIブーム」の火付け役となったものです。まず、瀧 雅人氏の解説を紹介する前に、ディープラーニングの概要を振り返ってみたいと思います。各種メディアで大量に流されている情報ですが、あとの瀧氏の解説に関係する部分を要約します。
深層学習(ディープラーニング)の発展
AIに使われる手法は各種ありますが、現在のAIのブレークのきっかけになったのは深層学習(ディープラーニング)の実用化に成功したことでした。この技術革新をもたらしたのが、業界では "カナディアン・マフィア" と呼ばれるモントリオール大学教授のヨシュア・ベンジオ、トロント大学名誉教授のジェフリー・ヒントン、現フェイスブックのチーフAIサイエンティストのヤン・ルカンでした。彼らは "AIの冬の時代" にも地道に研究を重ね、ディープラーニングに関する数々の技術的困難を克服してきました。
【画像認識】 業界が衝撃を受けたのは2012年のILSVRC(Image-net Large-scale Visual Recognition Challenge)です。これは与えられた画像に何が写っているかを1000種の中から答えるというものです(= 一般物体認識)。このコンテストに参加したトロント大学のヒントン教授のチームは、ディープラーニングを使い、それまでの誤認識率を一挙に10ポイントも改善する 16% という値を達成しました。それまでは数年で1~2%の改善だったことを思うと、これは革新的です。その後も精度は急激に向上し、2015年あたりでは 5% 程度にまで低下しました。これは人間の画像認識能力の平均値を越えています。
【音声認識】 画像認識とともにディープラーニングの成果が最初に現れたのは音声認識です。これについては瀧 雅人氏の解説を引用します。
【自動翻訳】 ディープラーニングが発展したもう一つが自然言語処理(Natural Language Processing。NLP)の分野で、その典型的な例は自動翻訳です。自動翻訳にディープラーニングを取り入れたのはグーグル翻訳が最初ですが、その精度は年々向上し、多くの自動翻訳システムがディープラーニングを取り入れるようになりました。
【読解力】 その自動翻訳のための基礎技術の一つが読解力です。No.234「教科書が読めない子どもたち」で、国立情報学研究所の新井教授が主導した RST(Reading Skill Test)を紹介しましたが、RSTは読解力(基礎的読解力)判定するものです。RSTは基礎的読解力を「係り受け」「照応解決」「同義文判定」「推論」「イメージ同定」「具体例同定」にわけて測定するものですが、「推論」「イメージ同定」「具体例同定」の3つはまだまだAIにとって困難な問題です。しかし「係り受け」「照応解決」についてはAIが好成績をあげています。
読解力をテストするベンチマーク問題に SQuAD(Stanford Question and Answer Dataset)があります。これはスタンフォード大学が整備しているデータベースで、Wikipediaの例文をもとに、例文に関する質問と答(すべて英文のテキスト)が集積されています。RSTの基礎的読解力で言うと「係り受け」と「照応解決」に相当しますが、ある程度の「推論」が必要な問題もあるようです。
2018年1月、マイクロソフト・リサーチのディープラーニング・システムが、SQuADのベンチマークで(その当時の)人間の平均値(82.3点)を初めて上回りました。その後、2019年に至って90点に迫るディープラーニング・システムも出現しています。あくまで基礎的読解力の一部の範囲ですが、AIはそういう実力だということです。
以上の画像認識、音声認識、自動翻訳だけでなく、ディープラーニングは多くの分野で突出した成果をあげています。それは商用だけでなく、医療、創薬、新素材開発、天文学などの研究開発分野にも広がっています。
ディープラーニングは説明可能ではない
ディープラーニングで重要なことは、問題から正解を導く方法や筋道、アルゴリズムを人間が教えたのではないことです。あくまで「問題と正解のデータ」を大量に集め、それをディープラーニングを実装したコンピュータ・システムに学習させたものです。
ここから言えることは、ディープラーニングが答えを出したとしても、なぜそうなるのかの理由が説明できないということです。その例として、No.180「アルファ碁の着手決定ロジック」で取り上げた英国・ディープマインド社のアルファ碁(=2015年末当時のアルファ碁)で言いますと、policy newtwork によって碁のエキスパートが次に打つだろう点の確率を計算し、A点が 0.6、その1路横のB点が 0.2 になったとき、なぜA点の方が有力かの説明をアルファ碁はしないわけです。人間ならたとえば「B点は相手の厚みに近寄り過ぎているので、ここは1路控えたA点が正解」というように理由を説明するわけです。さらには「敗勢なら一歩踏み込んだB点で勝負をかけるのもありだが、今は状勢が拮抗しているのでA点に打つべき」と付け加えるかも知れません。そういった「説明」がAIはできない。
これは、ディープラーニングはブラックボックスだから、というのではありません。アルファ碁のアーキテクチャは明確であり、そこでどういうパラメータが使われているのか、(アルファ碁の開発者なら)調べようと思えばいくらでも調べられるからです。しかしアルファ碁のパラメータは No.180 で試算したように約388万個もあります。それがどのように影響し合って答えを導くのか、膨大すぎて人間には理解しがたいのです。
要するにディープラーニングは「なぜだか明確には説明できないが、答は結構正確」なのです。もちろんそれで有益な場合があることは確かです。人間が思いつかないような(ないしは見落としているような)答を出し、それを人間が検証して有効活用できればよい。しかしこのままでは真に重要な決定をディープラーニングに任せてしまうことはできません。この点を克服するため、現在「説明可能なAI」が世界の研究者の間でのホットな研究テーマになっています。
ディープラーニングを騙す
以上のことを踏まえて、瀧 雅人氏の「騙されるAI」(日経サイエンス 2020年1月号)を見ていきたいと思います。ディープラーニングがブレイクするきっかけとなった画像認識(一般物体認識)の話です。
瀧氏の解説ではまず、一般物体認識を行うディープラーニングを "騙せる" ことが述べられています。意図的に作ったデータでディープラーニングを騙すことを「敵対的攻撃」と言い、騙されたデータを「敵対的事例」と言います。瀧氏はそれを、自ら中国で撮影したパンダの画像とオックスフォード大学が開発したディープラーニングでやってみました。
まず、元の画像をディープラーニングに入力すると「パンダである確率が99.997%」が出力されました。これは妥当な結果です。
