No.181 - アルファ碁の着手決定ロジック(2) [技術]
(前回から続く)
前回の No.180「アルファ碁の着手決定ロジック(1)」の続きです。以下に出てくる policy network、SL policy network、RL policy network、ロールアウト、UCB については前回の説明を参照ください。
モンテカルロ木検索(MCTS)の一般論
モンテカルロ木検索(Monte Carlo Tree Search : MCTS)は、現代のコンピュータ囲碁プログラムのほとんどで使われている手法です。以下にMCTSの最も基本的なアルゴリズムを書きますが、もちろんこのような話はディープマインド社の研究報告には書かれていません。MCTSは既知のものとしてあります。しかしアルファ碁の検索はMCTSに則っているので、このアルゴリズムが分かると、アルファ碁の検索手法も理解できます。
| 余談ですが、モンテカルロという言葉は数学において「確率的なアルゴリズム」である場合に使われます。たとえば「モンテカルロ法で円周率を計算する」としたら、円周率は半径 1 の円の面積なので、0 以上 1 以下の実数の乱数を2つ発生させ、そのペアを平面上の座標値として原点からの距離を計算する。そして、距離が 1 以下かどうかを判定する。この計算を大量にやって 1 以下の個数の割合を計算すると、その割合の 4 倍が円周率ということになります。 余談の余談ですが、こういった問題は中高校生にプログラミングを教えるのには最適ではないかと思います。現代のパソコンは、この計算を1000万回繰り返すなど、わけなくできます(家庭用パソコンで1~2秒)。もちろん、1000万回繰り返しても精度は悪く(せいぜい小数点以下4桁程度)実用にはなりませんが、コンピュータの威力を実感するには最適だと思います。 |
以下、候補手のことを、木検索の「ノード」と呼びます。最初に、現在の盤面(白が打った直後の黒の手番とします)から黒の候補手のノードを展開します(下図)。これらノードに対して、UCB値が最大のノードを「木検索」でたどり、末端ノードに達したときロールアウトをします。その勝敗結果を、当該ノードから木検索を逆にたどって反映させます(=逆伝播)。UCB値は、逆伝播の結果で関係するものが再計算されます。
あるノードのロールアウト回数が閾値以上になったとき(下図では10回)、そのノード(下図ではNode-A)を「展開」し、次の候補手のノードを作ります。「展開」を行う閾値の設定によって、限られた時間でどこまで深く読むかが決まってきます。「展開」のあと、改めて最上位のノードから始まって最大UCBのノードをたどって末端ノードに到達します(下図ではNode-F)。そこでロールアウトを行い、結果を逆伝播させます。そしてUCB値を再計算します。UCBの計算式は、木が増殖していくことを考慮して、次のように再定義します。
| 候補手i のUCB | |||
| 候補手i 以下のノードのロールアウト数 | |||
| 候補手i 以下のノードのロールアウトによる勝ち数。候補手の色に依存。 | |||
| 候補手i の親ノードのNi | |||
| 定数(探検定数 と呼ばれることがある) |
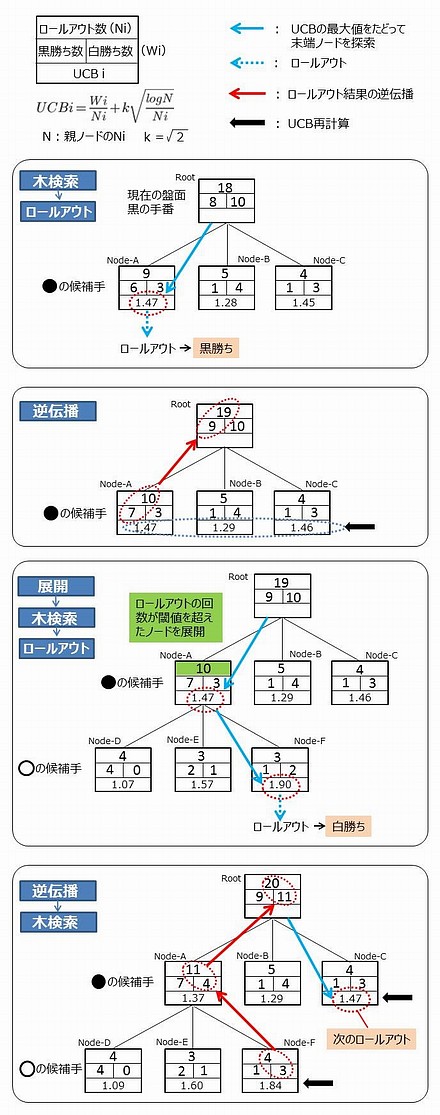
| 白の候補手である Node-F からロールアウトを行って "白勝ち" の結果が出たので、木を逆にたどってその結果を反映させる(=逆伝播。赤矢印)。そして「逆伝播で修正した Node を親に持つ Node」の UCB を再計算する(黒矢印)。その結果、黒の候補手としては Node-A より Node-C の UCB が大きくなる。Node-A が有力そうだったが、その次の白番 Node-F で白の勝利数が増えたため Node-A の有力度合いが減った。 この時点で黒の候補手の勝率は明らかに Node-A が最大であるが、それだけにこだわっていたのでは隠れた好手を見逃す危険性がある。Root から UCB の最大値をたどって木検索をすると(青矢印)、次のロールアウトの対象は Node-C になる。つまり、まだロールアウトの回数が少ない Node-C もロールアウトすべきという判断になる。 UCB は Upper Confidence Bound(=信頼上限)で、手の有力度合いの上限値である。「教師なし機械学習」の理論で使われるもので、それをコンピュータ囲碁の木検索に応用した。ロールアウトに加えて UCB のアルゴリズムを採用することでコンピュータ囲碁は飛躍的に強くなった。その次の飛躍がディープマインド社による「深層学習+強化学習」の適用ということになる。 |
この図は黒白とも候補手が3つしかない単純化された状況です。従って閾値(=10)以上のロールアウト回数になった Node-A を展開するとき、次の白の3つの候補手はいずれも "ロールアウト経験済" で、そのデータを生かしたものとしました。しかし一般的には展開の段階で "ロールアウト未経験" の候補手が現れるわけで、そのような候補手は Ni がゼロであり、Node-Aの次の一手としては真っ先にロールアウトされることになります。
上の図で Node-F の次にロールアウトされるのは Node-C ということになります。上図のように少ないロールアウト総回数では、候補手のロールアウト回数が少ないことが有利になるからです。図で言うと、Node-A が有力そうで「開拓」してみたが、ひょっとしたら Node-C が宝の山かも知れないから「探検」しようというわけです。
このような「木検索」「ロールアウト」「逆伝播」「UCB再計算」「展開」を許容時間まで繰り返します。そして最終的に次の一手として、ロールアウト回数が最も多い手を選びます。勝率最大の手は "ロールアウト回数少ないから勝率が高い" かもしれないからです。これがモンテカルロ木検索(MCTS)です。
なお、以上に述べたUCBの計算式はあくまでコンピュータ囲碁に導入された当初のもので、最新のコンピュータ囲碁プログラムは独自の計算式を使っているようです。後で説明するようにアルファ碁も独自の式です。しかし「開拓項」と「探検項」を組み合わせ、バランスよく、かつ無駄を避けつつ有効な手を探索することは同じです。
現代のコンピュータ囲碁プログラムは MCTS をベースとし独自に改良を加えていますが、MCTSには大きな弱点があります。それは、
| 黒と白の "必然の応酬" が長く続き、結果は "ほどほど" のワカレになるか、仕掛けた方が少しの利得を得る。ただし必然の応酬を間違えると、間違えた方が多大な損失を被る |
というようなケースに弱いことです。MCTSはあくまで確率的に最善手に近づこうとするものです。最善手が明白に1つしかない状況が連続すると、MCTSは間違える率が高くなる。囲碁で言うと、死活の問題とか攻め合いとかコウ争いです。このあたりをどうカバーするかは、コンピュータ囲碁プログラムのノウハウです。
このMCTSの弱点について思い出すシーンがあります。No.174「ディープマインド」で書いたように、アルファ碁とイ・セドル九段の対戦の第4局は、アルファ碁の唯一の敗戦となりました。イ・セドル九段が放った白78(No.174参照)のあと、アルファ碁は「素人でもわかる損な手」を連発し、一挙に敗勢になってしまったのです。それまで世界最高クラスのプロ棋士と(少なくとも)互角に渡り合ってきたアルファ碁が、急に "狂った" か "暴走した" ように見えた。このあたりについてディープマインド社のデミス・ハサビスCEOは、あるインタビューで「モンテカルロ木検索の弱点が露呈した」という意味の発言をしていました。この発言の真意を推測すると、
| イ・セドル九段の "白78" という手に対する正しい応手がいくつかの必然手の連続であるため、アルファ碁はそれを最後まで読み切れずに、敗勢になったと判断した |
のだと考えられます。従ってアルファ碁(黒番)は、全く別の「白が誤れば黒が得だが、白に正しく応じられれば黒が損をする手」を打った。これが悪手を連発することになった理由と考えられます。アルファ碁の手に対する白の正しい応手はアマチュアでも分かったので、いわば "ハッタリ" の手です。
しかしよくよく考えてみるとプロ棋士同士の戦いで、敗勢の時に「成功確率は低いが、成功すると大きな得になって優劣不明に持ち込める手」を打つことがあります。たとえば、相手の勢力範囲の中に深く打ち込んで活きようとするような手です。「さあ殺してください。殺せますか?」と開き直るような手です。そして、たとえプロ棋士と言えども応手を誤れば打ち込んだ石が活きてしまって形勢不明になったりする。こういう手を "勝負手" と言ったりします。
残念ながらアルファ碁は "ハッタリ" と "勝負手" の区別ができなかったようです。それは常に確率的な判断で勝敗を予測している現状のアルファ碁では致し方ないと思います。それより本質は「モンテカルロ木検索の弱点」です。これを解消するような手段を、ディープマインド社は今後繰り出してくるでしょう。そして弱点を解消した上でさらに、敗勢と判断したときの "ハッタリ" を防止する手も打ってくるのではないでしょうか。ディープマインド社には、デミス・ハサビスCEOをはじめ Go Player が多いようです。Go Player にとって許せないのは、勝負に負けることよりも素人にもわかる "ハッタリ" を打つ(="きたない" 棋譜を残してしまう)ことだろうから・・・・・・。それは対戦相手であるプロ棋士に対しても失礼です。
アルファ碁は以上のモンテカルロ木検索(MCTS)をロジックの根幹にしていますが、加えて value network というニューラルネットワークを構成し、それを勝率の判断に使っています。その説明が以下です。
value network
アルファ碁の基本的な考えかたは、
| RL policy network によるロールアウトでモンテカルロ木検索を行う |
というものです。SL policy network は囲碁熟練者の着手を 57% の精度で予測でき、RL policy network は SL より強いので(前回の No.180 参照)、これができると最強のモンテカルロ木検索になりそうです。
しかし、このままではうまくいきません。それは処理時間の問題です。policy network の計算には3ミリ秒かかります。終局までロールアウトする手数を平均100手とすると、ロールアウトに最少でも300ミリ秒 = 0.3秒必要です(その他、木検索の時間が必要)。前回の No.180 で述べた値を採用して1手に費やせる "思考" 時間を72秒とすると、この時間で可能なロールアウトは240回ですが、この程度の回数では話になりません。少なくとも10万回といった、そういう回数が必要です。
そこで登場するのが value network です。value とは価値という意味ですが、ここでは盤面の(次の打ち手にとっての)価値、という意味であり、盤面の優劣というのがシンプルな言い方です。この優劣は「勝率」で表現します。つまり、
| value network とは、"RL policy network を使ったロールアウト" による勝率判定を近似するニューラルネットワーク |
です。つまり「ロールアウトを代行する」ニューラルネットワークであり、この発想がユニークというか、その作り方を含めて、ディープマインド社の独自性を感じるところです。value network の計算時間は policy network と同じ3ミリ秒です。従って、近似の精度が高いという前提で、候補手から RL policy network によるロールアウトを例えば100回繰り返すより、value network は1万倍高速に計算できることになります(ロールアウトにおける終局までの手数を100とした場合。100×100で10,000)。
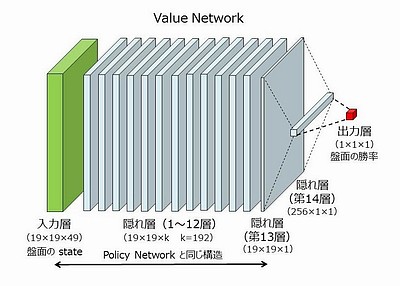
value network の構造は policy network とほぼ同じです。入力層と隠れ層1~13は、policy network の入力層と隠れ層1~12、および出力層とほぼ同じ構造をしています。ただし入力層には49番目のプレーンが追加されていて、それは石の色です。つまり黒番か白番かを勝率判定に使います。隠れ層14は256×1であり、出力層は1×1です。出力層は -1.0 ~ +1.0 の1個の実数値であり、入力層の勝率を表します(ゼロが互角)。
そこで、1つの訓練データを作るために、まず1~450までの数からランダムに U を選びます。そしてSL policy network で第1手から第(U-1)手目までを打ち、第U手目は合法手をランダムに打ちます(!!)。その結果の盤面(state)を訓練用のデータとします。このデータを RL policy network でロールアウトを繰り返し、勝率を求めます。このstateと勝率の組が訓練データの一つとなります。これを合計3000万組作成し、それを教師として学習させたのが、value network です。この訓練データの作り方は非常にユニークであり、なぜそうするのかという理由は書いていないのですが(450 ??)、ディープマインド社の試行錯誤の積み重ねによるノウハウの蓄積を感じるところです。
ディープマインド社の研究報告には「value network を使った勝率推定は、RL policy network でロールアウトして勝敗を判定するより 15,000倍 速い」と書かれています(上で1万倍速い、と推定した値)。
