No.250 - データ階層社会の到来 [社会]
No.240「破壊兵器としての数学」は、アメリカのキャシー・オニールが書いた『破壊兵器としての数学』(=原題。2016年に米国で出版)の紹介でした。日本語訳の題名は『あなたを支配し、社会を破壊する、AI・ビッグデータの罠』(インターシフト 2018.7.10)です。この中でオニールはアメリカにおける、
などをとりあげ、これらの野放図な利用がいかに社会に害悪を及ぼすか(または及ぼしているか)を厳しく警告していました。
このうち、"大学ランキング" は "組織体のランキング" ですが(日本の例として "都道府県幸福度ランキング" を書きました。No.247「幸福な都道府県の第1位は福井県」)、その他は "個人をランキングする"、ないしは "個人を分類する" ものです。そこに数学が使われているため、それが害悪になるときに「破壊兵器としての数学」だとオニールは言っているのでした。
ところで、最近の「週刊 東洋経済」(2018年12月1日号)で「データ階層社会」という特集が組まれ、現代社会において "個人をランキングしたり分類する" 動きがいかに進んでいるかを、多方面の視点から解説していました。時を得たタイムリーな特集企画だったと思ったので、その一部を紹介したいと思います。ここで使われている "データ階層社会" という言葉の定義は後回しにして、まず中国における "信用スコア" の話から紹介します。
信用スコアとは "金銭の支払いや決済に関する個人の信用度をスコア化したもの" で、キャシー・オニールの本の日本語訳では "クレジット・スコア" とか "eスコア" となっていました。ここでは "信用スコア" で統一します。
全国民の信用情報を政府当局が一元的に管理
週刊 東洋経済には、上海在住のジャーナリスト・田中信彦氏の中国レポートが掲載されていました。話は "芝麻信用" から始まります。
ダボス会議には世界の著名経済人や政治家が集まりますが、ダボスはスイスの都市です。欧州の先進国は特に人権意識やプライバシー意識が進んでいますが、そのど真ん中でのジャック・マー氏の発言です。欧米の企業家なら、たとえ内心で思っていたとしても公の場では決して口に出さない発言です。おそらくジャック・マー氏(=中国共産党員。2018.11.26 の人民日報)は、自分の発言が欧米社会からみると異様に映るとは全く考えなかったのでしょう。その "芝麻信用" とは何か、それが次の解説です。
中国は共産党の一党独裁国家であり、以前から個人情報の一元管理のしくみがあります。西欧流の "プライバシー" の概念は未成熟で、個人情報が公的機関や私企業に収集されることに対する抵抗感は薄いのが実状です。むしろ、個人情報の提供に相応のメリットがあるなら積極的に公開してもよいと考える人が多数派である。田中信彦氏はそう書いています。
このような背景のもとで芝麻信用が生まれてきたわけですが、ではどういう風に発展してきたのかが次です。
支払いについての信用力が高い人はデポジットが不要になる。これは信用スコアの真っ当な使い方です。しかし芝麻信用は次第にエスカレートしていきます。
一企業が収集した個人情報にもとづくスコアが人生を左右しかねない、しかもスコアの付け方は非公開、というのは明らかに行き過ぎです。中国政府は規制に乗り出します。
「人間そのものの格付け」になりかねないサービスを政府が規制するのは当然です。しかしこれは「民間会社がやってはいけない」ということであって、中国政府は逆に個人情報を徹底的に収集しようとしています。要するに「政府がやろうとしていることを、民間企業はやるな」というのが、信聯を設立した意味のようです。
この政府の信用情報システムは詳細が不明な部分が多いと、田中氏は書いています。芝麻信用などの民間サービスとの連携も伝えられているが、実態は不明で、情報の連結がどの程度なされているのかは、よくわかりません。しかし今後、政府の信用情報システムがますます強化されるのは間違いないと、田中氏は次のように結んでいます。
この田中信彦氏のレポートにある「全国民的な信用情報ネットワーク」ですが、北京市の具体的な内容が朝日新聞(2018年12月23日)で報告されていました。それを次に紹介します。
北京市民を監視 点数化の新制度
この朝日新聞の記事にある「クルマの通過情報を記録するシステム」ですが、日本では「Nシステム」として既に30年以上の歴史があり、1980年代後半から設置が始まりました。これは "自動車利用犯罪" の捜査のために警察庁(一部は都道府県警)が設置しているもので、高速道路や主要国道、重要施設周辺道路に設置されています。これは北京市とは違ってカメラ画像だけからクルマのナンバープレートを識別する装置で、数々の犯罪捜査に役だった実績をもっています。
しかしこの日本の「Nシステム」も "犯罪が疑われる個人の動向監視" に使われた例が指摘され、問題視されたことがあります。北京市のシステムが自動車利用犯罪の捜査や交通量の詳細把握に役立つことは確かでしょうが、そこは中国なので(特定の)市民の監視に使われることは間違いないでしょう。
週刊 東洋経済の田中信彦氏のレポートと、朝日新聞の新宅記者の記事をまとめると、次のようになるでしょう。
中国は共産党の一党独裁国家です。従って中国共産党の方針に合わない個人の行動は「反社会的行動」になります。天安門事件についてネットに書き込むのは内容の如何にかかわらず「反社会的行動」だし、都市の行政当局(責任者は共産党員)の政策を批判するのも、それが国のためを思った建設的な意見であっても反社会的行動になるでしょう。それはスコアの減少になる。逆に、政府の意向に沿った言動をする個人はスコア・アップになる。芝麻信用で起こったようなスコア競争になる可能性もありそうです。
まるで、ジョージ・オーウェルが『1984年』(1949年刊行)で描いた社会のような感じがします。オーウェルは共産主義やファシズムにみられる「全体主義」への批判を念頭において『1984年』を書いたわけですが、それはオーウェルの念頭にあった旧ソ連よりも中国で具現化されつつあるようです。中国は従来にも増して「監視社会」「プライバシー喪失社会」に向かっていると言えるでしょう。
中国の状況は他国の話か
以上のような中国の状況は、欧米や日本などの民主主義や人権を社会の基盤とする社会とは無縁の "特殊な" 状況なのでしょうか。
そうとも言えます。欧米や日本において「個人信用情報の一元管理システム」を作るなど、絶対に無理でしょう。また基本的人権という概念が確立しています(国によっては怪しい面もありますが)。つまり「人は生まれながらにして、たとえ政府であっても侵せない人権を持っている」という考え方で、たとえば思想、言論、信教の自由です。この面でも中国は異質です。
しかし我々は中国の状況を見て、反面教師として学ばなければならないとも思います。その第1の理由は、日本の政府や官僚、指導層の中にも中国政府のように考える人がいるに違いないからです。たとえば「全国民の生体識別情報(指紋など)を一元管理すれば犯罪捜査やテロ予防などの強力なツールになり、それは国民の福祉の増大につながる」と考える人がいてもおかしくはないと思います。こういった一元管理は確かにプラス面があるので、考える(夢想する)人はいるでしょう。もちろんマイナス面の方が圧倒的に多いのですが ・・・・・・。分野ごとの個人情報の一元管理は、ほかにも "健康状態"(プラス面は医療費の削減) や "資産状況"(プラス面は公平な税負担)など、いろいろ考えられます。
第2の理由は、現代社会は「データがお金と同じような価値を持つ社会」に急速に向かっているからです。データにもいろいろありますが、個人データを収集し、分析し、スコア化することも大きな価値を生む。だとすると、自由主義経済の中ではその動きが民間ベースで加速することが間違いないでしょう。それを、週刊 東洋経済の特集の「データ階層社会」というキーワードで整理してみたいと思います。
データ階層社会
"データ階層社会" とは何かですが、まず "データ" とは社会や個人の状況を表現したり、社会や個人の活動によって発生する情報のすべてです。現代では主に「コンピュータで処理可能なデジタル情報」を言います。
データのうち、個人の状況を表現したり個人の活動や行動によって発生するデータが "個人データ(個人情報)" です。これはその人の住所、氏名、生年月日、電話番号、メールアドレス、職業から始まって、顔写真や遺伝子(DNA)、指紋、健康検査値などの生体情報、個人が社会生活を営むための各種のアカウント情報や識別情報(銀行口座、SNS、決済、マイナンバー、年金番号 ・・・・・・)など、個人を説明するすべての情報が含まれます。さらに個人の行動や生活で刻々と発生する情報も個人データです。現在位置情報、インターネットサイトの閲覧履歴、検索履歴、物品の購買履歴、公共サービスの利用履歴、各種の身体活動データなどです。
"データ階層社会" と言う場合のデータとは個人データを指します。「データがお金と同様の価値を持つ社会」になりつつありますが、個人データもそれ自体が価値を持っており、また個人データ集積して分析することで新たな価値が生まれます。そのときの重要なキーワードが "プロファイリング" です。
プロファイリングとは、もともと犯罪捜査の手法です。つまり、過去の犯罪の情報の蓄積(データベース)を使って、新たに起こった犯罪を分析し、犯人像を描き出すことです。
しかし個人データについて言われるプロファイリングは少々別の意味で使われます。EUが2018年に制定した GDPR(一般データ保護規則。General Data Protection Regulation。データとは個人データのこと)では、プロファイリングを次のように定義しています。
法律英語の直訳なのでわかりにくいですが、自然人とは法人(企業など)の対立概念で、個人データという場合の個人のことです。上の定義をかいつまんで箇条書きにすると、
となるでしょう。この定義における「自動的な処理」ですが、これはコンピュータを使って行われることが多く、特にその中でもAI(人工知能)の技術を使うことが増えてきました。これが一つのポイントです。
プロファイリングの結果として得られた「個人の一定の側面」のことを "プロフィール" と呼ぶことにすると、プロフィールはさまざまな形で表現可能です。言葉や文章で表現してもよいし、たとえば映画の嗜好だと "ジャンル" とか "好きな俳優" で表現が可能でしょう。
プロフィールのうち、一つの数値で個人をランク付けできるように表現されたものが "スコア" です。ないしは、個人に関するものであることを明確にしたい場合は "個人スコア" です。最初に引用した中国の芝麻信用は、個人の支払い・決済に関する信頼度のスコアなので "信用スコア" です。
"データ階層社会" を定義すると、
と言えるでしょう。"スコア化社会" ないしは "格付け社会" という言い方もできる。個人が位置づけられる "階層" は、もちろん個人にとって固定的なものではなく、変化します。ただし、スコアの作り方によっては固定的になる傾向が出てくることにもなるでしょう。たとえば信用スコアだと、いちど支払いの延伸(債務不履行)を起こすと長期間にわたって下位の階層に位置づけられる、ということがスコア化の方法によっては起こり得るわけです。
プロファイリングはすでに大々的に行われていて、その一つが「ターゲティング広告」です。個人データから個人の嗜好や好みといったプロフィールを分析し、その個人にとって最適な広告を打つ。もちろんこれは広告主と個人の双方にとって有益な面があるのは確かです。ただし、そのネガティブな面にも着目すべきです。No.240「破壊兵器としての数学」でキャシー・オニールが指摘していたのは、個人の知識不足につけ込んで "困り果てた人に(合法ではあるが)詐欺まがいの広告を大量に打つ" 行為です。オニールはこれを「略奪的広告」と呼んでいるのでした。