次に、元の画像にディープラーニングを騙す目的で作った「敵対的ノイズ」を薄くかぶせると「81.576%の確率で雄羊」と判断されました(敵対的事例 ①)。
さらに、画像の一部に別の画像を張り付けても「89.445%の確率で雄羊」と判断しました(敵対的事例 ②)。
画像全体の色調を変化させるという敵対的攻撃もあります。この例では「51.0706%の確率でテディベア」と判断するようになりました(敵対的事例 ③)。
もし人間が「敵対的事例 ① ② ③」の画像を見たとしたら、たとえ保育園児であっても全員が口をそろえて「パンダ!!」と答えるに違いありません。ここから類推できることは、
ということです。保育園児でも簡単に答えられることに間違ってしまうのだから ・・・・・・。
ディープラーニングは、いかにも人間がモノを認識しているように認識するように見えます。しかも人間より優れている面も多いわけです。たとえば自動車の運転を考えると、人間が 0.1 秒で障害物を認識できたとして、ディープラーニングが 0.01 秒だと、この差は事故回避行動の観点からクリティカルになるでしょう。さらにディープラーニングは疲れないし、意識レベルが下がることもないし、意識が一瞬飛ぶこともない。この技術を今後の社会に有効に活用しない手はないのです。
しかし、ディープラーニングはどうも人間が認識しているように認識しているのではなさそうです。このことが悪影響を及ぼさないのか、何らかの副作用につながらないのか。ディープラーニングは結構正確だが突如誤った答えを出さないのか。この点をよく研究しておく必要があるわけです。
騙す方法
どうすれば敵対的攻撃でディープラーニングを騙せるのでしょうか。瀧氏の解説では一般物体認識を例に「騙す方法」の簡単な例が書かれています。
今、画像のサイズを 100 × 100 ピクセル、合計 10,000 ピクセルの白黒画像だとします。各ピクセルは、たとえば 0(白)~255(黒)の256階調の値が指定されているわけです。ここにパンダの顔の画像があり、この画像はディープラーニングで 99.9% の確率で「パンダ」と判定されるとします。
この画像にノイズを加えます。このノイズは 100 × 100 ピクセルで、各ピクセルは +3 か -3 のどちらかです。このノイズを元の画像に足し合わせるわけです(もちろん 0~255 の範囲に収めるような補正が必要)。この程度のノイズを加えても人間の眼にとっては元の画像と全く区別がつきません。このノイズの中で「ディープラーニングがパンダとかけ離れた判定をするノイズ」を探索するというのが眼目です。
ノイズは10,000 の各ピクセルが +3 か -3 のどちらかの値をとります。従ってノイズのパターンは 210000 種類あり、これは3,000桁を越える超天文学的に巨大な数です。全部のパターンを調べるのは到底不可能です。しかし敵対的攻撃をするためには、全部のパターンを調べる必要は全くありません。瀧氏は次のように解説しています。
つまり、数学的に言うと大変にシンプルなやり方で敵対的攻撃ができることになります。
しかし、FGSMは「出力が一番おかしな方向にずれていくようなノイズを、微分法を利用して近似的に計算」するものであり、このためにはディープラーニングの内部構造とパラメータを知らなければなりません。内部を知った上の攻撃という意味で、このような攻撃を「ホワイトボックス攻撃」と呼んでいます。
「ホワイトボックス攻撃」を防ぐためには、ディープラーニングの内部構造を隠してしまい、入力・出力のインターフェース仕様(API。Application Program Interface)だけを公開すればよいわけです。グーグルや日本のプリファード・ネットワークスが一般公開しているディープラーニングは APIの公開方式になっています。しかしこれでも騙せるのです。
もちろん、攻撃をかわすための防御アルゴリズムも研究されています。たとえば敵対的事例も含めて予測できるように学習するという「敵対的学習」です。こうすることによって、あらかじめ学習させた敵対的事例については間違いが起こらなくなります。
しかし敵対的学習を行ったあとのディープラーニングに対して、新たな敵対的攻撃アルゴリズムを使ってノイズを生成することは可能であり、新たな敵対的事例ができることになります。新手の敵対的事例では再び間違いが起こる。
その他、数々の防御アルゴリズムが開発されていますが、それぞれに対する攻撃手法もまた開発されています。要するに「いたちごっこ」であり、現時点では完璧な防御策はありません。現在、世界の研究者がより幅広い攻撃を効果的に防ぐことができるアルゴリズムを探求しているところです。
騙される理由が分からない
なぜディープラーニングは騙されてしまうのでしょうか。これについて瀧氏は次のように書いています。
ディープラーニングついて「動作メカニズムがわかっていないにもかかわらず敵対的事例が作れてしまう」ことは、実は「動作メカニズムがわかっていないにもかかわらず結構正しい答を出す」ことの裏返しの関係にあるのですね。
上の引用にあるように、騙される理由はわかっていないのが現状です。ただし、確定的なことは言えないけれども「次元の呪い」が関係しているというのが多くの研究者の共通認識です。
次元の呪い
「次元の呪い」とは、高次元空間で我々の幾何学的な直感が破綻する現象を指します。これを瀧氏は以下のように説明しています。
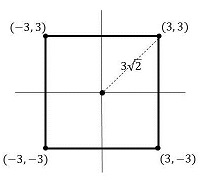
まず2次元の場合で、1辺の長さが6の正方形を考えます。座標上に描いたのが右図です。正方形の中心から頂点までの距離はピタゴラスの定理より
(2次元) 3√2 = 4.24
となります。次に3次元の立方体(1辺の長さが6)を考えると、立方体の中心から頂点までの距離は、直角を挟む2辺の長さが 3√2 と 3 の直角三角形の斜辺の長さなので、
(3次元) 3√3 = 5.20
となります。つまり、2次元の場合より距離が少し長くなります。座標で計算すると、3次元の場合、8つの頂点の座標は(±3, ±3, ±3)なので、原点である (0, 0, 0) との距離は 32 * 3 の平方根であり、3√3 となるわけです。
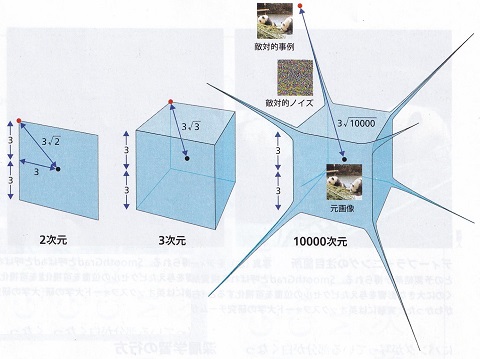
これを拡張し、高次元空間(N 次元)の1辺6の超立方体ではどうなるでしょうか。図形的には計算できないので座標で考えると、3次元の場合を拡張し、中心と頂点の距離は 32 * N の平方根となります。つまり、
(N次元) 3√N
です。もし N = 10000 だとすると、距離は
(10000次元) 3√10000 = 300