ここまでの説明におけるニューラルネットワークについて復習すると、以下のようになります。このネットワークは隠れ層が多段階になっているディープ・ニューラルネットワーク(Deep Neural Network)なので、DNNと表記します。
policy network = 熟練者が打ちそうな手を予測
value network = 現在の盤面の優劣を判定
|
アルファ碁は囲碁プログラムに深層学習の技術を持ち込んだのですが、そのDNNは以上のように2段階になっています。この2つのDNN(policy networkを2つに分けると合計3つのDNN)を使い分けるのがアルファ碁です。
これらのDNNのうち、policy network は "自然な発想" に思えます。熟練者の打った手を機械学習し、さらには自己対戦で強化学習もやって「次に打つ手を決めるDNN」を作る。AIと囲碁に詳しい人なら容易に思い浮かぶ発想だと思います。もちろんディープマインド社独自の工夫やノウハウが詰め込まれているのですが、基本のアイデアそのものは自然です。
これに対して value network は、ちょっと思いつかない発想です。policy network とロールアウトを使って「盤面の勝率を計算するDNN」を作れるはずだ・・・・・・。このアイデアを発想し、かつ実用になるまで磨き込んだのがディープマインド社の大きなブレークスルーだと思います。
ただし、アルファ碁はこれらの DNN だけでなく従来手法のロールアウトも併用しています。それが以下の説明です。
rollout policy
value network は、まさにコンピュータ将棋でいう「評価関数」に相当します(コンピュータ将棋の評価関数については No.174「ディープマインド」参照)。囲碁で評価関数を作るのは困難と言われていたのですが、ディープマインド社はそれを覆したわけです。従って、木検索と value network を使ってコンピュータ囲碁プログラムが作れるはずですが、少々意外なことにアルファ碁はそうはなっていません。従来手法のロールアウトも併用しています。これはもちろん RL policy network を使うのではありません。それでは遅すぎます。ロールアウト専用の「ロールアウト・ポリシー」を使います。
アルファ碁のロールアウト・ポリシー(rollout policy。研究報告では fast rollout policy と書いてある)は次のようなものです。まず、自分が打つ手を、直前に相手が打った手(直前手)に応答する手と、そうではない手に大別します。そして手を以下のように詳細分類します。
| ① | アタリから逃げる手。1種。 | ||
| ② | 直前手の周り8箇所のどこかに打つ手。8種。 | ||
| ③ | ナカデを打つ手。8,192種。このパターンは手作り。 | ||
| ④ | 応答手 = 直前手の周辺12箇所に打つ手。12箇所とは、直前手の周辺8箇所プラス、直前手から上下左右に2つ離れた4箇所。12箇所の石の配置パターンと呼吸点の数で分類し、合計 32,207種。 | ||
| ⑤ | 非応答手 = 直前手には応答しない手。打つ手の周辺の3 X 3 領域を石の配置パターンと呼吸点の数で分類して、合計 69,338種。 |
つまり碁の着手を合計、109,746種に分類し、実際の対局でどの手が多く打たれたか回帰分析の手法で分析し、ロールアウト・ポリシーの計算式を求めます。もちろんロールアウト・ポリシーは高速演算が必須条件なので、ニューラルネットワークは使わず、通常の線形演算(マトリクス演算)で可能な回帰式です。
この回帰式を求めるのに使われた訓練データは(少々意外なことにKGS Go Serverではなく)Tygem の800万の盤面データです。「タイゼム(Tygem)」は韓国の東洋オンライン社が運営する有料の囲碁対局サイトで(無料もある)、日本では「東洋囲碁」です。利用者は東アジア(韓国、日本、中国)が中心です。
以上のように、ロールアウト・ポリシーは熟練者の実際の手を予測するもので、その意味では policy network と同じです。しかし予測の精度が違います。前に SL policy network の予測精度は 57.0% と書きましたが、ロールアウト・ポリシーの予測精度は 24.2% です。SL policy network よりかなり低いわけですが、これはもちろんロールアウトに使う目的だから「ランダムなロールアウトよりは格段にマシ」なわけです。しかも計算時間が policy network より圧倒的に速い。
ロールアウト・ポリシーの計算時間は 2マイクロ秒です。ということは、3ミリ秒の RL policy network より1500倍高速ということになります。研究報告には ロールアウト・ポリシーによるロールアウト(初手から始める)を1秒間に約1000回できるとあります。アルファ碁のメイン・コンピュータは 40 多重で計算可能です。つまり、1秒間に(少なくとも)4万回のロールアウトが可能ということになります。1回の平均思考時間を72秒と仮定すると、約300万回のロールアウトが可能なことになり、これは十分な数です。ちなみに多重処理について言うと、policy network / value network はサブのコンピュータで1個づつ(多重処理なしに)計算されます。1回の計算そのものが多重処理されるからです。
アルファ碁のモンテカルロ木検索(MCTS)
アルファ碁のMCTSのアルゴリズムは、上に述べた基本のMCTSと考え方は同じです。つまりUCB値の最大値をたどって木検索を行い、ロールアウト・ポリシーでロールアウトを行います。ただし次の点が基本のMCTSと違っています。
| ① | 候補手の勝率の判定に、ロールアウトによる勝率だけでなく、value network による勝率を加味する。 | ||
| ② | アルファ碁独自のUCB値の計算式を使う。ここに policy network による確率(囲碁熟練者がそこに打つ確率の推定値)を使う。 |
の2点です。まず①ですが、アルファ碁は検索が木の末端に到達するとまず、value network の計算を行います。実際にはニューラルネットワークの計算は、検索やロールアウトを行うメイン・コンピュータとは別のサブ・コンピュータで行っており、そこに計算の依頼だけを出します。木の末端が既に value network の計算依頼を出している場合(ないしは計算済の場合)はロールアウト・ポリシーによるロールアウトになりますが、value network の計算は3ミリ秒かかり、ロールアウト・ポリシーによるロールアウトの計算は最大でも1ミリ秒(1秒間に1000回)なので、この2つは一般的には平行して行われることになります。もちろん value network の計算は一つのノードにつき1回だけです。なお、ロールアウトの1ミリ秒というのは報告に書いてある最大値(初手からのロールアウト)なので、実際にはその数分の1だと考えられます。
同一の末端ノードを訪れる回数が閾値を越えるとノードを展開するのは、基本のMCTSと同じです。その閾値はpolicy network / value network の計算のための "待ち行列" の長さによって動的に変更します。早めに展開し過ぎてニューラルネットワークの計算が間に合わないのでは意味が無いからです。
ノードを展開するとき(=次の候補手をリストアップするとき)には、policy network を使って、その候補手の確率(=囲碁の熟練者がその候補手を打つ確率の推定)を計算してノードに記憶しておきます。この値はそのノードの UCB の計算に重要な役割を果たします。
| ただし、話がややこしいのですが、policy network の計算を依頼してから終わるまでの間、別の暫定値で policy network の値の代用とするというロジックが研究報告に書かれています。これが ツリー・ポリシー(tree policy)と呼ばれるもので、このポリシーの作り方はロールアウト・ポリシーとほぼ同じです。ただし、打ち手の分類がロールアウト・ポリシーよりも詳しい(分類数が約1.5倍)。つまりロールアウト・ポリシーよりは計算時間がかかるが、熟練者が打つ手の予測はロールアウト・ポリシーよりは正確ということだと思います。このツリー・ポリシーの計算時間は研究報告には書いていないのですが、たとえば 3マイクロ秒だとすると policy network(計算時間=3ミリ秒)より1000倍速いことになります。正確さに欠けたとしても policy network の計算終了を待ってられない。暫定値でもよいからモンテカルロ木検索をどんどん進めた方がいい・・・・・・。このあたり、コンピュータ囲碁にニューラルネットワークを持ち込むということは、ニューラルネットワークの計算の遅さをいかにカバーするかが非常に大切なことがわかります。 とは言え、ここで感じる疑問は、ロールアウト・ポリシーとツリー・ポリシーという "似て非なるもの" がなぜあるのかです。ロールアウト・ポリシーをやめてツリー・ポリシーでロールアウトしてもよいはずです。論文を読む限りそれは十分可能で、一見、その方がよさそうな気がします。なぜ二つあるのか。推測なのですが、問題は処理時間ではと思います。ツリー・ポリシーの計算時間が3マイクロ秒だとするとロールアウト・ポリシー(計算時間=2マイクロ秒)の1.5倍であり、ということはツリー・ポリシーでロールアウトすると一定時間でロールアウトできる回数が3分の2になってしまいます。ツリー・ポリシーだとロールアウトの回数が稼げず、かえって弱くなってしまう・・・・・・。そういうことかと想像しました。逆に言うとロールアウト・ポリシーは "手を読む精度" と "計算時間" という二つのトレードオフのぎりぎりのところを狙って設計されているのではと感じました。想像ですが、最初にツリー・ポリシーが設計されてロールアウトにも使っていたが、よりロールアウト回数を稼ぐために簡略化した(従って速い)ロールアウト・ポリシーが作られたのではないでしょうか。ロールアウト・ポリシーを研究報告では fast rollout policy としてあるのは、そういう意味かと思いました。 |
②のアルファ碁独自のUCB値の計算式(UCBAlphaGo とします)は、次のような形をしています。次式は研究報告にある式を、本質を変えない範囲で簡略化しました。また記号を少し変えてあります。

λはアルファ碁のチューニングのためのパラメータで、0.0~1.0 の数字です。要するに value network の勝率推定とロールアウトによる勝率推定のどちらを重視するかです。研究報告では、この値を実戦では 0.5 にしたとあります。つまり、2つの勝率推定の平均値をとるということです。その理由は、各種のコンピュータ囲碁プログラムと対戦してみて、それが一番強かったからです。このあたり、いろいろと試行錯誤があったようです。
u(P)は「探検」に相当する項です。これは基本のMCTSの UCB の第2項と似ていて、考え方は同じです。ただし、大きな違いは P の存在です。これは、そのノードを生成したときに計算しておいた、policy network による候補手の確率値です(但し、先ほど書いたように、この値の計算が終わるまでは tree policy で代用します)。つまり熟練者が打ちそうな手ほど重視するということであり、これは非常に納得できます。
しかし全く意外なのは、この値が RL policy network ではなく SL policy network だということです。つまり、最強のはずの RL policy network は、対戦には全く使われていません。RL policy network は value network を作るために(対戦前に)使われるだけなのです。前に RL はコンピュータ囲碁プログラム(Pachi)と対戦して 85% の勝率だったが、SL は 11% の勝率だった、と書かれていました(前回の No.180 参照)。そんなに強い RL をなぜ使わないのか・・・・・・。これについて研究報告では次のように書かれています。
|
世界トップクラスの学術雑誌に載せる研究報告にしては、曖昧で意味が取りにくい文章です( beam ? )。さらに研究報告の次の文章では、SL policy network を使って作った value network でプレーしてみたが、それは RL policy network で作られた value network(対戦に使われたもの)より成績が悪かった、と書いてあります。
推測するに、RL policy network の出す確率は最良の手にピンポイントで集中する傾向にある。それに対して SL policy network の出す確率は「良さそうな手」に分散する傾向がある。これは人間の思考に近く、候補手を広く探索する目的で使うにはその方がよい。value network を作るときのロールアウトのように、policy network の出す確率だけに従って手を打つのなら、RL policy network がの方がよい、ということだと思います。
そう推察できるものの、何となく納得できない説明です。RL policy network は SL policy network より明らかに強い。つまり、最善手や次善手を指し示す確率が高いわけです。だとすると、UCBAlphaGo という MCTS の探索方向を決める超重要な値には RL policy network の値を採用してしかるべきです。上の引用の説明はそれだけ読むと「そうかも知れない」と思ってしまうのですが、論文全体としては矛盾しています。