また、ターゲティング広告の手法が選挙に使われる可能性についても、オニールは警鐘を鳴らしていました。たとえば "この人は有機食品を多く買うので環境問題への関心が高いと推定できる" というプロファイリングがあったとすると(これは例です)、候補者がその個人には「環境問題にいかに力を入れているかというアッピールをメールで送る」といったたぐいです。こうなると民主主義の根幹を崩しかねません。
プロファイリングとターゲティング広告が重要なビジネスモデルになっているのが、Facebook を筆頭とする SNS です。もっと一般化すると、SNS は大々的な個人データ収集装置であり、収集した個人データとそのプロファイリングによってビジネス拡大と利益の増大を図るのがビジネスモデルの根幹と言えるでしょう。
SNS が個人データの収集と利潤化という観点からすると Facebook からの個人データ流出事件は、起こるべくして起こったとも言えます。2018年3月に内部告発で判明したのは、Facebook の8700万人の個人データが英国のデータ分析会社、ケンブリッジ・アナリティカに流出し(2014年)、それがアメリカ大統領選挙の選挙運動に使われたことでした。この事件は Facebook の "脇の甘さ" が露呈したわけです。ちなみにケンブリッジ・アナリティカは、米国トランプ大統領の首席戦略官兼上級顧問だったスティーヴン・バノン氏が立ち上げた会社です。
さらに2018年6月にニューヨーク・タイムズは「Facebook がスマホや端末機メーカー約60社に対して、個人データへのアクセスを許していた」ことをスッパ抜きました。報道によると友達関係もたどれるようにしていたとのことです。日本では考えられない話ですが「個人データの収集と利潤化」を目的にしている Facebook としては "自然で、当たり前の" 行為だったのでしょう。
以上のように、個人データの収集とプロファイリングは、SNS やターゲット広告などを通して我々の生活と既に関係を持っているのですが、以下はプロファイリングの結果として得られる "個人スコア" に話を絞ります。
スコア化社会の到来
日本においても個人スコアにもとづくビジネスを展開する企業が現れてきました。2016年9月15日にソフトバンクとみずほ銀行が新会社を設立することを発表しましたが(No.175「半沢直樹は機械化できる」の「補記1」参照)、その会社が J・Score(ジェイスコア)です。
週刊 東洋経済には J・Scoreの大森社長へのインタビューも載っていました。
J・Score のビジネスモデルは「レンディング(lending)」と「リワード(reward)」です。レンディングとは "貸出し(融資)" であり、リワードとは(他企業からの)"特典提供" です。しかし大森社長の発言から明らかなことは、J・Score は出来るだけ多くの個人データを集め、それを利益に転換することを目的としていることです。「スコアアップのための項目が150ほどあり、これは入力すればするほどスコアが上がる」のは、まさに多くの個人データを集めたいからです。また「ヤフーなどとの情報連携に同意すれば基本スコアアップにつながる」のも、そうすることで個人がヤフーで行ったショッピングやオークションや情報閲覧の履歴が入手できるからです。
なぜ多くの個人データを集めるとスコアアップになるかと言うと、一つの理由は、信用スコアの精度が向上するからです。精度が悪いと、AIで算出したスコア範囲の最低ランクに位置づけざるを得ない。企業としてのリスク回避のためにはそうなるわけで、逆に精度が向上するとスコアアップになる(可能性が高い)ことになります。
さらにもう一つの(さらに重要な)理由は、集めた個人データが信用スコアの精度向上という以上に価値を持つからです。まさに「データがお金と同様の価値をもつ」社会に突入しています。たとえばヤフーとしては J・Scoreの個人データ(ないはそれを自動処理してできた信用スコア)を入手できるのは多大な金銭的メリットになるでしょう。
「レンディング」と「リワード」は、「出来るだけ多くの個人データを集めて、それを利益に転換する」というJ・Score のビジネスモデルの「最初の例」に過ぎないと思います。
身体・生活習慣データと "健康スコア"
個人データでも特に気になるのが "身体・生活習慣データ" で、その中でも健康に関係すると考えらるデータです。これは普通、健康診断や人間ドックの検査結果として個人に通知され、我々は生活習慣の改善や治療の判断に使うわけです。これが個人にとどまることなく、企業活動との関係が出てくることが懸念されます。その一つが医療保険や生命保険をビジネスにしている保険会社です。
保険会社にとって、個人の身体データ、特に長期間にわたって経年的に把握可能な身体データは "のどから手が出るほど欲しい情報"(週刊 東洋経済)です。身体データの分析によって保険の加入の判断や保険金額の査定に使えるからです。
もちろん分析によって「従来、保険に加入出来なかった人が加入できるようになる」というメリットが生まるでしょう。たとえば死亡率の高い病気にかかった人は、完治したとしても生命保険に加入できないということがあります。しかし身体データの分析によって再発リスクが薄いと判断できれば加入の道が開ける、こういったことが起こり得ます。しかし全く逆のことも起こり得る。
"究極の身体データ" とも言うべきものが、個人の遺伝子データです。2017年の11月~12月、保険会社4社の約款に遺伝に関する記載があることが判明して問題になりました(日本生命、メットライフ生命保険、損保ジャパン日本興亜ひまわり生命保険、SBI生命保険)。約款には「健康状態、遺伝、既往症などが社内基準に合わない場合は保険料の支払いを一部削減する場合がある」などどあったわけです。各保険会社は、昔の約款が残っていた、今は遺伝を利用していない、約款から遺伝を削除する、と釈明に追われました。
2013年、女優のアンジェリーナ・ジョリーは両乳房切除手術を受け、それを公表しました。母親を乳癌で失い、自身も遺伝子検査で乳癌になる確率が高いと示されたからです。しかし母親が乳癌になった主たる原因が遺伝子にあったという証明はなく、また彼女に乳癌の予兆とか何らかの身体的不調があったわけでもありません。とにかく彼女はリスクを低減する方向に行動した。そしてその行動は世間から称賛されました。少なくとも好意的に受け取られた。
これを保険会社と医療保険・生命保険の加入申請者に当てはめたらどうなるでしょうか。加入申請者の遺伝子情報から乳癌のリスクが高いと判断されると、その申請を切る(=申請を却下する)ということになります。アンジェリーナ・ジョリーの決断を称賛するのなら、そいういう風潮に次第になっていってもおかしくはない。
週刊 東洋経済によると、世界には保険・雇用分野において遺伝子情報による差別を法律で禁止している国があり、米国、ドイツ、フランス、スイス、カナダ、韓国がそうだとあります。ところが日本にはそういった法律はないのです(2018年現在)。
遺伝子データはさておき、一般的な身体データ・生活習慣データを利用して個人の「健康スコア」を作ることは容易に考えられます。もちろん国レベルでそういうことは無いでしょうが、企業・組織レベルでは考えられる。「破壊兵器としての数学」でキャシー・オニールは、「(アメリカでは)独自の健康スコアを策定し、スコアに応じて健康保険料を変えるところが現れている」と書いていて、さらに次のように警鐘を鳴らしているのでした。
「健康スコア」によって個人が健康問題に向き合えるように後押しするのは悪いことではありません。重要なのは、それが「提案」でとどまるべきことです。それが「命令・強制」になったり何らかの差別(=階層化)になると、それは個人の自由の侵害になるのです。
ウーバー・テクノロジーズの "デジタル格付け"
週刊 東洋経済の「データ階層化社会」の特集には、ウーバー・テクノロジーズの "デジタル格付け" の話が出ていました。
こうした機械的な格付けが公正だとするのは幻想です。運転手への人種的偏見が紛れ込む恐れもあるし、低格付けという「仕返し」を恐れて理不尽な乗客に耐える運転手もいます。渋滞への不満が運転手に向けられることもありうる。運転手は不満を訴えるすべがなく、格付けの理由も透明性に欠けます。要するに "デジタル格付け" という「見えない上司」が運転手の一挙手一投足をひそかに監視しているのです。
日本を含む民主主義国家にける「スコア化社会(格付け社会)」、もっと大きく言うと「データ階層社会」は、中国のように国家レベルではなく、J・Scoreやウーバー・テクノロジーズのように企業レベルで進行するはずです。そのメンバーになるかどうかは個人の意志決定ですが、現代人が各種の企業活動に "覆われて" 生活している以上、必然的に「データ階層社会」の一員とならざるを得なくなると想定できます。
以上、週刊 東洋経済の「データ階層社会」特集の一部を紹介したわけですが、以降は、データ階層社会の到来に備えた「個人の権利の重要性」についての動向です。
個人データに関する権利の重要性
個人データに関する「個人の権利」という意味で画期的なのは、2018年5月25日から EEA(=欧州経済域。EU加盟28ヶ国+ノルウェー、アイスランド、リヒテンシュタイン)で施行された GDPR(一般データ保護規則。General Data Protection Regulation)です。GDPRでは「データ主体の8つの権利」が明確化されました。「データ主体」とは個人データを提供する個人のことです。また、以下の「管理者」とは個人データを収集する企業や各種団体・組織のことです。「データ主体の8つの権利」は以下の8つを言います。
◆情報権
◆アクセス権
◆訂正権
◆削除権
◆制限権
◆データポータビリティの権利
◆異議権
◆自動化された "個人についての判断" に関する権利
この中でも重要なのは、まず「削除権」でしょう。個人データを削除することで、個人データを収集した管理者から「忘れられる」という権利です。
「データポータビリティの権利」は、今後広まると考えられる "情報銀行" を意識しているはずです。個人データを管理し、使い道を決め、修正・追加・削除する権限は、データの主体 = 個人にあるべきです。しかし個人がデータを全面的に管理するのはやりきれません。そこで専門の "情報銀行" に個人データを預け(預金ならぬ "預データ")、許可した事業者に個人データの使用を可能にして、その対価やリワードを得るしくみが必要になってきます。このとき、個人データを収集している事業者(SNS、検索、eコマース、フリマ、・・・・・・)から個人データを集めて "情報銀行" に預けるという行為が必要になります。この行為の権利を個人に保証するのがデータポータビリティです。"情報銀行" の法制度は日本でも整備されたわけですが、GDPRはそれを実効的にする権利をいち早く定めたと言えるでしょう。
また「異議権」は、「ダイレクト・マーケティングの対象にならない権利」もその中に含まれることになります。
さらに最後の「自動化された個人についての判断に関する権利」は、AIを強く意識しているところが重要です。つまり、最近のAI技術はビッグデータを収集し、機械学習でコンピュータを訓練し、それによって予測や判断をするのが主流です。人間はなぜコンピュータがそう判断したのか、必ずしも分からない。AIの危ういところです。GDPRの規制は、AIを含む自動処理はあくまで人間の判断の補助に使え、ということでしょう。
これに関連しますが、最近、日本政府の「人間中心のAI社会原則 検討会議」は「AIの7原則」を打ち出しました(日本経済新聞 2018.11.27 による)。この7原則の6番目は「AIを利用した企業は決定過程の説明責任を負う」というものです。日本経済新聞の記事の見出しは「AI判断 企業に説明責任」というものでした。7原則の中でもこの「説明責任」が重要(ないしは各国のAI原則とくらべても特徴的)ということでしょう。