となります。低次元では中心からそう遠くない距離にあった頂点が、高次元では格段に遠くなってしまう。これが典型的な「次元の呪い」です。この「次元の呪い」によって敵対的ノイズが結果に大きく影響すると考えられているのです。
ディープラーニングは人間の思考とは違う
ディープラーニングが騙される本質的な理由は現状では解明されていません。しかし、理由はともかくここから分かることは、どうもディープラーニングは人間とは違うようだ、ということです。
ディープラーニングは人間とは別の方法で認識し、理解していて、その認識方法・理解方法が解明されていない。このことはディープラーニングの社会応用に深刻な障害となります。これを瀧氏は、
という "寓話" で説明しています。卓抜な比喩だと思ったので、次に紹介します。
ディープラーニングで惑星の運動を予測する
天動説と地動説に関する歴史の振り返りです。コぺルニクス以前の天動説では、地球が中心にあり、その周りを太陽と惑星が回っているという宇宙像でした。もちろん、惑星の位置を詳しく観測すると単純に回っているのではない結果が得られます。つまり惑星は天球上を立ち止まったり、バックしたり、再び方向を変えて進むというような不規則な運動をするのです(惑星の "惑" とはそういう意味です)。
天動説では、この惑星の不規則な運動を「周転円」で説明していました。つまり惑星はそれ自身がある中心の周りを回っており、その中心が地球の周りを回っているという説明です(これ以外にも人為的な仮説がいろいろある)。
これに対してコペルニクスは、地球を含む惑星が太陽の周りを回っているという地動説を唱えました。これによって惑星の不規則な動きを説明したのです。ただしコペルニクスは惑星の軌道を円と考えていたため、その説明には限界がありました。
それを解決したのがケプラーです。ケプラーは精密な観測データをもとに、惑星の軌道が円ではなく楕円であることを証明しました(ケプラーの第1法則)。これによって惑星の動きは完全に説明できたのです。
さらにニュートンは万有引力の法則を発見し、2つの物体には質量に比例し距離の2乗に反比例する引力が働くことを示しました。この法則と運動方程式を組み合わせることで、惑星は太陽の周りを楕円軌道で回り、太陽は楕円の焦点にあることが数学的に証明できます。以上の、コペルニクス → ケプラー → ニュートンの発見は、科学史の偉大な成果であることは言うまでもありません。
そこでもし、現代においても地動説が確立していず、惑星の運動の予測にディープラーニングを使ったらどうなるかです。もちろん、過去の惑星の「時刻・位置データ」が膨大に蓄積されているという前提です。これをディープラーニングに学習させ、そして直近の惑星の運動を入力して今後の運動を予測する。
これは画像認識のためのディープラーニングとは種類が違います。時系列の数値データを入力し、そこから予測をしたり、傾向を把握したりするタイプのディープラーニングです。現代では音声認識、株価の予測、機械の動作状況からの異常検知などに使われています。このディープラーニングで惑星の運動を予測したらどうなるか。
惑星の軌道を精緻に予測するディープラーニングの中身をいくら調べてみても「惑星は太陽の周りを楕円軌道で公転する」という知見は得られないでしょう。コペルニクス以前の学者のように「周転円」のような人為的な仮説を満載した天動説で強引に計算しているだけかもしれないのです。
AIと人間の共存
以上のようなディープラーニングの現状を踏まえて、瀧氏は次のように総括しています。
上の引用に出てくる「オッカムの剃刀」とは、「あることを説明するためには、必要以上に多くの仮定をすべきでない」という指針ですね。オッカムは中世ヨーロッパの哲学者の名前、剃刀とは説明に不要なものを切り落とすことの比喩です。
シンプルな原理によって全てを説明するというのが科学の立場(ないしは野望)ですが、ディープラーニングはそれとは違う立場の科学の発展の可能性がある、というが瀧氏の予感です。あくまで、そういう可能性も考えられるということなのですが、これがディープラーニングがもつ重要な意味でしょう。
AIは人間の知能を上回る?
以下は瀧氏の解説を読んだ感想です。
よく「20XX年にはAIの知能が人間を上回る」というようなことを言う人がいます。しかし、この手の発言がどのような実証的研究に基づいてなされているのか、はなはだ不明です。人を驚かせようとする無責任な発言に思える。
こういうこと言うためには、最低限、① 人間の知能とはなにか、それはどういう原理やプロセスで生み出されるのか、② AIの知能とは何か、それが生み出されるプロセスは人間と同じなのか、それとも違っているのか、という2点の説明がなければなりません。
しかし現時点において、① の人間の知能が解明されているわけでは全くありません。また ② の(現在における)AIの知能は瀧氏が解説しているように、人間の知能とは別種のものである可能性が極めて高いわけです。「人間とは別種のものが人間を追い越す」というは奇妙な言説です。
もちろん特定のエリアでは、AIの方が人間より遙かに速く、正確に答えを出すことがあるでしょう。しかしそれは、たとえて言うと「走るスピードではクルマが人間を追い越す」というのに近い。クルマが走る原理は人間と全く違います。人間はそのスピードを最大限に利用して現代生活が成り立っている。もちろんクルマに頼り過ぎると運動不足に陥り、生活習慣病を発症したりしてまずいことになるわけで、その配慮が必要なことは言うまでもありません。同様のことはAIについても言えるでしょう。
瀧氏の文章は、ディープラーニングという範囲でAIと人間の違いを明らかにしたよい解説だと思いました。ディープラーニングの本質を見極める基礎研究や、ディープラーニングの答の理由を「説明可能にする」研究によって、人間のAIとのつきあい方が決まっていくし、人間とAIの共存方法が見えてくるのだと思いました。
この記事の本文で、米国のスタンフォード大学が AIのベンチマークのために作成している SQuAD(The Stanford Question Answering Dataset)のことを書きました。これは「例文・質問・回答データベース」です。まず例文があり、それについての質問と回答が複数あります。すべて英文のテキストデータです。回答の中には "No Answer"、つまり答えがない(=例文の情報だけでは答えられない)ものもあります。
この SQuAD がどういうものか、その問題例を以下に掲載します。最新の「SQuAD 2.0」の問題の一つで、ライン河に関するものです(2020.1. 現在。https://rajpurkar.github.io/SQuAD-explorer/)。単位系の記述を分かりやすいように修正しました。