引用に「たぶん(presumably)」と書いてあるように、ディープマインド社も UCBAlphaGo に SL policy network の値を採用した方が強くなることの明確な理由を説明できないのだろうと思います。このあたりディープマインド社もいろいろと試行錯誤し、対局を繰り返して現在のアルファ碁に到達したことがわかります。
以上は、UCBAlphaGo の u(P) の部分(探検項)についての議論ですが、やはりアルファ碁の着手決定ロジックの根幹は Q(action value)という勝率判定に関わる部分です。ここでは「rollout policy を使ったロールアウトによる勝率判定」と「value network による勝率判定」をミックスさせています。
rollout policy と value network にはそれぞれメリット・デメリットがあります。rollout policy のデメリットは、この policy がアマ高段の手を 24.2% の確率でしか予測できないことです。つまり「弱い打ち手」が最後まで打ってみて(=ヨセてみて)勝率を判定していることになる。これは勝率判定の誤差が大きくなると考えられます。しかし「現状の盤面そのものからロールアウトする」というメリットがある。
一方の value network は RL policy network という「極めて強い打ち手」を使って作られた勝率の予測システムです。最後まヨセてみたらどうなるかを正確に予測できるはずです。ただし、あくまでDNNを使った近似であって「現状の盤面から RL policy network を使ってロールアウトするのではない」ことがデメリットです。
この2つが相補って精度の高い勝率判定ができたことが、アルファ碁の成功原因だと考えられます。
研究報告では、その他、細かい検索のアルゴリズムやニューラルネットワークの学習の手法が多々書いてあるのですが、本質的なところは上の説明に尽きていると思うので省略します。
もう一度念を押しますが、研究報告に書かれているのは、韓国のイ・セドル 九段と戦う数ヶ月前の状況です。研究報告にあるグラフから読みとれるのは、その当時のアルファ碁の強さは KGS のレーティングで 5p(プロ五段)相当ということです。これとイ・セドル 九段は、相当な開きがあります。その後の数ヶ月の間、ディープマインド社は数々の強化をしたはずです。ロジックの見直しやチューニングはもちろんのこと、ロールアウト時間の短縮やニューラルネットワークの演算高速化もあったのではないでしょうか。計算性能は「読める手の数」に直結するので大変に重要です。以上のようなことを頭に置いておくべきでしょう。
以降は、ディープマインド社の研究報告を読んだ感想です。
感想:アルファ碁とは何か
No.174「ディープマインド」で書いたように、アルファ碁は AI研究の画期的な成果であり、それどころか、コンピュータの発展の歴史の転換点ともいえるものだと思います。その考えは変わらないのですが、研究報告を読むといろいろなことが見えてきます。
| 囲碁の常識が盛り込まれている |
個人的な一番の関心事は、アルファ碁がどこまで汎用的であり、どこまで囲碁ディペンドなのかという点でした。No.174「ディープマインド」で「Nature ダイジェスト 2016年3月号」より、次の説明を引用しました。
|
しかし研究報告を実際に読んでみると「汎用アルゴリズム」という言い方の印象がかなり変わりました。確かに policy network や value network に機械学習をさせたり強化学習をすのは汎用のアルゴリズムですが、アルファ碁全体をみるとそうとは言えない。もちろんゲームである以上、ゲームのルールや勝敗の決め方を教え込むのは必須です。しかし、それ以外に「囲碁の常識」がかなり含まれています。たとえば policy network / value network の入力層における「ダメヅマリ」を判別できるプレーンとか、シチョウに取る手、シチョウから逃れる手などです。また、rollout policy におけるナカデのパターン(8192種)です。この程度の常識は教え込まないと、とても強いプログラムは作れないのでしょう。
逆の観点からすると、現代のコンピュータ囲碁プログラムの強豪に比べるとアルファ碁は "囲碁の常識の入れ具合い" が少なく、それでもヨーロッパ・チャンピオン(プロ)に勝ったというところに価値があるのかもしれません。
そもそも policy network / value network の出発点は、アマチュア高段者が実際に対局した 2840万の盤面データであり、それは大袈裟に言うと囲碁2000年の歴史の結晶です。アルファ碁はそこから出発しています。囲碁を打つ際の人間の英知がなければ、アルファ碁はなり立たなかったわけで、そこは再認識しておくべきだと思います。
そして、このことがアルファ碁の "限界" にもなりうると思いました。典型的なのは(アルファ碁独自の)UCBの計算式に policy network を取り入れていることです(上の説明参照)。これはどういうことかと言うと「人間の熟練者が打ちそうな手ほど優先して深く読む」ということです。これはいかにもまっとうに見えるし、プロ棋士と戦って勝つためにはこれが最善なのかも知れません。しかし我々がコンピュータ囲碁プログラムに真に期待するのは、囲碁の熟練者が思いもつかない手、囲碁の歴史で培われてきた "常識" ではありえないような手、そういう手の中で「最善とは断言できないが、十分に成立する手」をコンピュータ囲碁プログラムが打つことなのです。それでこそコンピュータの意義だし、囲碁がいかに奥深いものかを再認識できることになるでしょう。人間のマネをし、人間より遙かに高速に、遙かに深く読める(しかも心理的な動揺や疲れなどが全くない)ことだけに頼って勝つというのでは、"おもしろくない" わけです。
このあたり、アルファ碁にはまだ幾多の改良の余地があると見えました。
| アマチュア高段者の打ち手を学習 |
アルファ碁の「畳み込みニューラルネットワーク」の訓練(=機械学習)に使われたデータがプロの棋譜ではなく、KGS Go Server で無料のオンライン囲碁対局を楽しんでいるアマチュア高段者(6d~9d)の棋譜(約16万)というのは意外でした。アルファ碁はプロ棋士に勝つ目的で開発されたものであり、2015年10月に樊麾(ファン・フイ)2段に5戦5勝の成績をあげました。樊麾2段はフランス在住ですが、中国棋院の2段です。アマチュア高段者が中国棋院のプロ2段に勝つことはありえません。つまりアルファ碁の機械学習はあくまで出発点であって、その後の強化学習(RL policy network)や value network、rollout policy に強さの秘密があると考えられます。
しかし、どうせなら初めからプロの棋譜を機械学習すればいいのでは、と思うわけです。なぜアマチュアの棋譜なのか。16万局程度のプロの棋譜が入手できなかったとも考えられますが、ふと思い当たることがあります。No.174「ディープマインド」で紹介した、日本のプロ棋士の方がアルファ碁の "戦いぶり"(対、イ・セドル 九段)を評して語った言葉です。
| 「 | いままでの感覚とはかけ離れたものがあった。弟子が打ったら、しかり飛ばすような」(王 銘琬 九段) | ||
| 「 | 空間や中央の感覚が人間と違う。懐が深い」(井山 裕太名人) |
この二人のプロ棋士が言う「感覚」とは、当然「プロの感覚」ということでしょう。アルファ碁は、無料のオンライン囲碁対局を楽しむアマチュア高段者の棋譜で訓練された。だからこそ「プロの感覚」とは違うものになったのではと、ふと思ったのです。そういう要素もあるのではないか。
しかも集められた約16万の棋譜の35.4%は置き碁の棋譜なのです。ディープマインド社の研究報告にそう書いてあります。アルファ碁は、プロの世界トップクラスと互先で(ハンディキャップなしに)戦って勝つという "野望" のもとに開発されたものです。訓練用のデータから置き碁の棋譜を除外することなど簡単にできるはずなのに、あえて置き碁を入れてある。置き碁の白(上手)は少々無理筋の手も打って、棋力の差で勝とうとするものです。普通の手ばかり打っていては、上手はハンディキャップ戦に勝てません。そういう手もアルファ碁の訓練データの中にあることになります。さらに言うと、rollout policy を作るために policy networkの訓練に使った KGS とは別の有料囲碁サイトの対局データを使っている。
ニューラルネットワークの訓練データの選び方については、ディープマインド社の緻密な戦略があるのではないかと思いました。あくまで想像ですが・・・・・・。
| AI研究とは試行錯誤 |
ディープマインド社の研究報告を読むと、AI研究というのは「試行錯誤の積み重ね」が非常に重要だと思いました。たとえば policy network を構成する「畳み込みニューラルネットワーク」ですが、なぜ隠れ層が12なのか、入力層が48プレーンなのはなぜなのか、説明はありません。おそらく数々の試行錯誤の上に、このようなアーキテクチャに落ち着いたのだと思います。
value network について言うと、訓練データの作り方が独特だということは上の説明だけでもよく分かります。1手だけ SL policy network を使わずに、あえて「合法手をランダムに打つ」のはなぜでしょうか。画像認識などのAI研究において、訓練データにランダムな "ノイズ" を加えることがあります。そうした方が入力データの少々の誤りやデータ間の偶然の一致に対しても判定がブレない "強い" ニューラルネットワークを構成できるからです。合法手をランダムに打つのはそれを連想させますが、囲碁の勝率判定をする value network の場合にはどのような具体的効果があるのでしょうか。数手の合法手をランダムに打ったらどうなるのか、なぜ1手なのか。これもいろいろと試した結果のように思えます。
盤面の優劣判定に value network とロールアウトを併用し、しかもλというチューニング・パラメタをいろいろと "振ってみた" のも試行錯誤です。おそらくディープマインド社は、value network だけの優劣判定で最強の囲碁プログラムを作りたかったのではないでしょうか。それでこそ、ニューラルネットワークの技術に長けたディープマインドです。それが出来たなら、研究報告のタイトルどおり「ディープ・ニューラルネットワークと木検索で囲碁を習得」したと言える。しかし想像ですが、そのような value network を開発できなかったのではと思います。他のコンピュータ囲碁プログラムで一般的なロールアウトを併用せざるを得なかった。従って「ディープ・ニューラルネットワークとモンテカルロ木検索で囲碁を習得」が、より正確です。ロールアウトを使ったということは、確率的アルゴリズムには違いないのだから。
実際の対局に "最強の" RL policy network を使わなかったのも、コンピュータ囲碁プログラムとの実戦を重ねて行きついた結論でしょう。実戦に使える RL policy network を開発しようとしたが、それが出来なかったとも考えられます。
もちろんAI研究だけでなく、科学の研究には試行錯誤がつきものです。特に生命科学や物理・工学系の学問ではそうです。このブログでいうと、No.39「リチウムイオン電池とノーベル賞」で書いたリチウムイオン電池の開発物語はまさにそうでした。しかし「囲碁をAIでプレーする」というのは、純粋に論理の世界です。そこに未知の生命現象とか、解明されていない物理現象とか、そういうものは一切からまない。それにもかかわらず試行錯誤の世界だとみえる。しかもその試行錯誤は、まだ途中段階のようです。そのあたりが印象的でした。
逆の見方から言うと、こういった試行錯誤を、発散しないように、常に正解につながりそうな道にガイドした研究リーダ(ディープマインドのデミス・ハサビスCEO)の存在は大きいと感じました。
| コンピュータ技術を結集 |
アルファ碁が、決して突然新しいものが生まれたのではないこともよく理解できました。それはコンピュータ囲碁の歴史を調べてみると分かります。基本となっているアルゴリズムは、まずロールアウト(プレイアウトと呼ばれることが多い)です。これは1993年にアメリカのブリューグマンが発表した論文が発端です。「次の手以降をランダムなプレイで最後まで打って勝敗を判定し、次の手の有効性を判断する」という、この驚くような発想が、現代のコンピュータ囲碁の原点となりました。次にモンテカルロ木検索(MCTS)ですが、これは2006年のフランスのクローンの論文が最初です。ここにおいて、ロールアウトと木検索をどういう風に組み合わせるかという、アルゴリズムの基本が確立しました。どの手をロールアウトするかの判断にUCB(Upper Confidence Bound)を使ったのもクローンです。
ディープマインドがやったのは、そこに深層強化学習を持ち込むことでした。まず機械学習によってアマ高段者が打ちそうな手を精度よく予測できるニューラル・ネットワークを作り(= policy network)、それとロールアウトを使って盤面の優劣を計算できる別のニューラル・ネットワークを作った(= value network)。ディープマインドの深層強化学習は確かに大きなブレークスルーですが、アルファ碁の全体の枠組みは、先人の発想した技術(ロールアウトとMCTS)にのっとっていることがよく分かります。