日本は GDPR のような個人データを扱いのルール整備が遅れていると言われています。そもそも「保険、雇用分野において遺伝子情報による差別をしてはならない」という法律がありません。週刊 東洋経済の特集にあった「データ階層社会」は、必然的にその方向に向かうと考えられます。ルール整備が喫緊の課題だと思いました。
本文の中で、Facebookについて次の主旨のことを書きました。
その個人データを利益に転換する最大のものが、Facebookのターゲティング広告です。それについて、日本経済新聞(2019年3月21日)に記事があったので紹介します。Facebookがターゲティング広告の機能制限をしたという記事の一部です。
この記事では「フェイスブックは2019年3月19日に、求人や住宅売買、信用貸しの3分野のネット広告について、性別、人種、郵便番号などをもとに配信先を絞り込めなくすると発表した」と紹介されていました。ターゲティング広告が差別を助長しているとの批判を受けて機能を制限をしたものです。
しかしこの機能制限には実質的な意味がほとんど無いと推測されます。3分野だけということと、性別、人種、郵便番号(=居住地域)が分からなくても、個人の投稿などからそれらを推定することができるからです。記事にも、次のようにありました。
最近のAI技術の発展で、個人データを分析する能力は飛躍的に高まりました。その分析力を悪用すると、現代社会における人権や倫理の破壊につながることは明白です。個人データの保護規程や倫理規程の整備が急がれるところでしょう。
| ・ | 教師評価システム | ||
| ・ | USニューズの "大学ランキング" | ||
| ・ | 個人の行動履歴にもとづくターゲティング広告 | ||
| ・ | 個人の信用度あらわす "eスコア" | ||
| ・ | 個人の健康度をはかる健康スコア |
などをとりあげ、これらの野放図な利用がいかに社会に害悪を及ぼすか(または及ぼしているか)を厳しく警告していました。
このうち、"大学ランキング" は "組織体のランキング" ですが(日本の例として "都道府県幸福度ランキング" を書きました。No.247「幸福な都道府県の第1位は福井県」)、その他は "個人をランキングする"、ないしは "個人を分類する" ものです。そこに数学が使われているため、それが害悪になるときに「破壊兵器としての数学」だとオニールは言っているのでした。

| |||
信用スコアとは "金銭の支払いや決済に関する個人の信用度をスコア化したもの" で、キャシー・オニールの本の日本語訳では "クレジット・スコア" とか "eスコア" となっていました。ここでは "信用スコア" で統一します。
全国民の信用情報を政府当局が一元的に管理
週刊 東洋経済には、上海在住のジャーナリスト・田中信彦氏の中国レポートが掲載されていました。話は "芝麻信用" から始まります。
|
ダボス会議には世界の著名経済人や政治家が集まりますが、ダボスはスイスの都市です。欧州の先進国は特に人権意識やプライバシー意識が進んでいますが、そのど真ん中でのジャック・マー氏の発言です。欧米の企業家なら、たとえ内心で思っていたとしても公の場では決して口に出さない発言です。おそらくジャック・マー氏(=中国共産党員。2018.11.26 の人民日報)は、自分の発言が欧米社会からみると異様に映るとは全く考えなかったのでしょう。その "芝麻信用" とは何か、それが次の解説です。
|
中国は共産党の一党独裁国家であり、以前から個人情報の一元管理のしくみがあります。西欧流の "プライバシー" の概念は未成熟で、個人情報が公的機関や私企業に収集されることに対する抵抗感は薄いのが実状です。むしろ、個人情報の提供に相応のメリットがあるなら積極的に公開してもよいと考える人が多数派である。田中信彦氏はそう書いています。
このような背景のもとで芝麻信用が生まれてきたわけですが、ではどういう風に発展してきたのかが次です。
|
支払いについての信用力が高い人はデポジットが不要になる。これは信用スコアの真っ当な使い方です。しかし芝麻信用は次第にエスカレートしていきます。
|
一企業が収集した個人情報にもとづくスコアが人生を左右しかねない、しかもスコアの付け方は非公開、というのは明らかに行き過ぎです。中国政府は規制に乗り出します。
|
「人間そのものの格付け」になりかねないサービスを政府が規制するのは当然です。しかしこれは「民間会社がやってはいけない」ということであって、中国政府は逆に個人情報を徹底的に収集しようとしています。要するに「政府がやろうとしていることを、民間企業はやるな」というのが、信聯を設立した意味のようです。
|
この政府の信用情報システムは詳細が不明な部分が多いと、田中氏は書いています。芝麻信用などの民間サービスとの連携も伝えられているが、実態は不明で、情報の連結がどの程度なされているのかは、よくわかりません。しかし今後、政府の信用情報システムがますます強化されるのは間違いないと、田中氏は次のように結んでいます。
|
この田中信彦氏のレポートにある「全国民的な信用情報ネットワーク」ですが、北京市の具体的な内容が朝日新聞(2018年12月23日)で報告されていました。それを次に紹介します。
北京市民を監視 点数化の新制度
|
この朝日新聞の記事にある「クルマの通過情報を記録するシステム」ですが、日本では「Nシステム」として既に30年以上の歴史があり、1980年代後半から設置が始まりました。これは "自動車利用犯罪" の捜査のために警察庁(一部は都道府県警)が設置しているもので、高速道路や主要国道、重要施設周辺道路に設置されています。これは北京市とは違ってカメラ画像だけからクルマのナンバープレートを識別する装置で、数々の犯罪捜査に役だった実績をもっています。
しかしこの日本の「Nシステム」も "犯罪が疑われる個人の動向監視" に使われた例が指摘され、問題視されたことがあります。北京市のシステムが自動車利用犯罪の捜査や交通量の詳細把握に役立つことは確かでしょうが、そこは中国なので(特定の)市民の監視に使われることは間違いないでしょう。
週刊 東洋経済の田中信彦氏のレポートと、朝日新聞の新宅記者の記事をまとめると、次のようになるでしょう。
| ◆ | 中国は全国民を対象とする個人信用情報の一元管理に向かっている。 | ||
| ◆ | そこでの信用とは、金銭の支払いについての点数化(スコア化)のみならず、社会での個人の行動(反社会的行動や迷惑行為)も考慮した点数化である。 | ||
| ◆ | 高スコアでは公共サービスや就職などで利益を得るが、低スコアでは個人の行動が制限される(いわゆるブラックリスト。「一歩も歩けなくなる」「外出もままならなくなる」)。 |
中国は共産党の一党独裁国家です。従って中国共産党の方針に合わない個人の行動は「反社会的行動」になります。天安門事件についてネットに書き込むのは内容の如何にかかわらず「反社会的行動」だし、都市の行政当局(責任者は共産党員)の政策を批判するのも、それが国のためを思った建設的な意見であっても反社会的行動になるでしょう。それはスコアの減少になる。逆に、政府の意向に沿った言動をする個人はスコア・アップになる。芝麻信用で起こったようなスコア競争になる可能性もありそうです。
まるで、ジョージ・オーウェルが『1984年』(1949年刊行)で描いた社会のような感じがします。オーウェルは共産主義やファシズムにみられる「全体主義」への批判を念頭において『1984年』を書いたわけですが、それはオーウェルの念頭にあった旧ソ連よりも中国で具現化されつつあるようです。中国は従来にも増して「監視社会」「プライバシー喪失社会」に向かっていると言えるでしょう。
中国の状況は他国の話か
以上のような中国の状況は、欧米や日本などの民主主義や人権を社会の基盤とする社会とは無縁の "特殊な" 状況なのでしょうか。
そうとも言えます。欧米や日本において「個人信用情報の一元管理システム」を作るなど、絶対に無理でしょう。また基本的人権という概念が確立しています(国によっては怪しい面もありますが)。つまり「人は生まれながらにして、たとえ政府であっても侵せない人権を持っている」という考え方で、たとえば思想、言論、信教の自由です。この面でも中国は異質です。
しかし我々は中国の状況を見て、反面教師として学ばなければならないとも思います。その第1の理由は、日本の政府や官僚、指導層の中にも中国政府のように考える人がいるに違いないからです。たとえば「全国民の生体識別情報(指紋など)を一元管理すれば犯罪捜査やテロ予防などの強力なツールになり、それは国民の福祉の増大につながる」と考える人がいてもおかしくはないと思います。こういった一元管理は確かにプラス面があるので、考える(夢想する)人はいるでしょう。もちろんマイナス面の方が圧倒的に多いのですが ・・・・・・。分野ごとの個人情報の一元管理は、ほかにも "健康状態"(プラス面は医療費の削減) や "資産状況"(プラス面は公平な税負担)など、いろいろ考えられます。
第2の理由は、現代社会は「データがお金と同じような価値を持つ社会」に急速に向かっているからです。データにもいろいろありますが、個人データを収集し、分析し、スコア化することも大きな価値を生む。だとすると、自由主義経済の中ではその動きが民間ベースで加速することが間違いないでしょう。それを、週刊 東洋経済の特集の「データ階層社会」というキーワードで整理してみたいと思います。
データ階層社会
"データ階層社会" とは何かですが、まず "データ" とは社会や個人の状況を表現したり、社会や個人の活動によって発生する情報のすべてです。現代では主に「コンピュータで処理可能なデジタル情報」を言います。
データのうち、個人の状況を表現したり個人の活動や行動によって発生するデータが "個人データ(個人情報)" です。これはその人の住所、氏名、生年月日、電話番号、メールアドレス、職業から始まって、顔写真や遺伝子(DNA)、指紋、健康検査値などの生体情報、個人が社会生活を営むための各種のアカウント情報や識別情報(銀行口座、SNS、決済、マイナンバー、年金番号 ・・・・・・)など、個人を説明するすべての情報が含まれます。さらに個人の行動や生活で刻々と発生する情報も個人データです。現在位置情報、インターネットサイトの閲覧履歴、検索履歴、物品の購買履歴、公共サービスの利用履歴、各種の身体活動データなどです。
"データ階層社会" と言う場合のデータとは個人データを指します。「データがお金と同様の価値を持つ社会」になりつつありますが、個人データもそれ自体が価値を持っており、また個人データ集積して分析することで新たな価値が生まれます。そのときの重要なキーワードが "プロファイリング" です。
プロファイリングとは、もともと犯罪捜査の手法です。つまり、過去の犯罪の情報の蓄積(データベース)を使って、新たに起こった犯罪を分析し、犯人像を描き出すことです。
しかし個人データについて言われるプロファイリングは少々別の意味で使われます。EUが2018年に制定した GDPR(一般データ保護規則。General Data Protection Regulation。データとは個人データのこと)では、プロファイリングを次のように定義しています。
(GDPR 第4条 第4項) |
法律英語の直訳なのでわかりにくいですが、自然人とは法人(企業など)の対立概念で、個人データという場合の個人のことです。上の定義をかいつまんで箇条書きにすると、
| ・ | プロファイリングとは個人データの自動的な処理である。 | ||
| ・ | その処理は個人の一定の「側面」を分析したり評価するために行われる。 | ||