自然言語処理を行うAIシステムとしては、質問1では北海(the North Sea)とオランダ(the Netherlands)の関係を把握しなければなりません。また質問2では「after the Danube」という記述をもとに、ライン河より長いのがドナウ河と判断する必要があります。
なお、この例文には12の質問が設定されていますが、そのうちの5つは「No Answer」が正解です。
この記事の本文で、AIが不得意な大学入試問題の典型が「英語のリスニングの結果をイラストの選択で答える」ものだとしました。その実際の問題を掲げます。2019年度 センター本試験、英語リスニング問題の「第1問 問1」です。
羽の生えた野菜を選べばよいので、正解は言うまでもなく ② です。受験生としては、ICレコーダから流れる英語音声を聞き取ることさえできれば(特に vegetable と wings)間違えようのない問題です。
一方、AIはどうかと言うと、英語音声をリスニング台本と質問文に変換するのは容易です。全く雑音がない環境での明瞭な英語なので、この程度の音声認識は現代のAI技術では完璧にできるのです(でないとAIスピーカなど実用化できません)。
しかしそのあとが無理です。これをディープラーニングで回答しようとすると「羽の生えた野菜」含むイラストデータを大量に用意し、それを学習しなければなりません。しかし、そんなイラストの学習データを大量に用意できるはずがないのです。
もちろんセンター試験の受験生にとっても「羽の生えた野菜」のイラストを見るのは生まれて初めてでしょう。全く初めてではないかもしれませんが、過去に(絵本などで)似たイラストを見たことなど忘れているはずで、「生まれて初めて」と同じことです。生まれて初めてではあるが、リスニングができた受験生は間違えることなく答えられるのです。
AIにとって「羽の生えた野菜」を識別するのが困難なら、では「野菜」と「羽」を識別してそれが含まれるイラストを答えたらどうか。しかし、これも難しいでしょう。「野菜」にはたくさんの種類があります。「野菜」か「野菜でない(たとえば果物)」を識別するのが簡単とは思えない。しかも、実物の画像ではなくイラストです。イラストはイラストレーターがモノの特徴をとらえて(ある場合はデフォルメをして)恣意的に描くものです。たとえイラストを大量に集めたとしても有効なディープラーニングの学習はできないでしょう。しかもセンター試験の問題にあるように、ニンジンに目・鼻・口・手・足があってもそれはなおかつニンジンなのであり、そんな "高度な" 認識がAIで簡単に行くとは思えません。
100歩譲って「野菜」と「羽」のイラストを認識できるディープラーニングができたとしましょう。しかし苦労してそんなものを作ったとしても使い道がありません。なぜなら、センター試験に「羽の生えた野菜」が出るのは2019年度の1回きりだからです。次年度は「足の生えた飛行機」かもしれないし、そもそもマンガのキャラクターに関する会話がリスニングに出るのはこれっきりかもしれません(いや、センター試験なので "これっきり" のはずです)。
世の中に絶対に存在しないもののイラストは無限に考えられます。しかし受験生は常識推論でそれを理解します。常識推論で簡単に答えられるからこそ出題されるのであって、常識で簡単に答えられないようだとリスニング能力をテストするという主旨から逸脱してしまうのです。
センター試験の受験生が100%できることが、現代のAI技術では全く歯が立たない。そういう例なのでした。
本文中にディープラーニングを使った画像認識を騙せることを書きましたが、同様の原理で音声認識も騙せるようです。アマゾンの「エコー」やグーグルの「グーグル・ホーム」は、ネットに繋がった音声認識技術によって人間の指示を理解し、サービスを提供します。筑波大学の佐久間淳教授(=理化学研究所・人工知能セキュリティ・プライバシーチーム リーダー)は社会に警鐘を鳴らすため、スマートスピーカーを騙す実験を行いました。
この記事を読んでまず思ったのは、佐久間教授はクラシック音楽好きだということです。あるいは、人間の耳はチェロの音が最もノイズを判別しにくいということを試行から決めたのかもしれません。
それはともかく、この実験から直ちに「エコー」や「グーグル・ホーム」を騙せるということにはなりません。商用化されているスマートスピーカーは、ディープラーニングの内部構造が公開されていないからです。しかし最近のAI研究では、内部構造を知らなくても敵対的攻撃が可能な手法(=ブラックボックス攻撃)が開発されています。「警鐘を鳴らす」ための実験としては、大いに意味があると思いました。
そしてこの件もまた画像認識と同様、音声を認識するAIの "知能" が人間の知能とは違うことを示しているのでした。
| 東ロボくんは、"MARCH"、"関関同立" の特定学部に合格できるレベル | |
| ただし、東大合格は無理 |
というものでした(MARCH = 明治、青山学院、立教、中央、法政。関関同立 = 関西、関西学院、同志社、立命館)。つまりこのプロジェクトは「AIの可能性と限界を実証的に示したもの」と言えるでしょう。あくまで大学入試という限られた範囲です。しかし大学入試は10代後半の人間の知的活動の成果を試す重要な場であり、その結果で人生が左右されることもあるわけです。"人工知能" の実力を試すにはうってつけのテーマだったと思います。
では、なぜ東大合格は無理なのか。それは東ロボくんには得意科目もあるが、不得意科目があるからです。たとえば数学では、東大理科3類を受験する子なみの偏差値を出しました。しかし不得意もあって、その典型が英語のリスニング、「バースデーケーキの問題」でした(No.196 の「補記」参照)。この問題において東ロボくんは、英語を聞くことは完璧にできました(=音声認識技術)。しかし質問が「できあがったケーキはどれか、4つのイラストから選びなさい」だったため、そこが全くできなかった。国立情報学研究所の方の「絶対に無理」とのコメントがありました。「今のAIの方法論では今後とも絶対に無理」の意味です。要するに No.196 の「バースデーケーキ問題は」、
| 英語のリスニング | |
| イラストを見て答える常識推論 |
の複合問題であり、東ロボくんは ① が完璧、② が手も足も出ないという状況だったわけです。AIの可能性と限界を示す象徴的な例です。
そこで次の段階として、疑問が出てきます。
AIが人間と同等にできる、あるいは人間以上にできることについて、AIと人間の違いがあるのか、あるとしたらそれは何か
という疑問です。AIを "人工知能" と言うなら、その "知能" は "人間の知能" と似たようなものか、あるいは異質なものなのか ・・・・・・。
No.196 で東ロボ・プロジェクトのリーダの新井教授は「AIは意味を理解しない」と言っていました。人間が無意識にやっている「意味を理解する」とは非常に広範囲なことですが、たとえば、ある内容の記述を読んだり、発言を聞いたりしたときに、