さらに付け加えると、アルファ碁の数々のチューニングや試行錯誤とその検証は、世に出ているコンピュータ囲碁プログラムとの対戦で行なわれています。アマチュア有段者並みに強いコンピュータ囲碁プログラムがあったからこそ、アルファ碁は開発できた。人間相手に検証するのではとても開発できなかったでしょう。人間相手に戦うのは最後の最後です。
もっと言うと、No.180「アルファ碁の着手決定ロジック(1)」に書いたように、RL policy networkの開発ではオープンソースのコンピュータ囲碁プログラム・Pachiとアルファ碁を対戦させて、RL のチューニングや検証がされました。"オープンソース" がキーワードです。つまりソースコードが公開されているので、Pachiをディープマインド社のコンピュータの中に取り込み、一部を修正して、アルファ碁と自動対戦を繰り返すようなことができるわけです。こういったあたりもアルファ碁の開発に役だったと考えられます。
「畳み込みニューラルネットワークによる深層学習」は、画像認識の分野で発達してきたものです。画像認識は手書き文字の認識にはじまって、自動運転にも応用されようとしています。要するに「人間の眼と、それに関係した脳の働きを模擬する技術」です。現代のAI研究で最もホットな分野と言っていいでしょう。
コンピュータのハードウェア技術も見逃せません。研究報告によると「分散型のアルファ碁」は、複数のコンピュータの複合体の超並列処理で実行され、そCPUの数は合計1202、GPUの数は176とあります。CPU(Central Processing Unit)は通常のパソコンなどの演算LSIであり、ここで全体の制御と、ロールアウトを含むモンテカルロ木検索が実行されます。
GPU(Graphics Processing Unit)はニューラルネットワークの演算を行う部分です。ここでなぜ "Graphics" が登場するのかと言うと、GPUはコンピュータで3次元の図形画像をリアルタイムに(たとえばマウスの動きに追従して)回転させたりするときに働く演算ユニットだからです。3次元図形は、コンピュータ内部では微小な表面3角形の集合として定義されています。その数は数10万とか数100万になることも多い。その微小3角形の内部を、視線の向き、光の方向、3角形の位置から計算したグラディエーションで塗る。これを全部の3角形に行うことで、いかにもなめらかに陰影がついた3次元画像が表示されるわけです。このすべての処理を1秒間に10回以上繰り返します(でないと、なめらかに動かない)。そのためのユニットがGPUです。
つまりGPUは、比較的単純な処理を、同時平行的に、大量に、超高速に行うために開発された画像処理用LSIです。それをニューラルネットワークの計算に応用した。特に、画像認識に使われる「畳み込みニューラルネットワーク」は GPU との相性がよい。この応用は何もディープマインドだけではないのですが、もしGPUの技術がなければ「コンピュータ囲碁プログラムにニューラルネットワークを持ち込む」のは "絵に書いた餅" に終わったに違いありません。コンピュータ・ゲームやコンピュータ・グラフィックスの世界で長年培われてきた技術によってアルファ碁が成立したことは確かです。
逆の視点から言うと、このようにコンピュータ技術を結集しているということは、アルファ碁の経験から新たなコンピュータ技術が生まれてもいいわけです。たとえば上に書いたGPUですが、GPUがあったからこそアルファ碁が "絵に書いた餅" ではなくなったことは確かでしょう。しかしそのGPUでもニューラルネットワークの計算は遅い。RL policy network の計算に3ミリ秒もかかるから、RL policy network によるロールアウトを近似する value network が作られたわけです(value network の説明参照)。value network による勝率の推定は、RL policy network によるロールアウトを繰り返して勝率推定するより 15,000倍速いと報告に書かれています。
そうであれば、今より10,000倍程度速く RL policy network が計算できたとすると、value network は不要になり(ないしは補助的なものになり)、それが「最強のコンピュータ囲碁」になると考えられます。10,000倍速くするには「アルファ碁が採用した規模の "畳み込みニューラルネットワーク" を演算できる専用LSI」を開発すれば可能なのではないでしょうか。10,000倍とまではいかなくても、1000倍速く計算可能な専用LSI・数10個の並列処理でいいのかもしれない。コンピュータ囲碁のためにそんなことをする会社はないと考えるの早計です。「畳み込みニューラルネットワーク」は、画像認識の中核的なアルゴリズムです。その画像認識が超重要技術になるのが自動運転です。そしてディープマインドの親会社のグーグルは(自動車会社ではないにもかかわらず)自動運転の研究を進めていることで有名です。ひょっとしたらグーグル・ディープマインドは、そういった専用ハードウェアの開発を始めているのかもしれません。そのときに必須になるのは「畳み込みニューラルネットワーク」の動作についての深い専門知識なのです。
憶測で話を進めることには意味がありませんが、要するにアルファ碁の開発が「単に囲碁の世界に閉じたものではない」ということを言いたいわけで、それは全く正しいと思います。
画期的だが、道は遠い
アルファ碁は画期的な技術であり、AI研究のターニングポイントを越えたと思います。しかしそこを越えてみると、その先はまだまだ長いと感じました。その先とは人の「知性」と呼ばれている領域に入ることです。
No.174「ディープマインド」で、ディープマインド社のAI技術が「Atari社のビデオゲームのプレーを学習した」ことを書きました。「コンピュータ画面に表示される得点を知ることによって、ゲームのルールや遊び方を学習した」わけです。現在、ディープマインドはグーグルの子会社ですが、グーグルが買収するきっかけとなったのは「最高経営責任者のラリー・ペイジ氏が、ある種の人間性の萌芽を思わせるAIの登場に感銘を受けた」ことのようです(No.174)。2016年5月末のNHKスペシャルで、将棋の羽生 善治さんがディープマインド社を訪問する様子が出てきましたが(デミス・ハサビスCEOと羽生さんがチェスをプレーしていました)、そこでもAtari社のビデオゲームの習得の様子が解説されていました。
この話と、研究報告の題名である「Mastering the game of Go」の "マスター" とは、意味がかなり違います。アルファ碁は、2840万のKGSの盤面データと、800万の東洋囲碁の盤面データ(いずれもアマチュア囲碁プレーヤの打ったデータ)から、囲碁の戦い方を学習したわけです。Atari社のゲームの場合のように「ゲームのルールや遊び方を学習した」とはとても言えない。その意味で「Nature ダイジェスト 2016年3月号」の記事(上に引用)にあった「Atari社のゲームの習得と囲碁の習得を同一視するような書き方」は間違いだし、少なくとも大きな誤解を招く言い方です。
画期的な成果だが、まだ道は遠い。そのことはディープマインドのCEOであるデミス・ハサビス氏が一番実感していることでしょう。どこかのインタビューで、彼はそういう発言をしていたと記憶しています。
人の知性のすばらしさ
実は、ディープマインド社の研究報告を読んで一番感じたのは、アルファ碁と対戦できるプロ棋士の「知力」の素晴らしさでした。ここまでやっているコンピュータ囲碁プログラムと「戦える」こと自体が驚きというのが率直な感想です。相手はプロセッサーを1400個近くも並列処理させる、超高速コンピュータです。その相手に勝てることもある(2016年3月のイ・セドル 九段の一勝)。
人間の知性や知力の奥深さはすごいし、その秘密を解明するにしても、まだまだ先は遠いと思いました。
欧米に囲碁を広める努力をしたのは・・・・・・
これからは余談です。このディープマインド社の研究報告を読んでみようという気になったのは、アルファ碁とイ・セドル 九段の対決がきっかけでした。その対局のネット解説(マイケル・レドモンド 九段)を見ていて思ったのですが、英語の囲碁用語には日本語がいろいろとあるのですね。aji(アジ、味)とかdamezumari(ダメ詰まり)とかです。普段、英語の囲碁用語に接する機会などないので、これは新しい発見でした。
ディープマインド社の研究報告にも、atari(アタリ、当たり)とか nakade(ナカデ、中手)とか dan(段)とか komi(コミ)とか、いろいろ出てきます。最も驚いたのは byoyomiです。「持ち時間を使い切ったら一手30秒の秒読み」と言うときの「秒読み」です。世界トップクラスのイギリスの科学誌「Nature」に byoyomi(= 日本語)が出てくるのです。日本語について言うと、No.174 にも書きましたが、そもそも英語で囲碁を示す Go(AlphaGo の Go)が「碁」の日本語発音です。
囲碁の発祥地は中国です。しかし、囲碁英語に日本語がたくさんあるという事実は、欧米に囲碁を広めたのは日本人棋士、ないしは日本で囲碁を学んだ欧米人だということを如実に示しています。欧米に囲碁が広まったのはその人たちの功績だった。日本のプロ棋士では、特に岩本薫・元本因坊です。
そうして広まってくると、欧米でも囲碁の深淵さが理解されるようになり、コンピュータ囲碁プログラムを開発する人が欧米に現れた。それがAI研究者のチャレンジ意欲をかき立て、そして英国・ロンドンでアルファ碁が誕生した・・・・・・。
| ◆ | 欧米に囲碁を広めた人たちの努力(日本人プロ棋士、欧米人を含む) ↓ | ||
| ◆ | 欧米で囲碁が普及 ↓ | ||
| ◆ | コンピュータ囲碁プログラムの出現(欧米で) ↓ | ||
| ◆ | AI研究者が囲碁に挑戦 ↓ | ||
| ◆ | ディープマインド社とアルファ碁の出現 |
というのは、一本の線で繋がっているのではないでしょうか。これは決して「風が吹いたら桶屋が儲かる」式の話ではなく、ロジカルな繋がりだと思うのです。
ディープマインド社はアルファ碁の開発で得られた知見を社会問題や産業分野に応用しようとしています。そのルーツをたどると、一つとして「日本のプロ棋士、ないしは日本で囲碁を学んだ人たちが、欧米に囲碁を普及させた努力」がある。そう考えられると思いました。
| 補記:AlphaGo Zero |
AlphaGo を開発した DeepMind は、2017年10月に AlphaGo Zero を発表しました。このシステムに組み込まれた知識は「囲碁のルール」でだけです。つまり、
| 人間の対局データ(棋譜)を使っていない | |
| 囲碁の常識(いわゆる "ドメイン知識")も使っていない |
システムです。にもかかわらず、AlphaGo 及びそれ以降に作られた改良版のすべてを凌駕する強さです。
本文中に、AlphaGo が高段者の棋譜やドメイン知識を利用していることを念頭に「画期的だが、道は遠い」と書きましたが、道は遠いどころか、ゴールは間近にあったわけで、「遠い」という推測は全くのハズレでした。このことの教訓は、
AI 技術の進歩は急激であり、いつなんどき驚くような技術が現れるかわからない
ということです。現状の技術内容だけから安易な判断は慎むべきだと思いました。
タグ:tree policy アルゴリズム 論文 AlphaGo Zero 解説 AlphaGo ディープマインド DeepMind nature ニューラルネットワーク policy network value network モンテカルロ木検索 Monte Carlo Tree Search MCTS rollout playout rollout policy ロールアウト 深層学習 強化学習 機械学習 畳み込みニューラルネットワーク KGS Tygem 確率的勾配降下法 Upper Confidence Bound UCB 画像認識 GPU イ・セドル デミス・ハサビス 羽生善治 自動運転 グーグル アルファ碁 仕組み
No.180 - アルファ碁の着手決定ロジック(1) [技術]
アルファ碁(AlphaGo)
No.174「ディープマインド」で、英国・ディープマインド社(DeepMind)のコンピュータ囲碁プログラム、アルファ碁が、世界最強レベルの囲碁棋士である韓国の李世乭(イ・セドル)九段に勝利した話を書きました(2016年3月。アルファ碁の4勝1敗)。

| ||
|
AlphaGo vs イ・セドル9段(右)第1局
(YouTube)
| ||
このアルファ碁に盛り込まれた技術について、No.174 では「Nature ダイジェスト 2016年3月号」に従って紹介しました。要約すると、ディープマインド社のやったことは、
| ◆ | 次に打つ手を選択して碁盤を読む能力をもったニューラルネットワークを、深層学習と強化学習によって作った。 | ||
| ◆ | このニューラルネットワークを、手筋のシミュレーションによって最良の手を選択する市販の囲碁プログラムの探索アプローチと組み合わせた。 |
となります。非常に簡単な説明ですが、そもそも「Nature ダイジェスト」の解説が簡素に書いてあるのです(それが "ダイジェスト" の意義です)。