| ・ | その側面とは特に、個人の業務実績、経済状況、健康、嗜好、興味、信頼、行動、所在または移動などである。 |
となるでしょう。この定義における「自動的な処理」ですが、これはコンピュータを使って行われることが多く、特にその中でもAI(人工知能)の技術を使うことが増えてきました。これが一つのポイントです。
プロファイリングの結果として得られた「個人の一定の側面」のことを "プロフィール" と呼ぶことにすると、プロフィールはさまざまな形で表現可能です。言葉や文章で表現してもよいし、たとえば映画の嗜好だと "ジャンル" とか "好きな俳優" で表現が可能でしょう。
プロフィールのうち、一つの数値で個人をランク付けできるように表現されたものが "スコア" です。ないしは、個人に関するものであることを明確にしたい場合は "個人スコア" です。最初に引用した中国の芝麻信用は、個人の支払い・決済に関する信頼度のスコアなので "信用スコア" です。
"データ階層社会" を定義すると、
| プロファイリングで得られたスコアによって個人がランク付け(格付け、階層化)され、それが個人の社会的行動に重要な影響を及ぼす社会 |
と言えるでしょう。"スコア化社会" ないしは "格付け社会" という言い方もできる。個人が位置づけられる "階層" は、もちろん個人にとって固定的なものではなく、変化します。ただし、スコアの作り方によっては固定的になる傾向が出てくることにもなるでしょう。たとえば信用スコアだと、いちど支払いの延伸(債務不履行)を起こすと長期間にわたって下位の階層に位置づけられる、ということがスコア化の方法によっては起こり得るわけです。
プロファイリングはすでに大々的に行われていて、その一つが「ターゲティング広告」です。個人データから個人の嗜好や好みといったプロフィールを分析し、その個人にとって最適な広告を打つ。もちろんこれは広告主と個人の双方にとって有益な面があるのは確かです。ただし、そのネガティブな面にも着目すべきです。No.240「破壊兵器としての数学」でキャシー・オニールが指摘していたのは、個人の知識不足につけ込んで "困り果てた人に(合法ではあるが)詐欺まがいの広告を大量に打つ" 行為です。オニールはこれを「略奪的広告」と呼んでいるのでした。
また、ターゲティング広告の手法が選挙に使われる可能性についても、オニールは警鐘を鳴らしていました。たとえば "この人は有機食品を多く買うので環境問題への関心が高いと推定できる" というプロファイリングがあったとすると(これは例です)、候補者がその個人には「環境問題にいかに力を入れているかというアッピールをメールで送る」といったたぐいです。こうなると民主主義の根幹を崩しかねません。
プロファイリングとターゲティング広告が重要なビジネスモデルになっているのが、Facebook を筆頭とする SNS です。もっと一般化すると、SNS は大々的な個人データ収集装置であり、収集した個人データとそのプロファイリングによってビジネス拡大と利益の増大を図るのがビジネスモデルの根幹と言えるでしょう。
SNS が個人データの収集と利潤化という観点からすると Facebook からの個人データ流出事件は、起こるべくして起こったとも言えます。2018年3月に内部告発で判明したのは、Facebook の8700万人の個人データが英国のデータ分析会社、ケンブリッジ・アナリティカに流出し(2014年)、それがアメリカ大統領選挙の選挙運動に使われたことでした。この事件は Facebook の "脇の甘さ" が露呈したわけです。ちなみにケンブリッジ・アナリティカは、米国トランプ大統領の首席戦略官兼上級顧問だったスティーヴン・バノン氏が立ち上げた会社です。
さらに2018年6月にニューヨーク・タイムズは「Facebook がスマホや端末機メーカー約60社に対して、個人データへのアクセスを許していた」ことをスッパ抜きました。報道によると友達関係もたどれるようにしていたとのことです。日本では考えられない話ですが「個人データの収集と利潤化」を目的にしている Facebook としては "自然で、当たり前の" 行為だったのでしょう。
以上のように、個人データの収集とプロファイリングは、SNS やターゲット広告などを通して我々の生活と既に関係を持っているのですが、以下はプロファイリングの結果として得られる "個人スコア" に話を絞ります。
スコア化社会の到来
日本においても個人スコアにもとづくビジネスを展開する企業が現れてきました。2016年9月15日にソフトバンクとみずほ銀行が新会社を設立することを発表しましたが(No.175「半沢直樹は機械化できる」の「補記1」参照)、その会社が J・Score(ジェイスコア)です。
|
週刊 東洋経済には J・Scoreの大森社長へのインタビューも載っていました。
|
J・Score のビジネスモデルは「レンディング(lending)」と「リワード(reward)」です。レンディングとは "貸出し(融資)" であり、リワードとは(他企業からの)"特典提供" です。しかし大森社長の発言から明らかなことは、J・Score は出来るだけ多くの個人データを集め、それを利益に転換することを目的としていることです。「スコアアップのための項目が150ほどあり、これは入力すればするほどスコアが上がる」のは、まさに多くの個人データを集めたいからです。また「ヤフーなどとの情報連携に同意すれば基本スコアアップにつながる」のも、そうすることで個人がヤフーで行ったショッピングやオークションや情報閲覧の履歴が入手できるからです。
なぜ多くの個人データを集めるとスコアアップになるかと言うと、一つの理由は、信用スコアの精度が向上するからです。精度が悪いと、AIで算出したスコア範囲の最低ランクに位置づけざるを得ない。企業としてのリスク回避のためにはそうなるわけで、逆に精度が向上するとスコアアップになる(可能性が高い)ことになります。
さらにもう一つの(さらに重要な)理由は、集めた個人データが信用スコアの精度向上という以上に価値を持つからです。まさに「データがお金と同様の価値をもつ」社会に突入しています。たとえばヤフーとしては J・Scoreの個人データ(ないはそれを自動処理してできた信用スコア)を入手できるのは多大な金銭的メリットになるでしょう。
「レンディング」と「リワード」は、「出来るだけ多くの個人データを集めて、それを利益に転換する」というJ・Score のビジネスモデルの「最初の例」に過ぎないと思います。
身体・生活習慣データと "健康スコア"
個人データでも特に気になるのが "身体・生活習慣データ" で、その中でも健康に関係すると考えらるデータです。これは普通、健康診断や人間ドックの検査結果として個人に通知され、我々は生活習慣の改善や治療の判断に使うわけです。これが個人にとどまることなく、企業活動との関係が出てくることが懸念されます。その一つが医療保険や生命保険をビジネスにしている保険会社です。
保険会社にとって、個人の身体データ、特に長期間にわたって経年的に把握可能な身体データは "のどから手が出るほど欲しい情報"(週刊 東洋経済)です。身体データの分析によって保険の加入の判断や保険金額の査定に使えるからです。
もちろん分析によって「従来、保険に加入出来なかった人が加入できるようになる」というメリットが生まるでしょう。たとえば死亡率の高い病気にかかった人は、完治したとしても生命保険に加入できないということがあります。しかし身体データの分析によって再発リスクが薄いと判断できれば加入の道が開ける、こういったことが起こり得ます。しかし全く逆のことも起こり得る。
|
"究極の身体データ" とも言うべきものが、個人の遺伝子データです。2017年の11月~12月、保険会社4社の約款に遺伝に関する記載があることが判明して問題になりました(日本生命、メットライフ生命保険、損保ジャパン日本興亜ひまわり生命保険、SBI生命保険)。約款には「健康状態、遺伝、既往症などが社内基準に合わない場合は保険料の支払いを一部削減する場合がある」などどあったわけです。各保険会社は、昔の約款が残っていた、今は遺伝を利用していない、約款から遺伝を削除する、と釈明に追われました。
2013年、女優のアンジェリーナ・ジョリーは両乳房切除手術を受け、それを公表しました。母親を乳癌で失い、自身も遺伝子検査で乳癌になる確率が高いと示されたからです。しかし母親が乳癌になった主たる原因が遺伝子にあったという証明はなく、また彼女に乳癌の予兆とか何らかの身体的不調があったわけでもありません。とにかく彼女はリスクを低減する方向に行動した。そしてその行動は世間から称賛されました。少なくとも好意的に受け取られた。
これを保険会社と医療保険・生命保険の加入申請者に当てはめたらどうなるでしょうか。加入申請者の遺伝子情報から乳癌のリスクが高いと判断されると、その申請を切る(=申請を却下する)ということになります。アンジェリーナ・ジョリーの決断を称賛するのなら、そいういう風潮に次第になっていってもおかしくはない。
週刊 東洋経済によると、世界には保険・雇用分野において遺伝子情報による差別を法律で禁止している国があり、米国、ドイツ、フランス、スイス、カナダ、韓国がそうだとあります。ところが日本にはそういった法律はないのです(2018年現在)。
遺伝子データはさておき、一般的な身体データ・生活習慣データを利用して個人の「健康スコア」を作ることは容易に考えられます。もちろん国レベルでそういうことは無いでしょうが、企業・組織レベルでは考えられる。「破壊兵器としての数学」でキャシー・オニールは、「(アメリカでは)独自の健康スコアを策定し、スコアに応じて健康保険料を変えるところが現れている」と書いていて、さらに次のように警鐘を鳴らしているのでした。
|
「健康スコア」によって個人が健康問題に向き合えるように後押しするのは悪いことではありません。重要なのは、それが「提案」でとどまるべきことです。それが「命令・強制」になったり何らかの差別(=階層化)になると、それは個人の自由の侵害になるのです。
ウーバー・テクノロジーズの "デジタル格付け"
週刊 東洋経済の「データ階層化社会」の特集には、ウーバー・テクノロジーズの "デジタル格付け" の話が出ていました。
|
こうした機械的な格付けが公正だとするのは幻想です。運転手への人種的偏見が紛れ込む恐れもあるし、低格付けという「仕返し」を恐れて理不尽な乗客に耐える運転手もいます。渋滞への不満が運転手に向けられることもありうる。運転手は不満を訴えるすべがなく、格付けの理由も透明性に欠けます。要するに "デジタル格付け" という「見えない上司」が運転手の一挙手一投足をひそかに監視しているのです。
日本を含む民主主義国家にける「スコア化社会(格付け社会)」、もっと大きく言うと「データ階層社会」は、中国のように国家レベルではなく、J・Scoreやウーバー・テクノロジーズのように企業レベルで進行するはずです。そのメンバーになるかどうかは個人の意志決定ですが、現代人が各種の企業活動に "覆われて" 生活している以上、必然的に「データ階層社会」の一員とならざるを得なくなると想定できます。
以上、週刊 東洋経済の「データ階層社会」特集の一部を紹介したわけですが、以降は、データ階層社会の到来に備えた「個人の権利の重要性」についての動向です。
個人データに関する権利の重要性
個人データに関する「個人の権利」という意味で画期的なのは、2018年5月25日から EEA(=欧州経済域。EU加盟28ヶ国+ノルウェー、アイスランド、リヒテンシュタイン)で施行された GDPR(一般データ保護規則。General Data Protection Regulation)です。GDPRでは「データ主体の8つの権利」が明確化されました。「データ主体」とは個人データを提供する個人のことです。また、以下の「管理者」とは個人データを収集する企業や各種団体・組織のことです。「データ主体の8つの権利」は以下の8つを言います。