| 何を言っているのかが理解できることを前提として | |
| その記述や発言に至った理由や背景、意図、目的が理解できる。 | |
| 内容の価値判断ができる。重要か、自分に関係あるか、一般的なことか、意義があるのか、本当のことか、正しいことか、応用できるか ・・・・・ 等々。 |
などでしょう。もっとあると思います。もちろんその全部ではないでしょうが、人は多かれ少なかれ、そういうことを暗黙に想定しつつ記述を読み、発言を聞き、コミュニケーションをしています。意味を理解することこそ人間の価値であり、逆に言うと「意味を理解しないで過ごしているばかりだと、いずれ AI に取って代わられる」という警告でした。
では、「AIは意味を理解しない」こと以外に、AIの "知能" が人間と違うところはあるのでしょうか。そのことについて、理化学研究所・上級研究員の瀧 雅人氏が最近の雑誌に大変わかりやすい解説を書かれていましたので、是非、それを紹介したいと思います。「騙されるAI」(日経サイエンス 2020年1月号)という記事で、「騙す・騙される」という切り口から人間とAIの相違、人間にとってのAIの意味を明らかにしたものです。
以降の話は、AIに使われる各種の手法(ないしは数学モデル、アルゴリズム)のうち、ディープラーニングに話を絞ります。ディープラーニングは、2010年代の「AIブーム」の火付け役となったものです。まず、瀧 雅人氏の解説を紹介する前に、ディープラーニングの概要を振り返ってみたいと思います。各種メディアで大量に流されている情報ですが、あとの瀧氏の解説に関係する部分を要約します。
なお、No.180「アルファ碁の着手決定ロジック(1)」で、英国・ディープマインド社の「アルファ碁」(2015年末当時)で使われているディープラーニングの内部構造(アーキテクチャ)を解説しました。これは、画像認識によく使われる「畳み込みニューラルネットワーク(Convolutional Neural Network。CNN)」と呼ばれるタイプのものです。ただし碁のゲーム用に特化したCNNです。
深層学習(ディープラーニング)の発展
AIに使われる手法は各種ありますが、現在のAIのブレークのきっかけになったのは深層学習(ディープラーニング)の実用化に成功したことでした。この技術革新をもたらしたのが、業界では "カナディアン・マフィア" と呼ばれるモントリオール大学教授のヨシュア・ベンジオ、トロント大学名誉教授のジェフリー・ヒントン、現フェイスブックのチーフAIサイエンティストのヤン・ルカンでした。彼らは "AIの冬の時代" にも地道に研究を重ね、ディープラーニングに関する数々の技術的困難を克服してきました。
【画像認識】 業界が衝撃を受けたのは2012年のILSVRC(Image-net Large-scale Visual Recognition Challenge)です。これは与えられた画像に何が写っているかを1000種の中から答えるというものです(= 一般物体認識)。このコンテストに参加したトロント大学のヒントン教授のチームは、ディープラーニングを使い、それまでの誤認識率を一挙に10ポイントも改善する 16% という値を達成しました。それまでは数年で1~2%の改善だったことを思うと、これは革新的です。その後も精度は急激に向上し、2015年あたりでは 5% 程度にまで低下しました。これは人間の画像認識能力の平均値を越えています。
【音声認識】 画像認識とともにディープラーニングの成果が最初に現れたのは音声認識です。これについては瀧 雅人氏の解説を引用します。
|
【自動翻訳】 ディープラーニングが発展したもう一つが自然言語処理(Natural Language Processing。NLP)の分野で、その典型的な例は自動翻訳です。自動翻訳にディープラーニングを取り入れたのはグーグル翻訳が最初ですが、その精度は年々向上し、多くの自動翻訳システムがディープラーニングを取り入れるようになりました。
【読解力】 その自動翻訳のための基礎技術の一つが読解力です。No.234「教科書が読めない子どもたち」で、国立情報学研究所の新井教授が主導した RST(Reading Skill Test)を紹介しましたが、RSTは読解力(基礎的読解力)判定するものです。RSTは基礎的読解力を「係り受け」「照応解決」「同義文判定」「推論」「イメージ同定」「具体例同定」にわけて測定するものですが、「推論」「イメージ同定」「具体例同定」の3つはまだまだAIにとって困難な問題です。しかし「係り受け」「照応解決」についてはAIが好成績をあげています。
読解力をテストするベンチマーク問題に SQuAD(Stanford Question and Answer Dataset)があります。これはスタンフォード大学が整備しているデータベースで、Wikipediaの例文をもとに、例文に関する質問と答(すべて英文のテキスト)が集積されています。RSTの基礎的読解力で言うと「係り受け」と「照応解決」に相当しますが、ある程度の「推論」が必要な問題もあるようです。
2018年1月、マイクロソフト・リサーチのディープラーニング・システムが、SQuADのベンチマークで(その当時の)人間の平均値(82.3点)を初めて上回りました。その後、2019年に至って90点に迫るディープラーニング・システムも出現しています。あくまで基礎的読解力の一部の範囲ですが、AIはそういう実力だということです。
以上の画像認識、音声認識、自動翻訳だけでなく、ディープラーニングは多くの分野で突出した成果をあげています。それは商用だけでなく、医療、創薬、新素材開発、天文学などの研究開発分野にも広がっています。
ディープラーニングは説明可能ではない
ディープラーニングで重要なことは、問題から正解を導く方法や筋道、アルゴリズムを人間が教えたのではないことです。あくまで「問題と正解のデータ」を大量に集め、それをディープラーニングを実装したコンピュータ・システムに学習させたものです。
ここから言えることは、ディープラーニングが答えを出したとしても、なぜそうなるのかの理由が説明できないということです。その例として、No.180「アルファ碁の着手決定ロジック」で取り上げた英国・ディープマインド社のアルファ碁(=2015年末当時のアルファ碁)で言いますと、policy newtwork によって碁のエキスパートが次に打つだろう点の確率を計算し、A点が 0.6、その1路横のB点が 0.2 になったとき、なぜA点の方が有力かの説明をアルファ碁はしないわけです。人間ならたとえば「B点は相手の厚みに近寄り過ぎているので、ここは1路控えたA点が正解」というように理由を説明するわけです。さらには「敗勢なら一歩踏み込んだB点で勝負をかけるのもありだが、今は状勢が拮抗しているのでA点に打つべき」と付け加えるかも知れません。そういった「説明」がAIはできない。