もうちょっと詳しく言うとどういうことなのか、どこに技術のポイントがあるのか、大変気になったので「Nature 本誌」の記事を読んでみました。ディープマインド社が投稿した「ディープ・ニューラルネットワークと木検索で囲碁を習得した - Mastering the game of Go with deep neural network and tree search」(Nature 2016.1.28)という研究報告です。以下、この報告に書かれているアルファ碁の仕組みを分かりやすく書いてみたいと思います。以下の要約によって「Nature ダイジェスト」の説明を詳しく言うとどうなるのかが見えてくると思います。たとえば「次に打つ手を選択して碁盤を読む能力をもったニューラルネットワーク」というのは、実は「次に打つ手を選択するニューラルネットワーク」と「碁盤を読む能力をもったニューラルネットワーク」の二つあることも分かります。

前提
前提事項が2つあります。まず1点目ですが、「Nature」の研究報告(2016.1.28)が発表された時点で、イ・セドル 九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。相手は樊麾二段(ファン・フイ。中国出身でフランス国籍。フランス在住。中国棋院二段)で、その成果を受けての報告です。おそらくディープマインド社はイ・セドル 九段との戦いまでの間に、アルファ碁のロジックの強化やチューニングを繰り返したと思います。囲碁のトップレベルの国は中国・韓国・日本であり、韓国のイ・セドル 九段は樊麾二段とは "格" が違います。イ・セドル 九段との戦いという、ディープマインド社にとっての(そして親会社のグーグルにとっての)晴れ舞台に向けて、アルファ碁の強化を繰り返したことが十分に想定できるのです。以下の研究報告の解説は2015年10月時点の技術内容と考えるべきであり、それ以降の強化は含まれないことに注意が必要です。
2番目は専門用語です。ディープマインド社が「Nature」に投稿したのは「囲碁を素材にしたニューラルネットワークや強化学習の研究報告」なので、専門用語や数式がいろいろ出てきます。しかしそういった用語や数式は、以下の要約では必要最小限にしました。さらに、研究報告の内容を順番に説明するのではなく、そこに書いてあることを、補足を交えて再構成しました。ニューラルネットワークや強化学習については、各種Webサイトに紹介やチュートリアルがあります。また多数の書籍も出版されているので、そちらを参照ください。
4つの技術
ディープマインド社の研究報告を読むと、アルファ碁は次の4つの技術の組み合わせで成り立っていることが分かります。
| ① | policy network | ||
| ② | value network | ||
| ③ | モンテカルロ木検索(Monte Carlo Tree Search : MCTS) | ||
| ④ | rollout policy |
このうち、①policy network、②value network はディープマインド社の独自技術です。一方、③モンテカルロ木検索と ④rollout policy は、現在、世に出ている多くのコンピュータ囲碁プログラムが採用しています。もちろん③④についてもディープマインド社独自の工夫や味付けがあるのですが、基本的なアイデアは既知のものです。「Nature ダイジェスト」に「ニューラルネットワークと既存の検索アプローチを組み合わせた」という意味のことが書かれていましたが、これは ①② と ③④ を組み合わせたことを言っています。「Nature ダイジェスト」の要約に①~④を対応させると次の通りです。
| ◆ | 次に打つ手を選択して(= policy network)碁盤を読む能力をもった(= value network)ニューラルネットワークを、深層学習と強化学習によって作った。 | ||
| ◆ | このニューラルネットワークを、手筋のシミュレーションによって最良の手を選択する(= rollout policy)市販の囲碁プログラムの探索アプローチ(= MCTS)と組み合わせた。 |
以降、この4つの技術について、順に説明します。なお、「④rollout policy」は「③モンテカルロ木検索」の一部とするのが普通ですが、説明の都合上、分けてあります。
policy network
まず言葉の意味ですが、ポリシー(policy)とは、着手を決めるロジック、ないしはアルゴリズムのことです。現在の盤面の情報をもとに、次にどこに打つべきかをコンピュータ・プログラムで決める、その決め方をいっています。またネットワーク(network)とは、AI(人工知能)の研究で多用されるニューラルネットワーク(neural network)のことです。つまり、
| policy networkとは、現在の盤面の情報をもとに、次にどこに打つべきかを決めるためのニューラルネットワーク |
です。ディープマインド社がコンピュータ上に構築した policy network は、ニューラルネットワークの中でも「畳み込みニューラルネットワーク(Convolutional Neural Network. CNN)」と呼ばれるタイプのもので、画像認識の研究で発達しました。画像認識で、たとえば画像の中にある猫の顔を認識しようとすると、それは画像いっぱいにあるもしれないし、画像のごく一部かもしれない。また猫の顔が移動しても(どこにあっても)、大きさが違っても、少々変形していても認識できないといけない。画像の大域的な特徴と局所的な特徴を同時にとらえ、かつ移動や変形、拡大縮小があったとしても普遍的な特徴をとらえる。「畳み込みニューラルネットワーク」はこのようなことが可能なニューラルネットワークです。ディープマインド社が使ったのは隠れ層が12層あるもので(いわゆるディープ・ニューラルネットワーク。Deep Neural Network。DNN)、図示すると以下のようです。
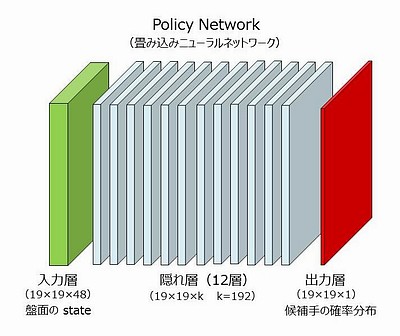
| ||
|
kは "フィルタ" の数で、プロとの実戦では 192 が使われた。入力層から第1隠れ層への "カーネル" は5×5である。従って、周辺に 0 を2つパディングした 23×23×48 が入力層となる(19+2+2=23)。5×5×48個の重み値(フィルタ)と、入力層の5×5×48の部分領域の値を掛け合わせて合計した値を活性化関数(ReLU関数)への入力として、第1隠れ層の1つの値が決まる。この操作を、入力層の部分領域を上下左右に1ずつずらしながら19×19回繰り返すと、第1隠れ層の1つのプレーンができる。さらにこの計算全体を、フィルタをかえて192回繰り返すと第1隠れ層ができあがる。
第1隠れ層から第12隠れ層に至るカーネルは3×3である。出力層へのカーネルは1×1であるが 19×19 個の異なったバイアスを使用し、また出力層の合計値が 1.0 になるように調整される。ニューラルネットワークの訓練とは、訓練データが示す出力(19×19のどこか1箇所が1で残りは全部ゼロ)と最も近くなるように、フィルタ(重み)およびバイアスの値を調整することである。 このニューラルネットの重みがいくつあるか計算してみると、第1隠れ層への重みは5×5×48×192、第2隠れ層から第12隠れ層については3×3×192×192×11(=11層)、出力層への重みは1×1×192である。さらに出力層には19×19のバイアスが加味される。これらをすべて合計すると約388万(3,880,489)である。388万個のパラメータ(重みとバイアス)を最適に決めるのがニューラルネットワークの訓練である。 なお、画像認識における「畳み込みニューラルネットワーク」で使われるプーリング層(画像を "サマライズ" する層)はない。19×19程度の "画像" をサマライズする意味はない。 | ||
このニューラルネットワークの出力層は 19×19×1 で、碁盤の 19×19個の交点(目)に対して 0.0 ~ 1.0の数値が出力されます。この数値は囲碁の熟練者がそこに打つ確率を表します。すべての交点の確率を合計すると1.0になります(いわゆる確率分布)。
入力層は 19×19×48 のサイズで、碁盤の19×19の交点が48層(48プレーン)があります。一つのプレーンの一つの交点は 1 か 0 の値をとります。コンピュータに詳しい人なら「19×19の交点のそれぞれに48ビットを割り当てた」と言った方が分かりやすいでしょう。No.174「ディープマインド」で紹介した「Nature ダイジェスト 2016年3月号」の記事では、「入力層は碁盤の黒石・白石の配置パターン」と受け取れる表現がありましたが、実際の入力層はそれよりもかなり複雑です。48のプレーンは以下のように構成されています。全ての情報は打ち手(次に手を打つ人)を基準に計算され、一手進むごとに再計算されます。
policy network の入力層の構成
の数 |
説明 |
| 1 | 打ち手の石(打ち手の石があれば 1) |
| 1 | 相手の石(相手の石があれば 1) |
| 1 | 空点(空点であれば 1) |
| 1 | すべて 1 |
| 8 | その交点に石が打たれてから現在までに進んだ手数。 |
| 8 | 石の呼吸点(上下左右の空点)の数。その交点の石と連結している石全体(いわゆる “連”)の呼吸点を表す。 |
| 8 | その交点に打ち手の石を打ったとしたとき、相手の石を取れる数。 |
| 8 | その交点に相手が石を打ったとしたとき、打ち手の石が取られる数。 |
| 8 | その交点に打ち手の石を打ったとき、その石と連結している石全体(連)の呼吸点の数。 |
| 1 | その交点に打ち手の石を打って相手の石をシチョウで取れるとき 1 |
| 1 | その交点に打ち手の石を打ってシチョウから逃げられるとき 1 |
| 1 | 合法手。その交点に打ち手の石を打つのが囲碁のルールで許されるとき 1。ただし打ち手の目をつぶす手は合法手とはしない。 |
| 1 | すべて 0 |
8つのプレーンで一つの数を表すものが5種類ありますが、いずれも「0, 1, 2, 3, 4, 5, 6, 7, 8以上」を表します。1 の場合は1番目のプレーンだけが 1、2 の場合は2番目のプレーンだけが 1、以下、8以上の時は8番目のプレーンだけが 1です。情報科学でいう one-hot encoding("8ビット" のうち 1 は一つだけ)になっています。
この構成で分かるように、入力層は単なる黒石・白石の配置パターンではありません。囲碁のルールが加味されています。さらに「シチョウに取る・シチョウから逃げる」や「ダメヅマリ(連結する石の呼吸点の数)」というような、ルールから派生する囲碁の常識(が判別できる情報)も含まれています。
以上の 19×19×48 の入力層の情報をディープマインド社の研究報告では盤面の "state" と読んでいます。これに従って、以下「盤面(state)」ないしは単に「state」と書くことにします。
当然ですが、盤面(state)の情報は、打った手の履歴が分かれば計算できます。アルファ碁は着手を決定する際に policy network を使うのですが、まず state を計算し(再計算し)、ニューラルネットワークの計算を行って、囲碁の熟練者がどこに打つかの確率を求める。これを着手ごとに繰り返すことになります。
SL policy network
ディープマインド社がまず作成した policy network は、教師あり機械学習(supervised learning)による policy network で、これを SL policy network と呼びます。以下、単に SL と書くこともあります。SL policy networkの「訓練データ」は、KGS Go Server からダウンロードされた、囲碁の対局データです。
KGS Go Serverは、もともと神奈川県茅ヶ崎市の囲碁用品店、棋聖堂が運営していた無料の囲碁対局サイト(Kiseido Go Server : KGS)で、現在はアメリカの篤志家と各国のボランティアが運営しています。このサイトには世界の囲碁愛好家が集まっていて、無料の囲碁対局サイトとしては最も広まっているものの一つです。
参加者はアマチュア30級(30k)から1級(1k)、アマ初段(1d)から九段(9d)までにレーティングされます。このレーティングは、KGSの独自のアルゴリズムにより対局が行われるたびに自動更新されます。KGS にはプロ棋士も参加しており、自ら参加を公表しているプロ棋士もいます。プロの段位は d ではなく p と表示します(レーティングはなく申請方式)。アマチュアの中には、コンピュータ囲碁のプログラムも参加しているようです。
ディープマインド社が SL policy network の訓練データとしたのは、KGS のアマチュア高段者(6段~9段。6d~9d)の約16万局の対局データで、それには2940万の盤面データがありました。このうち100万の盤面データは、できあがった SL policy network の評価に使用されました。従って実際の訓練データは「2840万の盤面データと、その場面で囲碁熟練者が実際に打った手」です。もっとも、囲碁には対称性があるので盤面を90度づつ回転した4つの盤面データ、およびそれらの裏返しを含めた合計8つの盤面データが教師データとして使われました。従ってSL policy networkにとっての訓練データの総数は2億2720万ということになります。訓練データの数が2840万とか2億2720万というと非常に多いようにみえますが、SL policy network のパラメータの数(重みとバイアス。上の policy network の図の説明参照)は388万もあります。これと比較すると約7倍とか60倍という数です。深層学習の訓練データの必要数はパラメータの数の数倍以上とされているようなので、この数はリーズナブルな数なのでしょう。