| データ主体の8つの権利 |
◆情報権
| データ主体は、個人データを収集する管理者から各種の情報の通知を受け取る権利があります。この通知には、管理者の身元と連絡先、予定している個人データの処理内容とその法的根拠、個人データの保管期間、データ主体の各種権利(以下のアクセス権、訂正権、削除権、等々)、プロファイリングを含む自動決定に個人データを使用する場合はその必要性、などが含まれます。 |
◆アクセス権
| 個人データへのアクセスができ、そのコピーを入手できる権利 |
◆訂正権
| 不正確な個人データの訂正を管理者に求める権利 |
◆削除権
| 自分に関する個人データを削除するように管理者に要求できる権利。いわゆる「忘れられる権利」。 |
◆制限権
| 個人データの処理を制限するように管理者に要求できる権利。データ主体が管理者に訂正を求めたり異議を唱えたりしていて、それが解決するまでの期間における処理の禁止など。 |
◆データポータビリティの権利
| 個人データを別の管理者に提供するため、転送可能な形で自分に関する個人データの提供を管理者から受け取る権利。 |
◆異議権
| 管理者が行う個人データの処理に異議を唱える権利。その処理がダイレクトマーケティングであれば、管理者は処理を中止。それ以外なら、管理者はその処理がデータ主体の権利に優先することの根拠を示す必要がある。 |
◆自動化された "個人についての判断" に関する権利
| データ主体が、プロファイリングを含む自動処理のみにもとづいた個人に関する重要な決定の対象にならない権利。重要とは、法的な決定やそれに準じる決定(人事採用、保険加入など)。 |
この中でも重要なのは、まず「削除権」でしょう。個人データを削除することで、個人データを収集した管理者から「忘れられる」という権利です。
「データポータビリティの権利」は、今後広まると考えられる "情報銀行" を意識しているはずです。個人データを管理し、使い道を決め、修正・追加・削除する権限は、データの主体 = 個人にあるべきです。しかし個人がデータを全面的に管理するのはやりきれません。そこで専門の "情報銀行" に個人データを預け(預金ならぬ "預データ")、許可した事業者に個人データの使用を可能にして、その対価やリワードを得るしくみが必要になってきます。このとき、個人データを収集している事業者(SNS、検索、eコマース、フリマ、・・・・・・)から個人データを集めて "情報銀行" に預けるという行為が必要になります。この行為の権利を個人に保証するのがデータポータビリティです。"情報銀行" の法制度は日本でも整備されたわけですが、GDPRはそれを実効的にする権利をいち早く定めたと言えるでしょう。
また「異議権」は、「ダイレクト・マーケティングの対象にならない権利」もその中に含まれることになります。
さらに最後の「自動化された個人についての判断に関する権利」は、AIを強く意識しているところが重要です。つまり、最近のAI技術はビッグデータを収集し、機械学習でコンピュータを訓練し、それによって予測や判断をするのが主流です。人間はなぜコンピュータがそう判断したのか、必ずしも分からない。AIの危ういところです。GDPRの規制は、AIを含む自動処理はあくまで人間の判断の補助に使え、ということでしょう。
これに関連しますが、最近、日本政府の「人間中心のAI社会原則 検討会議」は「AIの7原則」を打ち出しました(日本経済新聞 2018.11.27 による)。この7原則の6番目は「AIを利用した企業は決定過程の説明責任を負う」というものです。日本経済新聞の記事の見出しは「AI判断 企業に説明責任」というものでした。7原則の中でもこの「説明責任」が重要(ないしは各国のAI原則とくらべても特徴的)ということでしょう。
日本は GDPR のような個人データを扱いのルール整備が遅れていると言われています。そもそも「保険、雇用分野において遺伝子情報による差別をしてはならない」という法律がありません。週刊 東洋経済の特集にあった「データ階層社会」は、必然的にその方向に向かうと考えられます。ルール整備が喫緊の課題だと思いました。
| 補記 |
本文の中で、Facebookについて次の主旨のことを書きました。
| ◆ | Facebook は大々的な個人データの収集装置である。 | ||
| ◆ | 収集した個人データとそのプロファイリングで利益を生むのがFacebookのビジネスモデルである。 | ||
| ◆ | 2018年に、Facebookからの大量の個人データ流出が相次いで判明した。 |
その個人データを利益に転換する最大のものが、Facebookのターゲティング広告です。それについて、日本経済新聞(2019年3月21日)に記事があったので紹介します。Facebookがターゲティング広告の機能制限をしたという記事の一部です。
|
この記事では「フェイスブックは2019年3月19日に、求人や住宅売買、信用貸しの3分野のネット広告について、性別、人種、郵便番号などをもとに配信先を絞り込めなくすると発表した」と紹介されていました。ターゲティング広告が差別を助長しているとの批判を受けて機能を制限をしたものです。
しかしこの機能制限には実質的な意味がほとんど無いと推測されます。3分野だけということと、性別、人種、郵便番号(=居住地域)が分からなくても、個人の投稿などからそれらを推定することができるからです。記事にも、次のようにありました。
|
最近のAI技術の発展で、個人データを分析する能力は飛躍的に高まりました。その分析力を悪用すると、現代社会における人権や倫理の破壊につながることは明白です。個人データの保護規程や倫理規程の整備が急がれるところでしょう。
(2019.4.12)
2019-01-18 17:31
nice!(0)
No.249 - 同位体比分析の威力 [技術]
No.239「ヨークの首なしグラディエーター」で書いた話の続きです。No.239 では、イギリスのヨークで発掘された古代ローマ時代の剣闘士の遺体について、
ことを書きました。ある遺体の出身地はヨークから5000キロも離れた中近東地域らしいと ・・・・・・。この分析には "安定同位体分析" という技術が使われました(No.239の「補記」参照)。最近、これと類似の話が新聞に載っていました。まずその記事を引用したいと思いますが、分析の対象は剣闘士の歯ではなく "ヤギの毛" です。
NTTグループは情報通信のインフラ企業集団であり、NTTはそのトップに位置する持ち株会社です。そして日本でも有数の研究所をもっています。そのNTT研究所が高級毛素材であるカシミアの原産地推定をするのは少々奇妙に聞こえますが、"レーザー技術" という1点で関わりがあるということでしょう。レーザーは、NTTグループの命とも言える光通信を実現するための重要技術です。この新聞記事に書かれていることをまとめると、
となりますが、これと No.239 の
という話を比べると、分析対象となったカシミヤヤギと古代ローマ時代の剣闘士には2000年の年月の隔たりがあるものの、やっていることは同じと言えるでしょう。
そこで、今回はこの記事を機会に "安定同位体分析" について再度、調べてみたいと思います。No.239 の「補記」の詳細化です。
安定同位体
自然界に存在する原子には、同じ原子でも「質量数」が違うものが存在し、これらを「同位体」と呼びます(=アイソトープ)。質量数とは「陽子の数」と「中性子の数」の合計ですが、原子の種類は陽子の数(=原子番号)で決まるので、同位体は中性子の数が違うということになります(このあたりは高校化学の基礎)。
同位体には「放射性同位体」と「安定同位体」があります。たとえば原子番号6、質量数14の炭素14(146C)は放射性同位体で、放射線の1種である "ベータ線" を放出して窒素14(147N)に変化します(=ベータ崩壊)。
この炭素14のベータ崩壊の半減期(半数の原子が変化するまでの時間)は5730年です。地球上では宇宙線の影響で常に新しい炭素14が供給されているので、生物の炭素14の存在比率は炭素1兆個につき1個程度と、ほぼ一定です。しかし生物が死ぬと炭素14の取り込みが止まり、体内の炭素14はベータ崩壊で次第に減っていきます。このことを利用して動植物の遺骸の年代測定が行われることはよく知られています。
一方、「安定同位体」は他の原子に変化することはなく、自然界で安定して存在します。炭素で言うと、炭素12(12C)と炭素13(13C)が安定同位体で、地球上での存在比率は約 99:1 です。
安定同位体の化学的性質は同じですが、質量数が違うため重さが微妙に違います。このため安定同位体の存在比は、その存在箇所によって違ってくる。これが各種の分析を可能にする要因です。
安定同位体は質量が違うことを利用して、試料中の同位体の比率が計測できます。典型的な方法は、試料を燃焼ないしは熱分解してガスにし、イオン化して(=電荷を持たせて)磁場の中に通します。すると質量の違いによってイオンの軌跡の "曲がりかた" が違ってきて、同位体が分別できます。
記事にあるNTTの方法は、それとは違ってレーザ光を利用するものです。安定同位体は特定の波長の光を吸収しますが、質量数の違いによって吸収する波長が微妙に違います。また同位体の量によって光の吸収量が変わる。つまり波長が違うレーザ光を照射することにより、安定同位体の存在比が測定できます。NTTとしてはこの技術をアッピールしたいというのが、カシミヤヤギの新聞記事の背景にあるのでしょう。
炭素同位体:12C と 13C
炭素(原子番号6)の安定同位体、12C と 13C の地球上の平均の存在比は、98.9%:1.1%であり、それが二酸化炭素になった 12CO2 と 13CO2の存在比も同じです。二酸化炭素は植物の生育に必須の分子であり、これを利用して安定同位体分析を行います。
植物の特徴は光合成を行うことですが、光合成は「光化学反応(=明反応)」と「カルビン回路(=暗反応)」で行われます。まず光化学反応で水(H2O)と光から、酸素(O2)と化学エネルギー物質が作り出されます。次にカルビン回路で化学エネルギー物質と二酸化炭素(CO2)から炭素数3の化合物(グリセルアルデヒド3-リン酸)が合成されます。この化合物は葉緑体の中でデンプンに変換され蓄積されます。このタイプの光合成は「C3型光合成」と呼ばれていて、多くの植物がこのタイプです。C3の名前は、光合成の過程で作られる炭素化合物が炭素数3のものであることによります。C3型光合成を行う植物が「C3植物」です。
一方、これとは違う「C4型光合成」があります。これは光化学反応とカルビン回路に加えて "CO2取り込み・蓄積回路" を持つ光合成です。このタイプの光合成では、CO2が炭素数4の化合物(オキサロ酢酸)として取り込まれ、蓄積されます。この炭素数4の化合物からCO2が再生成されてカルビン回路に送り込まれ、最終的にデンプンとして蓄えられます。つまり植物内には "CO2 のストック" がたくさんあることになります。このタイプの植物を「C4植物」と呼んでいます。
一般に植物は、高温や乾燥の環境下では気孔を閉じがちにならざるを得ず、そのため CO2 を集めにくくなりますが、C4植物は CO2 の蓄積・濃縮が可能なため、光合成の効率が高い。C4植物は高温・乾燥・低 CO2 といった、植物としては過酷な環境に適応したものと考えられています。
人間と直接関係が深い代表的なC4植物は、イネ科のトウモロコシ、サトウキビ、アワ、ヒエ、キビ、モロコシなどです。ちなみに、同じイネ科のコメと小麦はC3植物です。一般に、同じ科でもC3植物とC4植物が混じっています。