これは、ディープラーニングはブラックボックスだから、というのではありません。アルファ碁のアーキテクチャは明確であり、そこでどういうパラメータが使われているのか、(アルファ碁の開発者なら)調べようと思えばいくらでも調べられるからです。しかしアルファ碁のパラメータは No.180 で試算したように約388万個もあります。それがどのように影響し合って答えを導くのか、膨大すぎて人間には理解しがたいのです。
要するにディープラーニングは「なぜだか明確には説明できないが、答は結構正確」なのです。もちろんそれで有益な場合があることは確かです。人間が思いつかないような(ないしは見落としているような)答を出し、それを人間が検証して有効活用できればよい。しかしこのままでは真に重要な決定をディープラーニングに任せてしまうことはできません。この点を克服するため、現在「説明可能なAI」が世界の研究者の間でのホットな研究テーマになっています。
ディープラーニングを騙す
|

瀧氏の解説ではまず、一般物体認識を行うディープラーニングを "騙せる" ことが述べられています。意図的に作ったデータでディープラーニングを騙すことを「敵対的攻撃」と言い、騙されたデータを「敵対的事例」と言います。瀧氏はそれを、自ら中国で撮影したパンダの画像とオックスフォード大学が開発したディープラーニングでやってみました。
まず、元の画像をディープラーニングに入力すると「パンダである確率が99.997%」が出力されました。これは妥当な結果です。
次に、元の画像にディープラーニングを騙す目的で作った「敵対的ノイズ」を薄くかぶせると「81.576%の確率で雄羊」と判断されました(敵対的事例 ①)。
さらに、画像の一部に別の画像を張り付けても「89.445%の確率で雄羊」と判断しました(敵対的事例 ②)。
画像全体の色調を変化させるという敵対的攻撃もあります。この例では「51.0706%の確率でテディベア」と判断するようになりました(敵対的事例 ③)。

|
元の画像 AIの判定 = パンダ(99.997%) |
(日経サイエンス 2020.1 より。以下同様) |

|
敵対的ノイズ |
敵対的事例 ① を作り出すためのノイズ。このノイズを薄く元の画像にかぶせる。 |

|
敵対的事例 ① AIの判定 = 雄羊(81.576%) |
元の画像に上の敵対的ノイズを薄くかぶせた画像。人間の目では元の画像との違いが全くわからないが、AIは高い確率で雄羊と判定した。 |

|
敵対的事例 ② AIの判定 = 雄羊(89.445%) |
画像の一部に、AIを騙す目的で作った別の画像を張り付けたもの。他の部分は元の画像と変わらないが、AIはこれも高い確率で雄羊と判定した。 |

|
敵対的事例 ③ AIの判定 = テディベア(51.0706%) |
画像全体の色調を変化させたもの。人間の目にはパンダであることに変わりがないが、AIが最も確率的に高いとしたのはテディベアであった。 |
もし人間が「敵対的事例 ① ② ③」の画像を見たとしたら、たとえ保育園児であっても全員が口をそろえて「パンダ!!」と答えるに違いありません。ここから類推できることは、
ディープラーニングは人間のように "考えて" いるのではない
ということです。保育園児でも簡単に答えられることに間違ってしまうのだから ・・・・・・。
ディープラーニングは、いかにも人間がモノを認識しているように認識するように見えます。しかも人間より優れている面も多いわけです。たとえば自動車の運転を考えると、人間が 0.1 秒で障害物を認識できたとして、ディープラーニングが 0.01 秒だと、この差は事故回避行動の観点からクリティカルになるでしょう。さらにディープラーニングは疲れないし、意識レベルが下がることもないし、意識が一瞬飛ぶこともない。この技術を今後の社会に有効に活用しない手はないのです。
しかし、ディープラーニングはどうも人間が認識しているように認識しているのではなさそうです。このことが悪影響を及ぼさないのか、何らかの副作用につながらないのか。ディープラーニングは結構正確だが突如誤った答えを出さないのか。この点をよく研究しておく必要があるわけです。
騙す方法
どうすれば敵対的攻撃でディープラーニングを騙せるのでしょうか。瀧氏の解説では一般物体認識を例に「騙す方法」の簡単な例が書かれています。
今、画像のサイズを 100 × 100 ピクセル、合計 10,000 ピクセルの白黒画像だとします。各ピクセルは、たとえば 0(白)~255(黒)の256階調の値が指定されているわけです。ここにパンダの顔の画像があり、この画像はディープラーニングで 99.9% の確率で「パンダ」と判定されるとします。
この画像にノイズを加えます。このノイズは 100 × 100 ピクセルで、各ピクセルは +3 か -3 のどちらかです。このノイズを元の画像に足し合わせるわけです(もちろん 0~255 の範囲に収めるような補正が必要)。この程度のノイズを加えても人間の眼にとっては元の画像と全く区別がつきません。このノイズの中で「ディープラーニングがパンダとかけ離れた判定をするノイズ」を探索するというのが眼目です。
ノイズは10,000 の各ピクセルが +3 か -3 のどちらかの値をとります。従ってノイズのパターンは 210000 種類あり、これは3,000桁を越える超天文学的に巨大な数です。全部のパターンを調べるのは到底不可能です。しかし敵対的攻撃をするためには、全部のパターンを調べる必要は全くありません。瀧氏は次のように解説しています。
|
つまり、数学的に言うと大変にシンプルなやり方で敵対的攻撃ができることになります。
しかし、FGSMは「出力が一番おかしな方向にずれていくようなノイズを、微分法を利用して近似的に計算」するものであり、このためにはディープラーニングの内部構造とパラメータを知らなければなりません。内部を知った上の攻撃という意味で、このような攻撃を「ホワイトボックス攻撃」と呼んでいます。
「ホワイトボックス攻撃」を防ぐためには、ディープラーニングの内部構造を隠してしまい、入力・出力のインターフェース仕様(API。Application Program Interface)だけを公開すればよいわけです。グーグルや日本のプリファード・ネットワークスが一般公開しているディープラーニングは APIの公開方式になっています。しかしこれでも騙せるのです。
|
もちろん、攻撃をかわすための防御アルゴリズムも研究されています。たとえば敵対的事例も含めて予測できるように学習するという「敵対的学習」です。こうすることによって、あらかじめ学習させた敵対的事例については間違いが起こらなくなります。