これら訓練データの state をあらかじめ計算しておき、policy networkを "教育" しました。つまり「出力層の確率分布」と「実際に打たれた手の確率分布(どこか1箇所が 1 で、その他は 0)」との誤差の総体が最も小さくなるように、ニューラルネットワークの重みを調整していったわけです。この調整には "確率的勾配降下法"(stochastic gradient descent。SGD。報告では ascent も何回か使われているが、同じ意味)という手法が使われました。こうして出来あがったのが SL policy network です。
この SL policy network が、どの程度の精度で熟練者の実際の手を予測できるかを、訓練データとしては使わなかった100万の盤面データで調べた値があります。それによると予測精度は57.0%とのことです。この定義ですが、実際に打たれた手に対応する SL policy network の出力層での確率(の100万個の平均値)だと読み取れます。とすると、出力層の最高確率の手を打てばアマチュア高段者の手がかなりの精度で近似できるということになります。57.0%は100万のテストデータの平均値なので、中にはハズレもあるでしょう。また、アマチュア高段者が打った手が最善手だとは限りません。しかしこの57.0%という数字は SL policy network が有効だということを示しています。想像するに、確率が上位の3つぐらいの手の中にアマチュア高段者が実際に打った手が極めて高い確率で含まれるのではないでしょうか。
興味あるデータがあります。もし SL policy network の入力層が48プレーンではなく11プレーン(石の配置が3プレーン、手数が8プレーン)ならどうなるかということです。それを実際にやってみると、予測精度は 55.7% になったとのことです。わずか 1.3% の違いなのですが、研究報告で強調してあるのは、この程度の予測精度のわずかな違いが囲碁の強さに大きく影響するということです。
予測精度をあげるためには、畳み込みニューラルネットワークの隠れ層を増やすという案も当然考えられます。しかしそうすると、policy network の計算時間が増えます。つまり、限られた時間内に「読める」手が少なくなる。ディープマインド社は超高速コンピュータシステムを使っているので、policy network の一回の計算は3ミリ秒で終わります。しかしあとから出てくるように、コンピュータ囲碁に適用するにはこの速度でも遅すぎるのです(その回避策もあとで説明します)。
入力層のプレーンが48や、畳み込みニューラルネットワークの隠れ層が12というのは、ディープマインド社が精度と速度のバランスを試行錯誤して決めたものだと想像できます。
| 補足ですが、No.174「ディープマインド」で紹介した「Nature ダイジェスト 2016年3月号」に「プロ棋士どうしの対局の3000万通りの局面を調べ」とあるのは間違いです(原文か訳か、どちらかの間違い)。SL policy network の訓練データは KGS Go Server のアマ高段者の対局データです。 |
RL policy network
RL policy networkとは、強化学習(reinforcement learning)の手法を使って、SL policy network をさらに "強く" したものです。基本的な方針は policy network 同士の「自己対局」です。policy network に従って碁を打つということは、policy network が示す確率分布に従って手を打つということになります。
まず初期値として RL = SL とします。そして「強化試合相手の集合(policy pool)」を設定し、初期状態ではSLをひとつだけ policy pool に入れておきます。
一回の「強化」は次のように進みます。policy poolの中から「強化試合相手」をランダムに選び、RLをその相手と128回対戦させます。この対戦過程の全盤面を記憶しておき、RLの対戦成績が最も高くなるように、RLのニューラルネットワークのパラメータ(重み)を調節します。つまり、勝った対戦では勝ちに至った手をできるだけ選ぶようにパラメータを調節し、負けた対戦では負けに至った手を選びにくいように調節するわけです。このあたり、ディープマインド社のCNNを使った強化学習の技術蓄積が生きているところです。
以上の強化を500回行うごとに、その時点でのRLを policy pool に入れます。この強化を1万回(1回あたりの対戦は128回)繰り返して、最終的なRLとします。従って「自己対戦」は128万回行ったことになります。もともと SL policy network は KGS Go Server の約16万局のデータをもとに訓練されたものでした。それからすると RL の作成で行った自己対局の128万回は断然多いことになります。
こうして作成された RL policy network を市販のコンピュータ囲碁プログラムと対戦させた結果が報告に載っています。Pachi というプログラムは、オープンソースの(ソースコードが公開されている)コンピュータ囲碁プログラムでは最強と言われていて、KGSのレーティングではアマチュア2段(2d)です。RL はPachi と対戦して 85%の勝率でした。一方、SL は 11%の勝率でした。RL policy network は SL policy network に比べて格段に強くなったと言えるでしょう。このように、すべてコンピュータ内部で自動的に行える「自己対局」を繰り返すことで強くできるアルゴリズムを作れることが、ニューラルネットワークをコンピュータ囲碁に持ち込む大きなメリットでしょう。
RL policy network はなぜ強くなったのかを推定してみます。SL policy network の最大の弱点は、機械学習の教師データとした「2840万の盤面における次の一手」が最善手とは限らないことです。教師データは、あくまでアマチュア高段者の実際の対局データ(約16万局)です。高段者と言えども、次の一手には悪手や疑問手が多数含まれているはずだし、中には "ポカ" もあるでしょう。それらを全部 "正しい" 教師データとして機械学習したのが SL です。
RL は SL 同士の自己対局で作られました。「SL に勝つような SLの修正版が RL」であり、そういった "カイゼン" を次々と繰り返していって完成したのが最終的な RL です。しかも "カイゼン" のための自己対局の数は、元の教師データの対局数より圧倒的に多い。この結果、元々の SL に含まれていた「疑問手・悪手・ポカ」を打つ傾向が薄まったと考えられます。RL が最善手を打てるとは言わないまでも「最善手を打たない傾向は、かなり弱まった」と考えられるのです。想像するに「アマチュア高段者が実際に打った手を予測できる」という点に絞れば、RL は SL より予測精度が悪いのかも知れません。RL の予測精度は研究報告には書いてないのですが、つまり「そういった議論は意味がない」ということでしょう。しかし RL が最善手を示す確率は SL よりも高い。おそらくそういうことだと考えられます。
強化学習というと何か新しい能力を獲得したように感じてしまいますが、この学習はあくまで自己対局によるものです。「SLには無かった良い面」を新たに獲得したとは考えにくい。むしろ「SLの悪い面」を少なくした、これが強化学習の意義だと思います。市販のプログラム、Pachi との対戦で 85%もの勝率をあげたのは、このような理由だと推定できます。
Pachi との対戦での重要な注意点は、市販のコンピュータ囲碁プログラムは、打つ手の先を次々と読んで有力な次の手を判断していることです。一方の policy network は「手を先読みする」ことは一切せず、現在の盤面(state)だけから、次に打つべき有力手を計算します。つまり人間同士の囲碁の勝負でいうと、盤面を見て直感で打つことに相当します。直感で手を打つ RL policy network が、手を先読みする市販のコンピュータ囲碁プログラムと対戦して85%の勝率をあげたということは、RL policy network を手を先読みする機能と組み合わせれば非常に強いコンピュータ囲碁プログラムができるだろう、と推定できるのです。
ディープマインド社がやったことはまさにそういうことであり、市販のコンピュータ囲碁プログラムで「手を先読みする」ときに広く使われているモンテカルロ木検索(Monte Carlo Tree Serch. MCTS)と policy network を組み合わせることでした。
次にその「モンテカルロ木検索」ですが、その前に、モンテカルロ木検索で使われる「ロールアウト」です。ロールアウトもディープマインド社の発明ではなく、現在のコンピュータ囲碁プログラムで一般的に使われている手法です。ディープマインド社の研究報告にロールアウトの具体的な説明はなく、既知のものとしてありますが、モンテカルロ木検索の理解のためには必須の事項なので、以下に説明します。
ロールアウト(rollout)という手法
ロールアウトとは、モンテカルロ木検索で使われる重要な手法です。プレイアウト(playout)と呼ぶことが多いのですが、ディープマインド社の研究報告に従ってロールアウトとします。ロールアウトとは次のようなものです。
| ◆ | ある盤面において次に打つ候補手が複数あるとする(たとえば合法手のすべて)。 | ||
| ◆ | どの候補手が一番有力かを見極めるために、候補手の次から始まって黒白交互に合法手をランダムに打って終局まで進め、その勝敗をみる(=ロールアウト)。 | ||
| ◆ | これを何回か繰り返して勝率を計算する。そして勝率のよい候補手ほど有力とする。別の言い方をすると、候補手を打ったときの盤面の優劣を、そこからのロールアウトの勝率で判断する。 |
この「黒白交互に終局まで合法手をランダムに打って勝敗をみる」のがロールアウトです。ランダムということは、候補手の有力な度合いを確率的に判断するということです(自分の目をつぶす手は合法手から除外します)。かつ、序盤であれ中盤であれ、また終盤であれ、とにかく最後までヨセてみる。それを繰り返してその勝率で候補手の有力度合をみるということです。これは人間の思考とはかなり違います。人間なら「最後までヨセたらどうなるか」という思考で打つのは終盤だけです。序盤・中盤でそんなことは考えない(考えられない)。ロールアウトはコンピュータ囲碁の着手に人間とは違った要素を持ち込むと考えられます。
ロールアウトという "乱暴な" 手法がなぜ成立するのかと言うと、囲碁というゲームが「どこに打ってもいいから合法手を順に打っていくと終局に至るゲーム」だからです。囲碁は着手をするたびに打てる所が少なくなっていきます。だから成り立つ。ちなみに将棋だとこうはいきません。将棋の合法手を互いにランダムに指していって王様が詰むという保証はどこにもありません(逃げられる王手を見逃すのは将棋のルール違反)。
ロールアウトを使うと、次のような着手決定アルゴリズムが考えられます。まず許された時間に何回ロールアウトが可能かを見積もります。囲碁は持ち時間(考える時間)が決まっています。たとえばアルファ碁とイ・セドル 九段の対戦では、持ち時間はそれぞれ2時間でした。囲碁の平均手数を200手とすると、黒白それぞれ100手ですから、1手あたり許される思考時間は72秒です。もちろんそれは平均であって、思考時間の配分もコンピュータ囲碁プログラムを設計する時のポイントです。とにかく許される思考時間の間に、たとえば10万回のロールアウトが可能だとしましょう。そして着手可能な合法手(囲碁のルール上許される手)は100手だとします。そうすると、100手のそれぞれで1000回のロールアウトを行い、最も勝率の良い手を着手する・・・・・・。
もちろん、こんな単純なアルゴリズムでは強いコンピュータ囲碁プログラムにはなりません。なぜなら「無駄なロールアウト」をいっぱいやっているからです。ルール上許される合法手といっても、アマチュア初心者でも絶対打たないような手がいっぱいあります。そんな手にたくさんのロールアウトを繰り返すのは時間の無駄です。ロールアウトはあくまで「確率的判断」で有力な手を見極めようとするものです。有力そうな手にはできるだけ多くのロールアウトを割り当て、ダメそうな手は早々に切り上げる。そうしないと確率的に最善手に近づくことができません。つまり、まず候補手をそれぞれ何回かロールアウトして様子を見て、その中から良さそうな手を選択し、さらにそこをロールアウトする・・・・・・。そのようなアルゴリズムが必要です。しかしロールアウトによる勝敗判断はあくまで確率的なので、何回かロールアウトしてみてダメそうな手であっても、もっとロールアウトすると勝率が良い手に "化ける" かもしれないのです。では、どうしたらよいのか。
実は、どの手をロールアウトすべきか、それを決めるための「数学的に最良な方法」が知られています。それが、候補手の Upper Confidence Bound(UCB。信頼上限)という値を計算し、常にUCB値が最大となる手をロールアウトするというアルゴリズムです。UCBは1回のロールアウトのたびに変化していく値で、次の式で計算されます。
| 候補手i のUCB | |||
| 候補手i をロールアウトした数 | |||
| 候補手i のロールアウトによる勝ち数 | |||
| ロールアウトの総数(logは自然対数) | |||