なお、C3/C4以外に「CAM型光合成」を行う植物があります。CAMとはベンケイソウ型有機酸代謝(Crassulacean Acid Metabolism)の略で、砂漠などの水分が慢性的に少なく昼夜の温度差が大きい環境に適応しています。CO2の蓄積・濃縮をすることはC4植物と同じですが、CAM植物は夜に気孔をあけて CO2 を取り込み、昼間は完全に気孔を閉じて水分の損失を防ぎます。サボテン科やベンケイソウ科にCAM型植物があります。人間に関係の深いCAM型植物はパイナップル(パイナップル科)です。
安定同位体分析で普通使われるのは、C3植物とC4植物の炭素同位体の相違です。12CO2 と 13CO2 を比較すると、12CO2の方が軽いため、光合成の過程で植物が取り込みやすい。そのため、CO2 取り込み能力が高いC4植物の方がより多くの 13CO2 を取り込むことになり、13C の同位体比が高くなります。
このことを利用して、たとえば純粋なハチミツかどうかの判定が可能です。ハチミツの主成分はブドウ糖と果糖ですが、これは樹木や草の花の蔗糖(砂糖の主成分)を蜂がブドウ糖と果糖に分解したものです。蜂が蜜を集める花はC3植物なので、ハチミツのブドウ糖と果糖は「C3植物由来」ということになります。
一方、転化糖と呼ばれるものがあって、これはサトウキビから作られる蔗糖を人工的にブドウ糖と果糖に分解したものです。サトウキビはC4植物なので、転化糖のブドウ糖と果糖は「C4植物由来」です。つまりハチミツに転化糖を混ぜると 12C と 13C の同位体比が違ってくる。これを利用してハチミツに混ぜものが無いかどうかを鑑定できます。株式会社地球科学研究所のホームページによると「C4由来の糖類が7%以上混入すると検出可能」だそうです。高い精度で判定が可能なことがわかります。
昆虫や鳥、魚、草食動物は、摂取する植物によって体内の炭素同位体比が違ってきます。さらに肉食動物も、餌となる草食動物の炭素同位体比に影響されます。つまり、炭素同位体比は食性の判断の一助になります。ただし食性の推定については炭素同位体比に加えて、次の窒素同位体比も使われます。
窒素同位体:14N と 15N
窒素(原子番号7)の安定同位体は、窒素14(147N)と窒素15(157N)があり、その地球上での存在比は 99.636%:0.364% です。この存在比は大気中でも土壌中でも同じです。
窒素は植物や動物をはじめ生物にとっては必須の元素ですが、食物連鎖に従って生物中の窒素15(15N)が "濃縮される" ことが知られています。たとえば、土壌 → 植物 → 草食動物 → 肉食動物という食物連鎖の過程において 15N の割合が高まっていく。つまり、窒素同位体の存在比を調べることにより、前項の炭素同位体の存在比とを合わせて生物の食性が推定できることになります。
さらに窒素同位体を使って有機栽培かどうかの判断もできます。つまり化学肥料に含まれる窒素原子(N)の "原料" は大気中の窒素分子なので、その窒素同位体の組成は土壌と同じです。しかし有機栽培で使われる肥料は 15N が多い枯れた植物や動物の糞から作られるので、有機栽培の畑の 15N は化学肥料を使った土壌よりも多くなります。このため、有機栽培の野菜や穀物も 15N の割合が高くなり、判定ができます。
水素同位体:1H と 2H
酸素同位体:16O と 18O
水素(原子番号1)と酸素(原子番号8)の安定同位体は、地球上の水(H2O)の同位体分析で使われます。水素の安定同位体は1H と 2H(= 重水素。Dとも表記される)であり重水素の存在比は0.015%程度です。また、酸素の安定同位体は 166O と 18 6O で、18O の存在比は0.2%程度です。17O も安定同位体ですが、存在比が少なく同位体分析に使われないので割愛します。
自然界に存在する水のほとんどは 1H216O で、これを便宜上 "軽い水" と呼びます。しかし自然界には 2H1H16O や 1H218O も存在し、これらを "重い水" と呼びます。軽い水と重い水の化学的性質は同じですが、重さが違うので物理的性質が違ってきます。つまり、軽い水ほど早く気化し、重い水ほど早く凝固します。
地球が太陽から受ける熱は赤道付近が最大で、北極・南極付近が最小です。一方、宇宙空間に逃げる熱は赤道付近も北極・南極付近もあまり変わりません。このままでは赤道付近がどんどん熱くなるように思えますが、そうはなりません。それは赤道付近から高緯度に熱を輸送する地球規模の大気の循環があるからです。赤道付近で水が蒸発すると気化熱を奪いますが、その蒸発する水は軽い水が多くなります。その水蒸気が雲となって大気の循環で高緯度に移動し、液化して雨を降らせる。その時に凝固熱が放出されます。この大気の循環で熱が輸送されますが、結果として赤道付近には重い水が多く残ることになります。つまり、地球規模で言うと緯度が高いほど軽い水が増えることになります。
同様のことが、海からの水蒸気が雲となって陸地に移動し、平地や山に雨を降らせるときにも起こります(下図)。つまり雨が降るときには、より重い水から早く液化します。従って内陸に行くほど(海岸から離れるほど)軽い水が増えることになり、また高度が上がるほど軽い水が増えることになります。
次の図は日本列島の河川水、地下水(浅層)の酸素安定同位体(18O)の比率を調べた図です。数字は「軽い水に対する重い水の比率が世界標準からどれだけズレているか」を示した数値です。単位はパーミル(千分率)で、たとえば -10 は、-10/1000 = - 1% を示します。つまり「-10」の意味は、
標準比率からのズレ =
マイナス(標準比率 × 0.01)
ということです。これを見ると日本列島も緯度が高くなるほど重い水が減り、また内陸に行くほど重い水が減ることが分かります。
上に引用した2つの図は日本醸造協会誌に掲載された論文からのものですが、なぜ醸造協会誌にこのような論文が載るかというと、安定同位体分析で日本酒の産地が推定できるからです。
日本酒は水が命と言われますが、この水は普通、蔵元の地元の地下水です。分析によると「地元の河川水・地下水の酸素安定同位体比と、醸造された日本酒の酸素安定同位体比」の間には、かなりクリアな相関関係がみられるとのことです。もちろん同じ酸素安定同位体比をもつ地域は複数あるので産地の完全な特定はできませんが、少なくともその産地で作られたもではないということは分析できるわけです。
このような河川の水や地下水は、その土地で育った植物や動物の水素・酸素安定同位体比に影響を与えます。つまりコメなどの産地判定にも活用できることになります。
ここまでくると、最初に引用したNTTのカシミヤの産地推定の記事につながります。カシミヤヤギの産地は中国の北西部の各地方、ネパール、モンゴル、イランなどに限られます。これらの地方は特有の水素・酸素安定同位体比があるはずで、それがカシミヤヤギの毛に影響します。また記事によるとNTTは炭素同位体も分析したようで、それはカシミヤヤギの食性に関係しています。窒素同位体の話が記事にありませんが、それはカシミヤヤギの産地推定には有効ではなかったということでしょう。
具体的にどうやって分析したかですが、NTTのホームページによると、まずカシミヤ毛の産地分析の専門家がいて、その人は顕微鏡でカシミヤ毛を見て産地を推定するそうです。それで推定したカシミヤ毛の産地ごとに安定同位体分析をすると、明白な差異が見られた。つまり安定同位体分析によって産地が推定できることが分かった ・・・・・・ というのがNTTの説明です。どこまでの詳細分析が可能なのか、たとえば中国の内モンゴル自治区のカシミヤとモンゴルのカシミヤの区別はつくのか、などは不明ですが、とにかく人の経験とノウハウではなく、サイエンスの力で産地推定ができるということは進歩でしょう。
なぜ、ここまでの分析するのでしょうか。我々が知っているのは、カシミヤは高級品であり、まがいものが多いということです(カシミヤに羊毛を混ぜるなど)。カシミヤと称して流通している量は生産量の4倍、という話もあるくらいです。これは常識的ですが、さらに記事から想像できるのは「カシミヤといっても産地によって品質に違いがある」ということです。従って原料の価格にも違いがあるのではと思います。また、たとえ品質・価格に差がなくても、原産地が証明できることは流通経路も明確になり、大きな意味での品質保証と安定供給に寄与するということでしょう。
ストロンチウムの安定同位体
今までの水素(H)、酸素(O)、炭素(C)、窒素(N)は生命体の維持に不可欠な元素であり、安定同位体分析では「4大元素」と呼ばれていますが、それ以外にも分析に使われる元素があります。その例がストロンチウム(Sr:原子番号38)です。
ストロンチウム(38Sr)は土壌中に含まれますが、安定同位体として 84Sr(平均存在比:0.56%) 86Sr(9.86%) 87Sr(7.0%) 88Sr(82.58%) の4種があります。この4種の比率は地球上における地質のできかたによって相違することが知られています。特に「87Sr/86Sr 比」は鉱物や岩石によって0.7~4.0までの値をとります。
土壌中のストロンチウム比はその土地の地質によって違い、これがその土地で育った生物のストロンチウム比に影響します。このことから、生物がどの地域で育ったかを推定できます。
以上のような地質の分析については、硫黄(16S)の同位体分析も活用されているようです。
同位体分析の威力
安定同位体の存在比は、地理的な存在場所や植物の種類によって違ってきます。そのため、食品や動植物の原産地の分析だけでなく、考古学や地球科学、環境科学でも安定同位体分析が使われています。特に4大元素(H, O, C, N)はどこにでも大量にあるだけに応用範囲が広い。
その応用の一つを No.221「なぜ痩せられないのか」に書いたのですが、水素と酸素の安定同位体分析を使って日常生活をしているヒトのエネルギー消費量の精密測定ができます。これは人工的に作った "2重標識水(2H218O)" を被験者に飲ませ、活動後の唾液(ないしは尿)の同位体分析をするものです。2Hは水分(呼吸中の水蒸気や尿、汗など)として体から排出されますが、18Oは水分として排出されると同時に、呼吸中の二酸化炭素(C18O2)としても排出されます。そのため 2H よりも 18O の方が "減りかた" が早い。この差の同位体分析で二酸化炭素の排出量が計算でき、そこから酸素消費量が求まる。それでエネルギー消費量が算出できるというわけです。非常に巧妙な方法です。
我々素人はふつう安定同位体分析に関係することはないのですが、この技術は今や世界で一般的に使われているようです。だからこそ、古代ローマの剣闘士の遺体の分析にも、カシミヤヤギの分析にも使われる。これはひとえに精密な測定が低コストで可能になったという、分析技術の発達によるのでしょう。
こういった分析技術に関連して思い出すことがあります。冒頭に引用した NTT の記事はレーザー光の吸収を利用した同位体分析でしたが、別の方法は同位体の質量の差を利用するものでした。これは「質量分析」の一つの技術ですが、質量分析でノーベル賞を受賞した日本人がいます。島津製作所の田中耕一氏です(2002年のノーベル化学賞を受賞)。田中氏はタンパク質の質量分析の第一人者です。これはタンパク質の同定や構造の解明に必須の技術で、医学や製薬、生命科学の発展の大きな支えになっています。
我々は田中氏がノーベル賞を受賞したとき、一企業のサラリーマン(博士でもない)であることに驚いたのですが、もっと注目すべきはノーベル賞委員会が、一見 "地味な" タンパク質の質量分析技術の開発者に賞を与えたことです。この技術が生命科学の発展に与えるインパクトの大きさからの判断でしょう。
超精密な分子・原子の測定技術が科学や学問の発展に大きく寄与する。それは同位体分析も同じだと思いました。