しかし敵対的学習を行ったあとのディープラーニングに対して、新たな敵対的攻撃アルゴリズムを使ってノイズを生成することは可能であり、新たな敵対的事例ができることになります。新手の敵対的事例では再び間違いが起こる。
その他、数々の防御アルゴリズムが開発されていますが、それぞれに対する攻撃手法もまた開発されています。要するに「いたちごっこ」であり、現時点では完璧な防御策はありません。現在、世界の研究者がより幅広い攻撃を効果的に防ぐことができるアルゴリズムを探求しているところです。
騙される理由が分からない
なぜディープラーニングは騙されてしまうのでしょうか。これについて瀧氏は次のように書いています。
|
ディープラーニングついて「動作メカニズムがわかっていないにもかかわらず敵対的事例が作れてしまう」ことは、実は「動作メカニズムがわかっていないにもかかわらず結構正しい答を出す」ことの裏返しの関係にあるのですね。
上の引用にあるように、騙される理由はわかっていないのが現状です。ただし、確定的なことは言えないけれども「次元の呪い」が関係しているというのが多くの研究者の共通認識です。
次元の呪い
「次元の呪い」とは、高次元空間で我々の幾何学的な直感が破綻する現象を指します。これを瀧氏は以下のように説明しています。
|
(2次元) 3√2 = 4.24
となります。次に3次元の立方体(1辺の長さが6)を考えると、立方体の中心から頂点までの距離は、直角を挟む2辺の長さが 3√2 と 3 の直角三角形の斜辺の長さなので、
(3次元) 3√3 = 5.20
となります。つまり、2次元の場合より距離が少し長くなります。座標で計算すると、3次元の場合、8つの頂点の座標は(±3, ±3, ±3)なので、原点である (0, 0, 0) との距離は 32 * 3 の平方根であり、3√3 となるわけです。
これを拡張し、高次元空間(N 次元)の1辺6の超立方体ではどうなるでしょうか。図形的には計算できないので座標で考えると、3次元の場合を拡張し、中心と頂点の距離は 32 * N の平方根となります。つまり、
(N次元) 3√N
です。もし N = 10000 だとすると、距離は
(10000次元) 3√10000 = 300
となります。低次元では中心からそう遠くない距離にあった頂点が、高次元では格段に遠くなってしまう。これが典型的な「次元の呪い」です。この「次元の呪い」によって敵対的ノイズが結果に大きく影響すると考えられているのです。
|
|
次元の呪い |
「次元の呪い」を概念的に表した図。10,000次元というような高次元空間の超立方体では、原点(=元の画像)と頂点(=元の画像に敵対的ノイズを薄くかぶせた画像)の距離は極端に大きくなってしまう。 |
(日経サイエンス 2020.1 より) |
ディープラーニングは人間の思考とは違う
ディープラーニングが騙される本質的な理由は現状では解明されていません。しかし、理由はともかくここから分かることは、どうもディープラーニングは人間とは違うようだ、ということです。
|
ディープラーニングは人間とは別の方法で認識し、理解していて、その認識方法・理解方法が解明されていない。このことはディープラーニングの社会応用に深刻な障害となります。これを瀧氏は、
もし現在でも地動説が確立していなかったら
という "寓話" で説明しています。卓抜な比喩だと思ったので、次に紹介します。
ディープラーニングで惑星の運動を予測する
天動説と地動説に関する歴史の振り返りです。コぺルニクス以前の天動説では、地球が中心にあり、その周りを太陽と惑星が回っているという宇宙像でした。もちろん、惑星の位置を詳しく観測すると単純に回っているのではない結果が得られます。つまり惑星は天球上を立ち止まったり、バックしたり、再び方向を変えて進むというような不規則な運動をするのです(惑星の "惑" とはそういう意味です)。
天動説では、この惑星の不規則な運動を「周転円」で説明していました。つまり惑星はそれ自身がある中心の周りを回っており、その中心が地球の周りを回っているという説明です(これ以外にも人為的な仮説がいろいろある)。
これに対してコペルニクスは、地球を含む惑星が太陽の周りを回っているという地動説を唱えました。これによって惑星の不規則な動きを説明したのです。ただしコペルニクスは惑星の軌道を円と考えていたため、その説明には限界がありました。
それを解決したのがケプラーです。ケプラーは精密な観測データをもとに、惑星の軌道が円ではなく楕円であることを証明しました(ケプラーの第1法則)。これによって惑星の動きは完全に説明できたのです。
さらにニュートンは万有引力の法則を発見し、2つの物体には質量に比例し距離の2乗に反比例する引力が働くことを示しました。この法則と運動方程式を組み合わせることで、惑星は太陽の周りを楕円軌道で回り、太陽は楕円の焦点にあることが数学的に証明できます。以上の、コペルニクス → ケプラー → ニュートンの発見は、科学史の偉大な成果であることは言うまでもありません。
そこでもし、現代においても地動説が確立していず、惑星の運動の予測にディープラーニングを使ったらどうなるかです。もちろん、過去の惑星の「時刻・位置データ」が膨大に蓄積されているという前提です。これをディープラーニングに学習させ、そして直近の惑星の運動を入力して今後の運動を予測する。
これは画像認識のためのディープラーニングとは種類が違います。時系列の数値データを入力し、そこから予測をしたり、傾向を把握したりするタイプのディープラーニングです。現代では音声認識、株価の予測、機械の動作状況からの異常検知などに使われています。このディープラーニングで惑星の運動を予測したらどうなるか。
|
惑星の軌道を精緻に予測するディープラーニングの中身をいくら調べてみても「惑星は太陽の周りを楕円軌道で公転する」という知見は得られないでしょう。コペルニクス以前の学者のように「周転円」のような人為的な仮説を満載した天動説で強引に計算しているだけかもしれないのです。
AIと人間の共存
以上のようなディープラーニングの現状を踏まえて、瀧氏は次のように総括しています。
|
上の引用に出てくる「オッカムの剃刀」とは、「あることを説明するためには、必要以上に多くの仮定をすべきでない」という指針ですね。オッカムは中世ヨーロッパの哲学者の名前、剃刀とは説明に不要なものを切り落とすことの比喩です。
シンプルな原理によって全てを説明するというのが科学の立場(ないしは野望)ですが、ディープラーニングはそれとは違う立場の科学の発展の可能性がある、というが瀧氏の予感です。あくまで、そういう可能性も考えられるということなのですが、これがディープラーニングがもつ重要な意味でしょう。
AIは人間の知能を上回る?