| 定数(理論的には2の平方根だが囲碁プログラム依存) |
その時点で「UCB最大の手」をロールアウトします。もしUCBが第1項(Wi/Ni)だけだと「その時点で最も勝率が高い手を常にロールアウトする」ことになってしまいます。しかし第2項があるためにそうはなりません。第2項にはNiの逆数があるので「その時点でロールアウトの配分が少ない手」ほどロールアウト候補として有利になります。しかし第2項を見ると分子には logN があります。この意味するところは、ロールアウトの配分率が少ない手が有利だとはいうものの、ロールアウトの総数(N)が大きくなると第2項の効果は相対的に薄れていくということです(logN ではなく N だと薄れない)。k は第2項をどの程度重要視するかという定数です。k が小さいと、より勝率の高い手をロールアウトするようになり、k が大きいと勝率が小さくても "チャレンジ" するようになる。このあたりの決め方がコンピュータ囲碁プログラムのノウハウとなっています。第1項を開拓(exploitation)、第2項を探検(exploration)と呼んだりします。
UCB についての補足です。UCB(Upper Confidence Bound。信頼上限)は、教師なし機械学習の理論の一つである「多腕バンディット問題」で出てくる値です。バンディット(Bandit)は山賊の意味ですが、ここではスロットマシンのことです。山賊は旅人や商人からお金を巻き上げるので、これをスロットマシンになぞらえたものです。
スロットマシンにはアーム(腕)があり、コインを入れてアームを操作すると "当たり" か "ハズレ" になる。「多腕」とは、そのアームが複数あるという意味です。説明をシンプルにするために、以降同じことですが、複数のスロットマシンがあることとします。
ポイントは、複数のスロットマシンで "当たり" の出る確率がそれぞれ異なっていて、事前にはその確率が分からないことです。プレーヤーの持っているコインは限られていますが、スロットマシンの台数に比べて十分な量とします。では、この複数のスロットマシンを相手にどういう戦略でプレーをすれば最大の利得が得られる(=当たりの回数を最大化できる)でしょうか。これが問題です。
とりあえず、まず全部のマシンを試してみるのが妥当でしょう。そうすると、たとえば2台のマシンが "当たり" だったとします。では残りのコインでその2台を集中的に試すべきでしょうか。
もちろんこんな戦略ではダメです。最初に "当たり" が出なかったマシンにも高い確率のものがあるかもしれないからです。また2台を試してみてずっと "当たり" が出なかったとき、いつ諦めるべきかという問題もある。では、どうするか。
要は、結果として "当たり" の出る確率が高いマシンにより多くのコインを投資するようにプレーを誘導できればいいわけです。それ実現する "数学的に正しい戦略" が「UCB を判定し、常に最大UCBのマシンを試す」というものなのです。
これがスロットマシンの問題だとすると実用性はありませんが、この理論の応用は現代のビジネスで使われています。その例ですが、今、あるWebページがあり、そのページには50のコンテンツがあるとします。1画面には10のコンテンツが表示できるので、別画面に移るときにはクリックして移ることとします(全部で5つの画面)。最初に表示される第1画面は一般的にコンテンツの良し悪しにかかわらずクリックされる確率が高く、第2、第3となるにつれて急速に確率が落ち、第5画面が最低になる。
この状況で、Webページのページビューを最大化するにはどうすべきでしょうか。そのためには「本質的に最も人気のあるコンテンツを上位画面に集める」ことができればよい。しかしどれが人気が出るコンテンツかは、事前にはわからない。こういう場合サイトの設計者としてはログをとり、そのログを見ながらコンテンツの表示順位を決めますが、よく閲覧されたコンテンツを決めるファクターは「人気がある」と「過去に上位に表示された」の2つがあるので、この2つのバランスをどうとって判断するか、そのアルゴリズムが問題です。
これは、条件はスロットマシンよりは複雑ですが、本質的に「多腕バンディット問題」と同じです。教師なし機械学習はAIの一部と言ってもいいわけで、このような「AI技術を使ってページビューを最大化」しているサイトは多々あるはずです。
コンピュータ囲碁の話に戻ります。この数学的裏付けにもとづいたUCBを使うアルゴリズムでも、まだ問題点があります。一つはランダムに合法手を打ってロールアウトするところです。これではいくらなんでも単純すぎる。囲碁には「常識的な手」があります。相手の石が取れるなら取るとか、ノゾキにはツグとか、また、アマチュアで段位を持っている人なら誰でも知っている手筋も多い。そういう常識的な手が打てるなら打つ。そうした方がランダムなロールアウトより盤面の優劣の判断がより正確になると考えられるのです。
実際、現代のコンピュータ囲碁プログラムでは、ランダムではなく一定のロジックに基づいてロールアウトをしています。このロジックをロールアウト・ポリシー(rollout policy)と呼びます。後で書きますが、アルファ碁もロールアウト・ポリシーによるロールアウトを使っています。ロールアウト・ポリシーの必須条件は、高速に計算できることです。ロールアウトによる勝率の推定は、あくまで確率的なものです。ロールアウトの回数が多いほど推定が正確になるので、高速性が大変重要です。
さらに上のアルゴリズムの問題点は、候補手をリストアップする段階で「合法手すべて」としていることです。少なくともロールアウト総数が少ない初期の段階では、それらを均等に扱っている。合法手の中には「囲碁の常識上ダメな手」があるはずです。「囲碁の常識上ダメな手」がロールアウトなしで高速に判別できれば、候補手の中でもロールアウトの優先度を落とすべきでしょう。このロジックも、現代のコンピュータ囲碁プログラムで採用されています。
以上の「常にUCB値を再計算しながら、それが最大となる候補手をロールアウトし、その勝敗の数で手の有力度合いを判定する」アルゴリズムに「手を先読みする」機能を加えたのが、次の「モンテカルロ木検索」です。
(次回に続く)
No.179 - 中島みゆきの詩(9)春の出会い [音楽]
今回は、No.168「中島みゆきの詩(8)春なのに」の続きです。No.168では中島みゆき作詞・作曲の、
をとりあげました。2曲とも "春の別れ" をテーマとした詩です。そのときに別の中島作品を連想したのですが、今回はそれを書きます。2曲とは全く対照的な "春の出会い" をテーマとする曲、
です。
ふたりは
「ふたりは」は、1990年に発売されたアルバム『夜を往け』に収録されている曲です。また、その年の暮れの第2回目の「夜会」で最後に歌われました。その詩を引用すると以下の通りです。
さっき書いたように、この曲は1990年の第2回目の「夜会」の最後に歌われました。その前の年、1989年の夜会(第1回)の最後は『二隻の舟』です。『二隻の舟』は「夜会」のために書かれた曲で、1990年の「夜会」の最初の曲でもあり、3年後にアルバムに収録されました(『EAST ASIA』1992)。『ふたりは』という曲は、"二人" ないしは "あなたと私" のことを詩にしているという点で『二隻の舟』と似ています。アルバム『夜を往け』の発売(1990.6.13)は「夜会 1990」(1990.11.16~)より先なのですが、「夜会」の最後に歌うことを想定して書かれたのかもしれません。
シャンソン
『ふたりは』という曲を初めて聴いたとき、詩で描かれた物語について、"どこかで聴いた(見た)ような・・・・・・" という既視感がぬぐえませんでした。
男と女の物語です。男は、社会や町、ないしはコミュニティーの "アウトサイダー" です。最も極端なのはヤクザですが、そこまで行かなくても、不良、チンピラ、アウトロー、嫌われ者であり、蔑んだ言い方では「ゴロツキ」です。
対するのは「性的に奔放な女性」です。職業としては「売春婦」ないしは「風俗嬢」ですが、そうでなくても「あばずれ」とか「ふしだら女」と呼ばれる女性。「誰とでもやる女」と見られていて、蔑んだ言い方では「バイタ(売女)」です。
要するに、社会や町やコミュニティーの表ではなく裏、光の部分ではなく陰の部分を象徴するような二人です。しかし二人の心の奥底には非常にピュアな部分があり、人を愛したい、人から愛されたいとの思いを秘めている。人々からは蔑まれてはいるが、内心は愛を求めている。二人とも "夢破れて"、夢とは正反対の状況で生きている。そんな「ごろつき」と「バイタ」が、たまたま街で出会い、惹かれ合う、そういった物語・・・・・・。
これって、映画か歌に似たようなストーリーがあったのではないでしょうか。映画だとすると、イタリア映画かフランス映画です。イタリア映画だと、最後は二人の意志とは無関係な悲劇で終わるというような・・・・・・。映画だと登場人物も多いし、さまざまな尾鰭がついてはいるが、ストーリーの骨子は上のような映画です。
・・・・・・と思ったものの、その映画の題名は何かと問われると、ピッタリとした映画が思い出せません。それに近い映画はあるのですが・・・・・・。
「既視感」が映画ではなく歌によるのだとすると、思い浮かぶのはシャンソンです。しかし、シャンソンでも同じストーリーの曲は思い出せません。
そこで、既視感を抱いた理由はストーリーそのものというより、この曲の構成スタイルがシャンソンのあるジャンルを思い起こさせたから、とも考えました。つまり、物語性がある歌詞で、人生の一断面にハイライトが当たっている。曲の作りとしては「街の人々の声や囁き」と「主人公の言葉」が交錯する。つまり「語りのような部分」と「歌の部分」、オペラで言うとレチタティーボとアリアが交替するような作りになっている。こういった曲の作り方はシャンソンにいろいろあったと思います。
「語りと歌の交替」でいうと、大御所、シャルル・アズナブールの『イザベル』などはその典型です。イザベルという女性への思いを綿々と綴った詩ですが、「歌」の部分の歌詞は "イザベル" という女性名が繰り返されるだけであり、その他の歌詞はすべてメロディーをつけない「語り」になっています。ちょっと極端かもしれませんが。
『ふたりは』と似た詩の内容のシャンソンは思い出せないのですが、詩の内容はともかく、曲の作り方がシャンソンの影響を感じる。そういった全体の雰囲気から既視感を覚えたのだと思いました。既視感の本来の意味は、本当は見聞きしたり体験したことがないのに、あたかも過去に経験したことのように感じることなのです。
言葉の力
中島みゆき『ふたりは』の詩の話でした。ここには "あそびめ"、"ばいた"、"ごろつき" など、あまり日常的ではない言葉が使われています。そうしたこともあり、描かれた物語は「ある種のおとぎ話」のように聞こえます。詩の中に主人公の言葉として "おとぎばなし" が出てきますが、全体が「おとぎばなし」のようです。物語の内容もシンプルで、中島作品にしてはめずらしく平凡な感じがします。もっとストレートに言うとステレオタイプに思える。中島みゆき "らしくない" 物語という感じがします。
しかしこの詩には全体を引き締める「言葉」があると思うのですね。それは4回繰り返される「緑為す春の夜」という表現です。この印象的な一言があるために、詩の全体が生きてくる。物語としては "ありがちな" 話かもしれないけれど、短いが印象的な言葉の力で詩全体が独特の光を放っていると強く感じます。
その「緑為す春の夜」とはどういう意味でしょうか。まず「夜」ですが、主人公の二人は社会において、光よりは陰、表よりは裏のポジションにいる男と女です。二人が出会う時間は「夜」というのが当然の設定でしょう。この曲が収められたアルバムのタイトルも『夜を往け』です。男と女はまだ "夜を往って" いる。
しかし季節は「春」です。冬が終わり、肌にあたる空気も刺すような冷たさではありません。夜に戸外をさまよったりすると "凍えきる" かもしれないが、空気感は明らかに冬とは違う。"春先" か "早春" と言うべきかもしれません。生命の活動が再開する季節であり、物語としてはポジティブな将来を予想させます。夜もいずれ終わり朝がくることも暗示しているようです。"夜を往った" 向こうには朝がある。
この「春の夜」ですが、古今和歌集や新古今和歌集に「春の夜」を詠った和歌がいくつもあったと思います。古今和歌集の有名な歌に、
があります。「春の夜の闇は、わけの分からないことをするものだ。梅の花は隠しても、香りは隠せるだろうか(隠せない)」というほどの意味ですが、ここで「春の夜」に付け加えられているモチーフは花(梅)の香りです。夜であっても香りは感じます。
ほかに五感に関係するもので「春の夜」に合わせるとしたら月でしょう。それも、空気が乾燥してくっきりと見える冬の月ではなく、南からの風が吹いて湿度が高くなったときの朧月です。「春の夜」に朧月を登場させた短歌もいろいろあったと思います。
しかし『ふたりは』において「春の夜」に添えられているのは「緑為す」という形容句です。これはどういう意味でしょうか。少なくとも「春の夜」に戸外では「緑」を視認しにくいはずだし、ここに「緑」をもってくるのは意外な感じがします。これには、次の二つの意味が重なっていると思います。
ひとつは、日本に古来からある「緑なす黒髪」という表現で、女性のつややかな黒髪を表します。確か、枕草子にもあったはずです。現代でも、ポップスの歌詞に現れたりする。つまり「緑なす」は「黒」を連想させる言葉であり、と同時に "好ましい黒" というイメージになります。それがこの詩では「夜」に懸かっている。つまり「緑為す夜」であり、それは "好ましい夜" です。