日本経済新聞に、同位体比分析によってサケの回遊ルートを分析する話が載っていたので、その記事を引用します。サケは身近な魚ですが、海のどこを泳いで日本の河川に戻ってくるのかが今まで分かっていなかったそうです。
窒素は質量数14(14N)が大部分(99.6%)ですが、安定同位体として質量数15の窒素(15N)が存在します(0.4%)。この比率、15N / 14N が窒素の同位体比です。
海中のプランクトンの同位体比は、記事にあるように生物の活動が活発かどうか、海が浅いか深いかによって変わってきます。研究チームはまず、北太平洋の広範囲で動物性プランクトンを採取し、プランクトンのタンパク質の中のフェニルアラニン(アミノ酸の一種)の同位体比を測定し、北太平洋の「窒素同位体比地図」を作成しました。これとサケの脊椎骨のフェニルアラニンの分析を付き合わせて回遊ルートを調べたわけです。
さらに記事にはサケ以外の魚の話もありました。脊椎動物の内耳には耳石と呼ばれる炭酸カルシウムでできた組織があります。魚類の耳石は年輪のような同心円状になっていて、1日に1本が形成されます。
記事では、マイワシの耳石を分析することで、回遊ルートを分析する話がありました。耳石の酸素同位体を分析すると、泳いでいた海域の水温と塩分濃度がわかるそうです。「魚の生きた環境を1日単位で読みとることも可能だ」(京都大学 石村豊穂准教授)とありました。日本経済新聞の記事にあった図を以下に引用します。
さらに記事にウナギの話もありました。No.267「ウナギの商用・完全養殖」に書いたように、ニホンウナギの産卵場は赤道に近いマリアナ海溝の付近にあり、そこで生まれた稚魚が成長しながら日本の河川に遡上してくるまでのルートは解明されています。しかし日本の河川で育ったウナギの成魚がどういうルートで産卵場までいくのかは謎です。また、養殖場でシラスウナギから成魚にしたウナギを放流したとき、それがマリアナ海溝の産卵場までたどりついているのかも不明です。
記事では東京大学の白井厚太朗准教授の研究の成果として、ウナギの耳石の酸素同位体比と泳ぐ場所の水温の関係を見い出したとありました。
ウナギはサケやマイワシと同じく日本人にはなじみの魚ですが、資源量(シラスウナギの漁獲量)が減少し、完全養殖はコスト面で商用化がまだ困難な状況です(No.267)。ウナギの生育環境の水温データは完全養殖の技術開発にも役立ちそうです。
| 歯のエナメル質を分析することで、剣闘士の出身地や食物が推定できる |
ことを書きました。ある遺体の出身地はヨークから5000キロも離れた中近東地域らしいと ・・・・・・。この分析には "安定同位体分析" という技術が使われました(No.239の「補記」参照)。最近、これと類似の話が新聞に載っていました。まずその記事を引用したいと思いますが、分析の対象は剣闘士の歯ではなく "ヤギの毛" です。
|

| |||
|
カシミヤヤギ
(livestockpedia.com) | |||
| カシミヤヤギの毛の同位体分析で、ヤギが生息していた地域が推定できる |
となりますが、これと No.239 の
| 剣闘士の歯の同位体分析で、剣闘士が生まれ育った地域が推定できる |
という話を比べると、分析対象となったカシミヤヤギと古代ローマ時代の剣闘士には2000年の年月の隔たりがあるものの、やっていることは同じと言えるでしょう。
そこで、今回はこの記事を機会に "安定同位体分析" について再度、調べてみたいと思います。No.239 の「補記」の詳細化です。
安定同位体
自然界に存在する原子には、同じ原子でも「質量数」が違うものが存在し、これらを「同位体」と呼びます(=アイソトープ)。質量数とは「陽子の数」と「中性子の数」の合計ですが、原子の種類は陽子の数(=原子番号)で決まるので、同位体は中性子の数が違うということになります(このあたりは高校化学の基礎)。
同位体には「放射性同位体」と「安定同位体」があります。たとえば原子番号6、質量数14の炭素14(146C)は放射性同位体で、放射線の1種である "ベータ線" を放出して窒素14(147N)に変化します(=ベータ崩壊)。
この炭素14のベータ崩壊の半減期(半数の原子が変化するまでの時間)は5730年です。地球上では宇宙線の影響で常に新しい炭素14が供給されているので、生物の炭素14の存在比率は炭素1兆個につき1個程度と、ほぼ一定です。しかし生物が死ぬと炭素14の取り込みが止まり、体内の炭素14はベータ崩壊で次第に減っていきます。このことを利用して動植物の遺骸の年代測定が行われることはよく知られています。
一方、「安定同位体」は他の原子に変化することはなく、自然界で安定して存在します。炭素で言うと、炭素12(12C)と炭素13(13C)が安定同位体で、地球上での存在比率は約 99:1 です。
安定同位体の化学的性質は同じですが、質量数が違うため重さが微妙に違います。このため安定同位体の存在比は、その存在箇所によって違ってくる。これが各種の分析を可能にする要因です。
安定同位体は質量が違うことを利用して、試料中の同位体の比率が計測できます。典型的な方法は、試料を燃焼ないしは熱分解してガスにし、イオン化して(=電荷を持たせて)磁場の中に通します。すると質量の違いによってイオンの軌跡の "曲がりかた" が違ってきて、同位体が分別できます。
記事にあるNTTの方法は、それとは違ってレーザ光を利用するものです。安定同位体は特定の波長の光を吸収しますが、質量数の違いによって吸収する波長が微妙に違います。また同位体の量によって光の吸収量が変わる。つまり波長が違うレーザ光を照射することにより、安定同位体の存在比が測定できます。NTTとしてはこの技術をアッピールしたいというのが、カシミヤヤギの新聞記事の背景にあるのでしょう。

| ||
|
NTTのレーザーを使う同位体分析装置。机上に設置できる小型の装置である。YouTubeより。
| ||
炭素同位体:12C と 13C
炭素(原子番号6)の安定同位体、12C と 13C の地球上の平均の存在比は、98.9%:1.1%であり、それが二酸化炭素になった 12CO2 と 13CO2の存在比も同じです。二酸化炭素は植物の生育に必須の分子であり、これを利用して安定同位体分析を行います。
植物の特徴は光合成を行うことですが、光合成は「光化学反応(=明反応)」と「カルビン回路(=暗反応)」で行われます。まず光化学反応で水(H2O)と光から、酸素(O2)と化学エネルギー物質が作り出されます。次にカルビン回路で化学エネルギー物質と二酸化炭素(CO2)から炭素数3の化合物(グリセルアルデヒド3-リン酸)が合成されます。この化合物は葉緑体の中でデンプンに変換され蓄積されます。このタイプの光合成は「C3型光合成」と呼ばれていて、多くの植物がこのタイプです。C3の名前は、光合成の過程で作られる炭素化合物が炭素数3のものであることによります。C3型光合成を行う植物が「C3植物」です。
一方、これとは違う「C4型光合成」があります。これは光化学反応とカルビン回路に加えて "CO2取り込み・蓄積回路" を持つ光合成です。このタイプの光合成では、CO2が炭素数4の化合物(オキサロ酢酸)として取り込まれ、蓄積されます。この炭素数4の化合物からCO2が再生成されてカルビン回路に送り込まれ、最終的にデンプンとして蓄えられます。つまり植物内には "CO2 のストック" がたくさんあることになります。このタイプの植物を「C4植物」と呼んでいます。
一般に植物は、高温や乾燥の環境下では気孔を閉じがちにならざるを得ず、そのため CO2 を集めにくくなりますが、C4植物は CO2 の蓄積・濃縮が可能なため、光合成の効率が高い。C4植物は高温・乾燥・低 CO2 といった、植物としては過酷な環境に適応したものと考えられています。
人間と直接関係が深い代表的なC4植物は、イネ科のトウモロコシ、サトウキビ、アワ、ヒエ、キビ、モロコシなどです。ちなみに、同じイネ科のコメと小麦はC3植物です。一般に、同じ科でもC3植物とC4植物が混じっています。
なお、C3/C4以外に「CAM型光合成」を行う植物があります。CAMとはベンケイソウ型有機酸代謝(Crassulacean Acid Metabolism)の略で、砂漠などの水分が慢性的に少なく昼夜の温度差が大きい環境に適応しています。CO2の蓄積・濃縮をすることはC4植物と同じですが、CAM植物は夜に気孔をあけて CO2 を取り込み、昼間は完全に気孔を閉じて水分の損失を防ぎます。サボテン科やベンケイソウ科にCAM型植物があります。人間に関係の深いCAM型植物はパイナップル(パイナップル科)です。
安定同位体分析で普通使われるのは、C3植物とC4植物の炭素同位体の相違です。12CO2 と 13CO2 を比較すると、12CO2の方が軽いため、光合成の過程で植物が取り込みやすい。そのため、CO2 取り込み能力が高いC4植物の方がより多くの 13CO2 を取り込むことになり、13C の同位体比が高くなります。
このことを利用して、たとえば純粋なハチミツかどうかの判定が可能です。ハチミツの主成分はブドウ糖と果糖ですが、これは樹木や草の花の蔗糖(砂糖の主成分)を蜂がブドウ糖と果糖に分解したものです。蜂が蜜を集める花はC3植物なので、ハチミツのブドウ糖と果糖は「C3植物由来」ということになります。
一方、転化糖と呼ばれるものがあって、これはサトウキビから作られる蔗糖を人工的にブドウ糖と果糖に分解したものです。サトウキビはC4植物なので、転化糖のブドウ糖と果糖は「C4植物由来」です。つまりハチミツに転化糖を混ぜると 12C と 13C の同位体比が違ってくる。これを利用してハチミツに混ぜものが無いかどうかを鑑定できます。株式会社地球科学研究所のホームページによると「C4由来の糖類が7%以上混入すると検出可能」だそうです。高い精度で判定が可能なことがわかります。
昆虫や鳥、魚、草食動物は、摂取する植物によって体内の炭素同位体比が違ってきます。さらに肉食動物も、餌となる草食動物の炭素同位体比に影響されます。つまり、炭素同位体比は食性の判断の一助になります。ただし食性の推定については炭素同位体比に加えて、次の窒素同位体比も使われます。
窒素同位体:14N と 15N
窒素(原子番号7)の安定同位体は、窒素14(147N)と窒素15(157N)があり、その地球上での存在比は 99.636%:0.364% です。この存在比は大気中でも土壌中でも同じです。
窒素は植物や動物をはじめ生物にとっては必須の元素ですが、食物連鎖に従って生物中の窒素15(15N)が "濃縮される" ことが知られています。たとえば、土壌 → 植物 → 草食動物 → 肉食動物という食物連鎖の過程において 15N の割合が高まっていく。つまり、窒素同位体の存在比を調べることにより、前項の炭素同位体の存在比とを合わせて生物の食性が推定できることになります。
さらに窒素同位体を使って有機栽培かどうかの判断もできます。つまり化学肥料に含まれる窒素原子(N)の "原料" は大気中の窒素分子なので、その窒素同位体の組成は土壌と同じです。しかし有機栽培で使われる肥料は 15N が多い枯れた植物や動物の糞から作られるので、有機栽培の畑の 15N は化学肥料を使った土壌よりも多くなります。このため、有機栽培の野菜や穀物も 15N の割合が高くなり、判定ができます。
水素同位体:1H と 2H
酸素同位体:16O と 18O
水素(原子番号1)と酸素(原子番号8)の安定同位体は、地球上の水(H2O)の同位体分析で使われます。水素の安定同位体は1H と 2H(= 重水素。Dとも表記される)であり重水素の存在比は0.015%程度です。また、酸素の安定同位体は 166O と 18 6O で、18O の存在比は0.2%程度です。17O も安定同位体ですが、存在比が少なく同位体分析に使われないので割愛します。