以下は瀧氏の解説を読んだ感想です。
よく「20XX年にはAIの知能が人間を上回る」というようなことを言う人がいます。しかし、この手の発言がどのような実証的研究に基づいてなされているのか、はなはだ不明です。人を驚かせようとする無責任な発言に思える。
こういうこと言うためには、最低限、① 人間の知能とはなにか、それはどういう原理やプロセスで生み出されるのか、② AIの知能とは何か、それが生み出されるプロセスは人間と同じなのか、それとも違っているのか、という2点の説明がなければなりません。
しかし現時点において、① の人間の知能が解明されているわけでは全くありません。また ② の(現在における)AIの知能は瀧氏が解説しているように、人間の知能とは別種のものである可能性が極めて高いわけです。「人間とは別種のものが人間を追い越す」というは奇妙な言説です。
もちろん特定のエリアでは、AIの方が人間より遙かに速く、正確に答えを出すことがあるでしょう。しかしそれは、たとえて言うと「走るスピードではクルマが人間を追い越す」というのに近い。クルマが走る原理は人間と全く違います。人間はそのスピードを最大限に利用して現代生活が成り立っている。もちろんクルマに頼り過ぎると運動不足に陥り、生活習慣病を発症したりしてまずいことになるわけで、その配慮が必要なことは言うまでもありません。同様のことはAIについても言えるでしょう。
瀧氏の文章は、ディープラーニングという範囲でAIと人間の違いを明らかにしたよい解説だと思いました。ディープラーニングの本質を見極める基礎研究や、ディープラーニングの答の理由を「説明可能にする」研究によって、人間のAIとのつきあい方が決まっていくし、人間とAIの共存方法が見えてくるのだと思いました。
| 補記1:SQuAD |
この記事の本文で、米国のスタンフォード大学が AIのベンチマークのために作成している SQuAD(The Stanford Question Answering Dataset)のことを書きました。これは「例文・質問・回答データベース」です。まず例文があり、それについての質問と回答が複数あります。すべて英文のテキストデータです。回答の中には "No Answer"、つまり答えがない(=例文の情報だけでは答えられない)ものもあります。
この SQuAD がどういうものか、その問題例を以下に掲載します。最新の「SQuAD 2.0」の問題の一つで、ライン河に関するものです(2020.1. 現在。https://rajpurkar.github.io/SQuAD-explorer/)。単位系の記述を分かりやすいように修正しました。
|
自然言語処理を行うAIシステムとしては、質問1では北海(the North Sea)とオランダ(the Netherlands)の関係を把握しなければなりません。また質問2では「after the Danube」という記述をもとに、ライン河より長いのがドナウ河と判断する必要があります。
なお、この例文には12の質問が設定されていますが、そのうちの5つは「No Answer」が正解です。
| 補記2:イラストで答えるリスニング問題 |
この記事の本文で、AIが不得意な大学入試問題の典型が「英語のリスニングの結果をイラストの選択で答える」ものだとしました。その実際の問題を掲げます。2019年度 センター本試験、英語リスニング問題の「第1問 問1」です。
|

羽の生えた野菜を選べばよいので、正解は言うまでもなく ② です。受験生としては、ICレコーダから流れる英語音声を聞き取ることさえできれば(特に vegetable と wings)間違えようのない問題です。
一方、AIはどうかと言うと、英語音声をリスニング台本と質問文に変換するのは容易です。全く雑音がない環境での明瞭な英語なので、この程度の音声認識は現代のAI技術では完璧にできるのです(でないとAIスピーカなど実用化できません)。
しかしそのあとが無理です。これをディープラーニングで回答しようとすると「羽の生えた野菜」含むイラストデータを大量に用意し、それを学習しなければなりません。しかし、そんなイラストの学習データを大量に用意できるはずがないのです。
もちろんセンター試験の受験生にとっても「羽の生えた野菜」のイラストを見るのは生まれて初めてでしょう。全く初めてではないかもしれませんが、過去に(絵本などで)似たイラストを見たことなど忘れているはずで、「生まれて初めて」と同じことです。生まれて初めてではあるが、リスニングができた受験生は間違えることなく答えられるのです。
AIにとって「羽の生えた野菜」を識別するのが困難なら、では「野菜」と「羽」を識別してそれが含まれるイラストを答えたらどうか。しかし、これも難しいでしょう。「野菜」にはたくさんの種類があります。「野菜」か「野菜でない(たとえば果物)」を識別するのが簡単とは思えない。しかも、実物の画像ではなくイラストです。イラストはイラストレーターがモノの特徴をとらえて(ある場合はデフォルメをして)恣意的に描くものです。たとえイラストを大量に集めたとしても有効なディープラーニングの学習はできないでしょう。しかもセンター試験の問題にあるように、ニンジンに目・鼻・口・手・足があってもそれはなおかつニンジンなのであり、そんな "高度な" 認識がAIで簡単に行くとは思えません。
100歩譲って「野菜」と「羽」のイラストを認識できるディープラーニングができたとしましょう。しかし苦労してそんなものを作ったとしても使い道がありません。なぜなら、センター試験に「羽の生えた野菜」が出るのは2019年度の1回きりだからです。次年度は「足の生えた飛行機」かもしれないし、そもそもマンガのキャラクターに関する会話がリスニングに出るのはこれっきりかもしれません(いや、センター試験なので "これっきり" のはずです)。
世の中に絶対に存在しないもののイラストは無限に考えられます。しかし受験生は常識推論でそれを理解します。常識推論で簡単に答えられるからこそ出題されるのであって、常識で簡単に答えられないようだとリスニング能力をテストするという主旨から逸脱してしまうのです。
センター試験の受験生が100%できることが、現代のAI技術では全く歯が立たない。そういう例なのでした。
| 補記3:スマートスピーカーへの敵対的攻撃 |
本文中にディープラーニングを使った画像認識を騙せることを書きましたが、同様の原理で音声認識も騙せるようです。アマゾンの「エコー」やグーグルの「グーグル・ホーム」は、ネットに繋がった音声認識技術によって人間の指示を理解し、サービスを提供します。筑波大学の佐久間淳教授(=理化学研究所・人工知能セキュリティ・プライバシーチーム リーダー)は社会に警鐘を鳴らすため、スマートスピーカーを騙す実験を行いました。
|
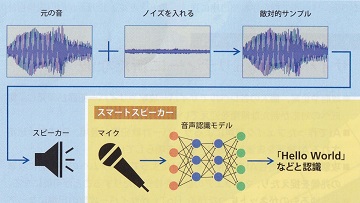
|
スマートスピーカーを騙す |
元の音にうまく設計したノイズを載せると、スマートスピーカーの音声認識は「Hellow World」と言ったと誤認する。人間には元の音がひずんだようにしか聞こえない。 |
日経サイエンス(2020年6月号)より |
この記事を読んでまず思ったのは、佐久間教授はクラシック音楽好きだということです。あるいは、人間の耳はチェロの音が最もノイズを判別しにくいということを試行から決めたのかもしれません。
それはともかく、この実験から直ちに「エコー」や「グーグル・ホーム」を騙せるということにはなりません。商用化されているスマートスピーカーは、ディープラーニングの内部構造が公開されていないからです。しかし最近のAI研究では、内部構造を知らなくても敵対的攻撃が可能な手法(=ブラックボックス攻撃)が開発されています。「警鐘を鳴らす」ための実験としては、大いに意味があると思いました。
そしてこの件もまた画像認識と同様、音声を認識するAIの "知能" が人間の知能とは違うことを示しているのでした。
(2020.6.4)
2020-01-11 15:59
nice!(0)