もうひとつの「緑為す」の含意は、草木の葉の緑です。季節は春(春先、早春)なので、新芽や若葉の緑、生命の再生や息吹きを感じさせる緑です。つまり「緑為す春」という連想が働く。まとめると「緑為す」は「春」と「夜」の両方にかかる表現になっていると思います。
「緑為す春の夜」は、きわめて短い表現だけれども『ふたりは』という詩で語られる物語の全体をギュッと濃縮したような言葉になっています。この「緑」と「春」と「夜」の三つの単語を一つのフレーズに持ち込んだのは、ちょっと大袈裟ですが、日本文学史上初めてではないでしょうか。もちろん "あてずっぽう" ですが、そう感じるほと言葉が輝いています。
さらにこの曲は、中島さんの圧倒的な歌唱力と「歌で演技する力」が遺憾なく発揮されています。それとあいまって、数ある中島作品の中でも出色の曲に仕上がっていると思います。
出会い
No.168で取り上げた2曲を含めて
の3曲を比較すると顕著な対比がみられます。「春なのに」と「少年たちのように」は、純真な少年と少女が(卒業で)春に別れる詩です。一方、「ふたりは」のほうは、純真とは真逆の男と女が春に出会い、一緒に旅立とうとする詩です。前の2つの別れの詩とは全くの対極にあります。
『ふたりは』という詩は、1990年代からの中島さんの詩の新しい潮流を象徴するかのようです。この前後から中島さんは、二人でいることの喜び、人が人と出会うことの意義、めぐり逢うことの素晴らしさ、パートナーシップの大切さなどを言葉にした詩を発表しています。
などです。そのことは、No.66「中島みゆきの詩(3)別れと出会い」でも書きました。数々のアーティストによってカバーされている『糸』は、その典型でしょう。
これら一連の詩の中で、強い物語性をもっている『ふたり』の詩は異色であり特別だと言えます。そして物語の "結論"、つまり最後の言葉は「もう二度と傷つかないで」です。中島さんが数多く作ってきた「別れ」のシチュエーションの詩では、傷ついた主人公の女性を表現していることがほとんどでした。強がりを言っているようでも、内心は深く傷ついている。そういった数々の詩に対して『ふたりは』の最後の言葉、
は、傷ついている過去の幾多の主人公への呼びかけのように聞こえます。
この曲は1970年代から数多く作られてきた「別れ」の詩とは逆の内容を提示することにより、クリエーターとしての中島さんが新しい段階に進んだことを示しているようです。その意味では「中島みゆき作品史」の中では一つの記念碑的な作品だと思います。
| 柏原芳恵への提供曲(1983) | ||||
| 三田寛子への提供曲(1986) |
をとりあげました。2曲とも "春の別れ" をテーマとした詩です。そのときに別の中島作品を連想したのですが、今回はそれを書きます。2曲とは全く対照的な "春の出会い" をテーマとする曲、
| アルバム『夜を往け』1990 |
です。
ふたりは
「ふたりは」は、1990年に発売されたアルバム『夜を往け』に収録されている曲です。また、その年の暮れの第2回目の「夜会」で最後に歌われました。その詩を引用すると以下の通りです。
|

| ||
|
中島みゆき「夜を往け」(1990)
①夜を往け ②ふたつの炎 ③3分後に捨ててもいい ④あした ⑤新曾根崎心中 ⑥君の昔を ⑦遠雷 ⑧ふたりは ⑨北の国の習い ⑩with | ||
さっき書いたように、この曲は1990年の第2回目の「夜会」の最後に歌われました。その前の年、1989年の夜会(第1回)の最後は『二隻の舟』です。『二隻の舟』は「夜会」のために書かれた曲で、1990年の「夜会」の最初の曲でもあり、3年後にアルバムに収録されました(『EAST ASIA』1992)。『ふたりは』という曲は、"二人" ないしは "あなたと私" のことを詩にしているという点で『二隻の舟』と似ています。アルバム『夜を往け』の発売(1990.6.13)は「夜会 1990」(1990.11.16~)より先なのですが、「夜会」の最後に歌うことを想定して書かれたのかもしれません。
シャンソン
『ふたりは』という曲を初めて聴いたとき、詩で描かれた物語について、"どこかで聴いた(見た)ような・・・・・・" という既視感がぬぐえませんでした。
男と女の物語です。男は、社会や町、ないしはコミュニティーの "アウトサイダー" です。最も極端なのはヤクザですが、そこまで行かなくても、不良、チンピラ、アウトロー、嫌われ者であり、蔑んだ言い方では「ゴロツキ」です。
対するのは「性的に奔放な女性」です。職業としては「売春婦」ないしは「風俗嬢」ですが、そうでなくても「あばずれ」とか「ふしだら女」と呼ばれる女性。「誰とでもやる女」と見られていて、蔑んだ言い方では「バイタ(売女)」です。
要するに、社会や町やコミュニティーの表ではなく裏、光の部分ではなく陰の部分を象徴するような二人です。しかし二人の心の奥底には非常にピュアな部分があり、人を愛したい、人から愛されたいとの思いを秘めている。人々からは蔑まれてはいるが、内心は愛を求めている。二人とも "夢破れて"、夢とは正反対の状況で生きている。そんな「ごろつき」と「バイタ」が、たまたま街で出会い、惹かれ合う、そういった物語・・・・・・。
これって、映画か歌に似たようなストーリーがあったのではないでしょうか。映画だとすると、イタリア映画かフランス映画です。イタリア映画だと、最後は二人の意志とは無関係な悲劇で終わるというような・・・・・・。映画だと登場人物も多いし、さまざまな尾鰭がついてはいるが、ストーリーの骨子は上のような映画です。
・・・・・・と思ったものの、その映画の題名は何かと問われると、ピッタリとした映画が思い出せません。それに近い映画はあるのですが・・・・・・。
「既視感」が映画ではなく歌によるのだとすると、思い浮かぶのはシャンソンです。しかし、シャンソンでも同じストーリーの曲は思い出せません。
そこで、既視感を抱いた理由はストーリーそのものというより、この曲の構成スタイルがシャンソンのあるジャンルを思い起こさせたから、とも考えました。つまり、物語性がある歌詞で、人生の一断面にハイライトが当たっている。曲の作りとしては「街の人々の声や囁き」と「主人公の言葉」が交錯する。つまり「語りのような部分」と「歌の部分」、オペラで言うとレチタティーボとアリアが交替するような作りになっている。こういった曲の作り方はシャンソンにいろいろあったと思います。
「語りと歌の交替」でいうと、大御所、シャルル・アズナブールの『イザベル』などはその典型です。イザベルという女性への思いを綿々と綴った詩ですが、「歌」の部分の歌詞は "イザベル" という女性名が繰り返されるだけであり、その他の歌詞はすべてメロディーをつけない「語り」になっています。ちょっと極端かもしれませんが。
『ふたりは』と似た詩の内容のシャンソンは思い出せないのですが、詩の内容はともかく、曲の作り方がシャンソンの影響を感じる。そういった全体の雰囲気から既視感を覚えたのだと思いました。既視感の本来の意味は、本当は見聞きしたり体験したことがないのに、あたかも過去に経験したことのように感じることなのです。
| 余談ですが、シャルル・アズナブールは92歳(2016年5月現在)です。その「最後の日本公演」を2016年6月に東京と大阪で行うそうです。92歳で現役というのは凄いことですが、「最後の」と銘打って宣伝するプロモーター側の言い方も相当なものです。さっきアズナブールの名前を出したのは、この日本公演のことが頭にあったからでした。 |
言葉の力
中島みゆき『ふたりは』の詩の話でした。ここには "あそびめ"、"ばいた"、"ごろつき" など、あまり日常的ではない言葉が使われています。そうしたこともあり、描かれた物語は「ある種のおとぎ話」のように聞こえます。詩の中に主人公の言葉として "おとぎばなし" が出てきますが、全体が「おとぎばなし」のようです。物語の内容もシンプルで、中島作品にしてはめずらしく平凡な感じがします。もっとストレートに言うとステレオタイプに思える。中島みゆき "らしくない" 物語という感じがします。
しかしこの詩には全体を引き締める「言葉」があると思うのですね。それは4回繰り返される「緑為す春の夜」という表現です。この印象的な一言があるために、詩の全体が生きてくる。物語としては "ありがちな" 話かもしれないけれど、短いが印象的な言葉の力で詩全体が独特の光を放っていると強く感じます。
その「緑為す春の夜」とはどういう意味でしょうか。まず「夜」ですが、主人公の二人は社会において、光よりは陰、表よりは裏のポジションにいる男と女です。二人が出会う時間は「夜」というのが当然の設定でしょう。この曲が収められたアルバムのタイトルも『夜を往け』です。男と女はまだ "夜を往って" いる。
しかし季節は「春」です。冬が終わり、肌にあたる空気も刺すような冷たさではありません。夜に戸外をさまよったりすると "凍えきる" かもしれないが、空気感は明らかに冬とは違う。"春先" か "早春" と言うべきかもしれません。生命の活動が再開する季節であり、物語としてはポジティブな将来を予想させます。夜もいずれ終わり朝がくることも暗示しているようです。"夜を往った" 向こうには朝がある。
この「春の夜」ですが、古今和歌集や新古今和歌集に「春の夜」を詠った和歌がいくつもあったと思います。古今和歌集の有名な歌に、
| 春の夜の闇はあやなし梅の花 色こそ見えね香やは隠るる(凡河内 躬恒) |
があります。「春の夜の闇は、わけの分からないことをするものだ。梅の花は隠しても、香りは隠せるだろうか(隠せない)」というほどの意味ですが、ここで「春の夜」に付け加えられているモチーフは花(梅)の香りです。夜であっても香りは感じます。
ほかに五感に関係するもので「春の夜」に合わせるとしたら月でしょう。それも、空気が乾燥してくっきりと見える冬の月ではなく、南からの風が吹いて湿度が高くなったときの朧月です。「春の夜」に朧月を登場させた短歌もいろいろあったと思います。
しかし『ふたりは』において「春の夜」に添えられているのは「緑為す」という形容句です。これはどういう意味でしょうか。少なくとも「春の夜」に戸外では「緑」を視認しにくいはずだし、ここに「緑」をもってくるのは意外な感じがします。これには、次の二つの意味が重なっていると思います。
ひとつは、日本に古来からある「緑なす黒髪」という表現で、女性のつややかな黒髪を表します。確か、枕草子にもあったはずです。現代でも、ポップスの歌詞に現れたりする。つまり「緑なす」は「黒」を連想させる言葉であり、と同時に "好ましい黒" というイメージになります。それがこの詩では「夜」に懸かっている。つまり「緑為す夜」であり、それは "好ましい夜" です。
もうひとつの「緑為す」の含意は、草木の葉の緑です。季節は春(春先、早春)なので、新芽や若葉の緑、生命の再生や息吹きを感じさせる緑です。つまり「緑為す春」という連想が働く。まとめると「緑為す」は「春」と「夜」の両方にかかる表現になっていると思います。
「緑為す春の夜」は、きわめて短い表現だけれども『ふたりは』という詩で語られる物語の全体をギュッと濃縮したような言葉になっています。この「緑」と「春」と「夜」の三つの単語を一つのフレーズに持ち込んだのは、ちょっと大袈裟ですが、日本文学史上初めてではないでしょうか。もちろん "あてずっぽう" ですが、そう感じるほと言葉が輝いています。
さらにこの曲は、中島さんの圧倒的な歌唱力と「歌で演技する力」が遺憾なく発揮されています。それとあいまって、数ある中島作品の中でも出色の曲に仕上がっていると思います。
出会い
No.168で取り上げた2曲を含めて
| 1983 | ||||
| 1986 | ||||
| 1990 |
の3曲を比較すると顕著な対比がみられます。「春なのに」と「少年たちのように」は、純真な少年と少女が(卒業で)春に別れる詩です。一方、「ふたりは」のほうは、純真とは真逆の男と女が春に出会い、一緒に旅立とうとする詩です。前の2つの別れの詩とは全くの対極にあります。
『ふたりは』という詩は、1990年代からの中島さんの詩の新しい潮流を象徴するかのようです。この前後から中島さんは、二人でいることの喜び、人が人と出会うことの意義、めぐり逢うことの素晴らしさ、パートナーシップの大切さなどを言葉にした詩を発表しています。
| 「夜を往け」1990 | ||||
| 「夜を往け」1990(アルバム最終曲) | ||||
| 「夜会」1989。「EAST ASIA」1992 | ||||
| 「EAST ASIA」1992(アルバム最終曲) |
などです。そのことは、No.66「中島みゆきの詩(3)別れと出会い」でも書きました。数々のアーティストによってカバーされている『糸』は、その典型でしょう。
|
これら一連の詩の中で、強い物語性をもっている『ふたり』の詩は異色であり特別だと言えます。そして物語の "結論"、つまり最後の言葉は「もう二度と傷つかないで」です。中島さんが数多く作ってきた「別れ」のシチュエーションの詩では、傷ついた主人公の女性を表現していることがほとんどでした。強がりを言っているようでも、内心は深く傷ついている。そういった数々の詩に対して『ふたりは』の最後の言葉、
| 「 | もう二度と傷つかないで」 |
は、傷ついている過去の幾多の主人公への呼びかけのように聞こえます。
この曲は1970年代から数多く作られてきた「別れ」の詩とは逆の内容を提示することにより、クリエーターとしての中島さんが新しい段階に進んだことを示しているようです。その意味では「中島みゆき作品史」の中では一つの記念碑的な作品だと思います。
(続く)