自然界に存在する水のほとんどは 1H216O で、これを便宜上 "軽い水" と呼びます。しかし自然界には 2H1H16O や 1H218O も存在し、これらを "重い水" と呼びます。軽い水と重い水の化学的性質は同じですが、重さが違うので物理的性質が違ってきます。つまり、軽い水ほど早く気化し、重い水ほど早く凝固します。
地球が太陽から受ける熱は赤道付近が最大で、北極・南極付近が最小です。一方、宇宙空間に逃げる熱は赤道付近も北極・南極付近もあまり変わりません。このままでは赤道付近がどんどん熱くなるように思えますが、そうはなりません。それは赤道付近から高緯度に熱を輸送する地球規模の大気の循環があるからです。赤道付近で水が蒸発すると気化熱を奪いますが、その蒸発する水は軽い水が多くなります。その水蒸気が雲となって大気の循環で高緯度に移動し、液化して雨を降らせる。その時に凝固熱が放出されます。この大気の循環で熱が輸送されますが、結果として赤道付近には重い水が多く残ることになります。つまり、地球規模で言うと緯度が高いほど軽い水が増えることになります。
同様のことが、海からの水蒸気が雲となって陸地に移動し、平地や山に雨を降らせるときにも起こります(下図)。つまり雨が降るときには、より重い水から早く液化します。従って内陸に行くほど(海岸から離れるほど)軽い水が増えることになり、また高度が上がるほど軽い水が増えることになります。
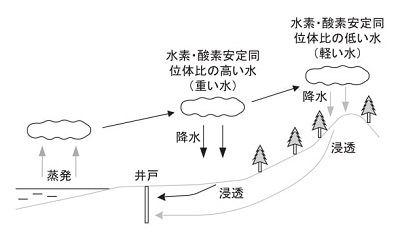
| ||
|
降水による安定同位体比の変化
海からの水蒸気が陸地で降水をもたらすとき、まず重い水から液化する。また雲が山にぶつかって高度が上がるにつれて軽い水が降る。このため海岸から離れるほど、また高度が上がるほど軽い水が増え、重い水が減る。
(日本醸造協会誌 第110巻 第2号 2015 より)
| ||
次の図は日本列島の河川水、地下水(浅層)の酸素安定同位体(18O)の比率を調べた図です。数字は「軽い水に対する重い水の比率が世界標準からどれだけズレているか」を示した数値です。単位はパーミル(千分率)で、たとえば -10 は、-10/1000 = - 1% を示します。つまり「-10」の意味は、
標準比率からのズレ =
マイナス(標準比率 × 0.01)
ということです。これを見ると日本列島も緯度が高くなるほど重い水が減り、また内陸に行くほど重い水が減ることが分かります。
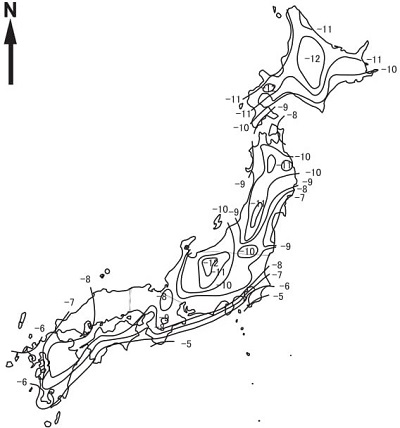
| ||
|
全国の河川水・浅部地下水の酸素同位体比
酸素18の比率を示した図である。緯度が高くなるにつれて酸素18の比率が低下する(マイナスが大きくなる)。また内陸に行くにつれても低下し、軽い水が多くなる。
(日本醸造協会誌 第110巻 第2号 2015 より)
| ||
上に引用した2つの図は日本醸造協会誌に掲載された論文からのものですが、なぜ醸造協会誌にこのような論文が載るかというと、安定同位体分析で日本酒の産地が推定できるからです。
日本酒は水が命と言われますが、この水は普通、蔵元の地元の地下水です。分析によると「地元の河川水・地下水の酸素安定同位体比と、醸造された日本酒の酸素安定同位体比」の間には、かなりクリアな相関関係がみられるとのことです。もちろん同じ酸素安定同位体比をもつ地域は複数あるので産地の完全な特定はできませんが、少なくともその産地で作られたもではないということは分析できるわけです。
このような河川の水や地下水は、その土地で育った植物や動物の水素・酸素安定同位体比に影響を与えます。つまりコメなどの産地判定にも活用できることになります。
ここまでくると、最初に引用したNTTのカシミヤの産地推定の記事につながります。カシミヤヤギの産地は中国の北西部の各地方、ネパール、モンゴル、イランなどに限られます。これらの地方は特有の水素・酸素安定同位体比があるはずで、それがカシミヤヤギの毛に影響します。また記事によるとNTTは炭素同位体も分析したようで、それはカシミヤヤギの食性に関係しています。窒素同位体の話が記事にありませんが、それはカシミヤヤギの産地推定には有効ではなかったということでしょう。
具体的にどうやって分析したかですが、NTTのホームページによると、まずカシミヤ毛の産地分析の専門家がいて、その人は顕微鏡でカシミヤ毛を見て産地を推定するそうです。それで推定したカシミヤ毛の産地ごとに安定同位体分析をすると、明白な差異が見られた。つまり安定同位体分析によって産地が推定できることが分かった ・・・・・・ というのがNTTの説明です。どこまでの詳細分析が可能なのか、たとえば中国の内モンゴル自治区のカシミヤとモンゴルのカシミヤの区別はつくのか、などは不明ですが、とにかく人の経験とノウハウではなく、サイエンスの力で産地推定ができるということは進歩でしょう。
なぜ、ここまでの分析するのでしょうか。我々が知っているのは、カシミヤは高級品であり、まがいものが多いということです(カシミヤに羊毛を混ぜるなど)。カシミヤと称して流通している量は生産量の4倍、という話もあるくらいです。これは常識的ですが、さらに記事から想像できるのは「カシミヤといっても産地によって品質に違いがある」ということです。従って原料の価格にも違いがあるのではと思います。また、たとえ品質・価格に差がなくても、原産地が証明できることは流通経路も明確になり、大きな意味での品質保証と安定供給に寄与するということでしょう。
ストロンチウムの安定同位体
今までの水素(H)、酸素(O)、炭素(C)、窒素(N)は生命体の維持に不可欠な元素であり、安定同位体分析では「4大元素」と呼ばれていますが、それ以外にも分析に使われる元素があります。その例がストロンチウム(Sr:原子番号38)です。
ストロンチウム(38Sr)は土壌中に含まれますが、安定同位体として 84Sr(平均存在比:0.56%) 86Sr(9.86%) 87Sr(7.0%) 88Sr(82.58%) の4種があります。この4種の比率は地球上における地質のできかたによって相違することが知られています。特に「87Sr/86Sr 比」は鉱物や岩石によって0.7~4.0までの値をとります。
土壌中のストロンチウム比はその土地の地質によって違い、これがその土地で育った生物のストロンチウム比に影響します。このことから、生物がどの地域で育ったかを推定できます。
以上のような地質の分析については、硫黄(16S)の同位体分析も活用されているようです。
同位体分析の威力
安定同位体の存在比は、地理的な存在場所や植物の種類によって違ってきます。そのため、食品や動植物の原産地の分析だけでなく、考古学や地球科学、環境科学でも安定同位体分析が使われています。特に4大元素(H, O, C, N)はどこにでも大量にあるだけに応用範囲が広い。
その応用の一つを No.221「なぜ痩せられないのか」に書いたのですが、水素と酸素の安定同位体分析を使って日常生活をしているヒトのエネルギー消費量の精密測定ができます。これは人工的に作った "2重標識水(2H218O)" を被験者に飲ませ、活動後の唾液(ないしは尿)の同位体分析をするものです。2Hは水分(呼吸中の水蒸気や尿、汗など)として体から排出されますが、18Oは水分として排出されると同時に、呼吸中の二酸化炭素(C18O2)としても排出されます。そのため 2H よりも 18O の方が "減りかた" が早い。この差の同位体分析で二酸化炭素の排出量が計算でき、そこから酸素消費量が求まる。それでエネルギー消費量が算出できるというわけです。非常に巧妙な方法です。
我々素人はふつう安定同位体分析に関係することはないのですが、この技術は今や世界で一般的に使われているようです。だからこそ、古代ローマの剣闘士の遺体の分析にも、カシミヤヤギの分析にも使われる。これはひとえに精密な測定が低コストで可能になったという、分析技術の発達によるのでしょう。
こういった分析技術に関連して思い出すことがあります。冒頭に引用した NTT の記事はレーザー光の吸収を利用した同位体分析でしたが、別の方法は同位体の質量の差を利用するものでした。これは「質量分析」の一つの技術ですが、質量分析でノーベル賞を受賞した日本人がいます。島津製作所の田中耕一氏です(2002年のノーベル化学賞を受賞)。田中氏はタンパク質の質量分析の第一人者です。これはタンパク質の同定や構造の解明に必須の技術で、医学や製薬、生命科学の発展の大きな支えになっています。
我々は田中氏がノーベル賞を受賞したとき、一企業のサラリーマン(博士でもない)であることに驚いたのですが、もっと注目すべきはノーベル賞委員会が、一見 "地味な" タンパク質の質量分析技術の開発者に賞を与えたことです。この技術が生命科学の発展に与えるインパクトの大きさからの判断でしょう。
超精密な分子・原子の測定技術が科学や学問の発展に大きく寄与する。それは同位体分析も同じだと思いました。
| 補記 : 魚の回遊ルート分析 |
日本経済新聞に、同位体比分析によってサケの回遊ルートを分析する話が載っていたので、その記事を引用します。サケは身近な魚ですが、海のどこを泳いで日本の河川に戻ってくるのかが今まで分かっていなかったそうです。
|
窒素は質量数14(14N)が大部分(99.6%)ですが、安定同位体として質量数15の窒素(15N)が存在します(0.4%)。この比率、15N / 14N が窒素の同位体比です。
海中のプランクトンの同位体比は、記事にあるように生物の活動が活発かどうか、海が浅いか深いかによって変わってきます。研究チームはまず、北太平洋の広範囲で動物性プランクトンを採取し、プランクトンのタンパク質の中のフェニルアラニン(アミノ酸の一種)の同位体比を測定し、北太平洋の「窒素同位体比地図」を作成しました。これとサケの脊椎骨のフェニルアラニンの分析を付き合わせて回遊ルートを調べたわけです。
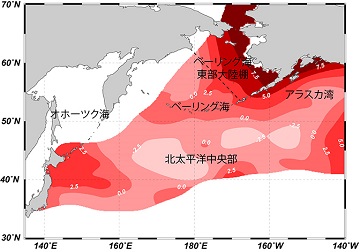
|
北太平洋の窒素同位体比地図。ベーリング海の東部大陸棚で窒素15の比率が最も高くなる。海洋研究開発機構(JAMSTEC)のサイトより。 |
さらに記事にはサケ以外の魚の話もありました。脊椎動物の内耳には耳石と呼ばれる炭酸カルシウムでできた組織があります。魚類の耳石は年輪のような同心円状になっていて、1日に1本が形成されます。
記事では、マイワシの耳石を分析することで、回遊ルートを分析する話がありました。耳石の酸素同位体を分析すると、泳いでいた海域の水温と塩分濃度がわかるそうです。「魚の生きた環境を1日単位で読みとることも可能だ」(京都大学 石村豊穂准教授)とありました。日本経済新聞の記事にあった図を以下に引用します。
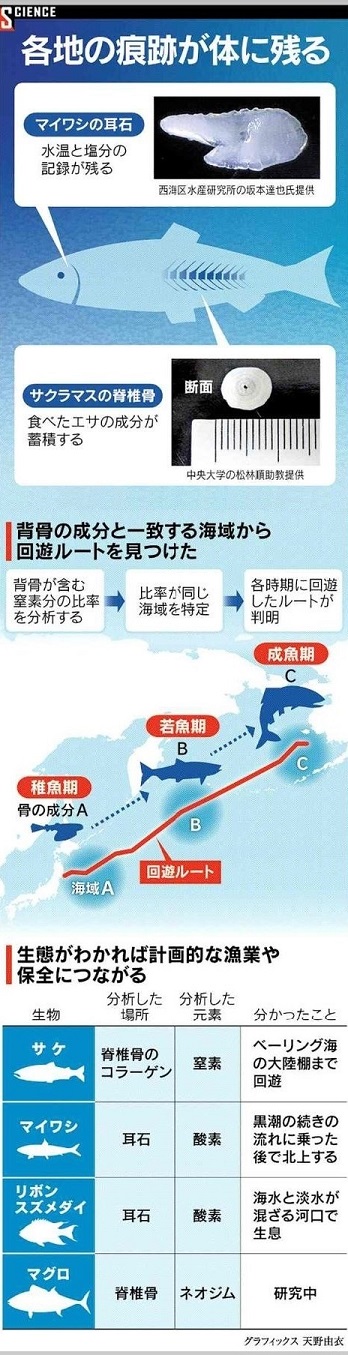
|
日本経済新聞(2020.5.17)より |
さらに記事にウナギの話もありました。No.267「ウナギの商用・完全養殖」に書いたように、ニホンウナギの産卵場は赤道に近いマリアナ海溝の付近にあり、そこで生まれた稚魚が成長しながら日本の河川に遡上してくるまでのルートは解明されています。しかし日本の河川で育ったウナギの成魚がどういうルートで産卵場までいくのかは謎です。また、養殖場でシラスウナギから成魚にしたウナギを放流したとき、それがマリアナ海溝の産卵場までたどりついているのかも不明です。
記事では東京大学の白井厚太朗准教授の研究の成果として、ウナギの耳石の酸素同位体比と泳ぐ場所の水温の関係を見い出したとありました。
ウナギはサケやマイワシと同じく日本人にはなじみの魚ですが、資源量(シラスウナギの漁獲量)が減少し、完全養殖はコスト面で商用化がまだ困難な状況です(No.267)。ウナギの生育環境の水温データは完全養殖の技術開発にも役立ちそうです。
(2020.5.30)
2019-01-05 12:19
nice!(0)



