No.180 - アルファ碁の着手決定ロジック(1) [技術]
アルファ碁(AlphaGo)
No.174「ディープマインド」で、英国・ディープマインド社(DeepMind)のコンピュータ囲碁プログラム、アルファ碁が、世界最強レベルの囲碁棋士である韓国の李世乭(イ・セドル)九段に勝利した話を書きました(2016年3月。アルファ碁の4勝1敗)。

| ||
|
AlphaGo vs イ・セドル9段(右)第1局
(YouTube)
| ||
このアルファ碁に盛り込まれた技術について、No.174 では「Nature ダイジェスト 2016年3月号」に従って紹介しました。要約すると、ディープマインド社のやったことは、
| ◆ | 次に打つ手を選択して碁盤を読む能力をもったニューラルネットワークを、深層学習と強化学習によって作った。 | ||
| ◆ | このニューラルネットワークを、手筋のシミュレーションによって最良の手を選択する市販の囲碁プログラムの探索アプローチと組み合わせた。 |
となります。非常に簡単な説明ですが、そもそも「Nature ダイジェスト」の解説が簡素に書いてあるのです(それが "ダイジェスト" の意義です)。
もうちょっと詳しく言うとどういうことなのか、どこに技術のポイントがあるのか、大変気になったので「Nature 本誌」の記事を読んでみました。ディープマインド社が投稿した「ディープ・ニューラルネットワークと木検索で囲碁を習得した - Mastering the game of Go with deep neural network and tree search」(Nature 2016.1.28)という研究報告です。以下、この報告に書かれているアルファ碁の仕組みを分かりやすく書いてみたいと思います。以下の要約によって「Nature ダイジェスト」の説明を詳しく言うとどうなるのかが見えてくると思います。たとえば「次に打つ手を選択して碁盤を読む能力をもったニューラルネットワーク」というのは、実は「次に打つ手を選択するニューラルネットワーク」と「碁盤を読む能力をもったニューラルネットワーク」の二つあることも分かります。

前提
前提事項が2つあります。まず1点目ですが、「Nature」の研究報告(2016.1.28)が発表された時点で、イ・セドル 九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。相手は樊麾二段(ファン・フイ。中国出身でフランス国籍。フランス在住。中国棋院二段)で、その成果を受けての報告です。おそらくディープマインド社はイ・セドル 九段との戦いまでの間に、アルファ碁のロジックの強化やチューニングを繰り返したと思います。囲碁のトップレベルの国は中国・韓国・日本であり、韓国のイ・セドル 九段は樊麾二段とは "格" が違います。イ・セドル 九段との戦いという、ディープマインド社にとっての(そして親会社のグーグルにとっての)晴れ舞台に向けて、アルファ碁の強化を繰り返したことが十分に想定できるのです。以下の研究報告の解説は2015年10月時点の技術内容と考えるべきであり、それ以降の強化は含まれないことに注意が必要です。
2番目は専門用語です。ディープマインド社が「Nature」に投稿したのは「囲碁を素材にしたニューラルネットワークや強化学習の研究報告」なので、専門用語や数式がいろいろ出てきます。しかしそういった用語や数式は、以下の要約では必要最小限にしました。さらに、研究報告の内容を順番に説明するのではなく、そこに書いてあることを、補足を交えて再構成しました。ニューラルネットワークや強化学習については、各種Webサイトに紹介やチュートリアルがあります。また多数の書籍も出版されているので、そちらを参照ください。
4つの技術
ディープマインド社の研究報告を読むと、アルファ碁は次の4つの技術の組み合わせで成り立っていることが分かります。
| ① | policy network | ||
| ② | value network | ||
| ③ | モンテカルロ木検索(Monte Carlo Tree Search : MCTS) | ||
| ④ | rollout policy |
このうち、①policy network、②value network はディープマインド社の独自技術です。一方、③モンテカルロ木検索と ④rollout policy は、現在、世に出ている多くのコンピュータ囲碁プログラムが採用しています。もちろん③④についてもディープマインド社独自の工夫や味付けがあるのですが、基本的なアイデアは既知のものです。「Nature ダイジェスト」に「ニューラルネットワークと既存の検索アプローチを組み合わせた」という意味のことが書かれていましたが、これは ①② と ③④ を組み合わせたことを言っています。「Nature ダイジェスト」の要約に①~④を対応させると次の通りです。
| ◆ | 次に打つ手を選択して(= policy network)碁盤を読む能力をもった(= value network)ニューラルネットワークを、深層学習と強化学習によって作った。 | ||
| ◆ | このニューラルネットワークを、手筋のシミュレーションによって最良の手を選択する(= rollout policy)市販の囲碁プログラムの探索アプローチ(= MCTS)と組み合わせた。 |
以降、この4つの技術について、順に説明します。なお、「④rollout policy」は「③モンテカルロ木検索」の一部とするのが普通ですが、説明の都合上、分けてあります。
policy network
まず言葉の意味ですが、ポリシー(policy)とは、着手を決めるロジック、ないしはアルゴリズムのことです。現在の盤面の情報をもとに、次にどこに打つべきかをコンピュータ・プログラムで決める、その決め方をいっています。またネットワーク(network)とは、AI(人工知能)の研究で多用されるニューラルネットワーク(neural network)のことです。つまり、
| policy networkとは、現在の盤面の情報をもとに、次にどこに打つべきかを決めるためのニューラルネットワーク |
です。ディープマインド社がコンピュータ上に構築した policy network は、ニューラルネットワークの中でも「畳み込みニューラルネットワーク(Convolutional Neural Network. CNN)」と呼ばれるタイプのもので、画像認識の研究で発達しました。画像認識で、たとえば画像の中にある猫の顔を認識しようとすると、それは画像いっぱいにあるもしれないし、画像のごく一部かもしれない。また猫の顔が移動しても(どこにあっても)、大きさが違っても、少々変形していても認識できないといけない。画像の大域的な特徴と局所的な特徴を同時にとらえ、かつ移動や変形、拡大縮小があったとしても普遍的な特徴をとらえる。「畳み込みニューラルネットワーク」はこのようなことが可能なニューラルネットワークです。ディープマインド社が使ったのは隠れ層が12層あるもので(いわゆるディープ・ニューラルネットワーク。Deep Neural Network。DNN)、図示すると以下のようです。
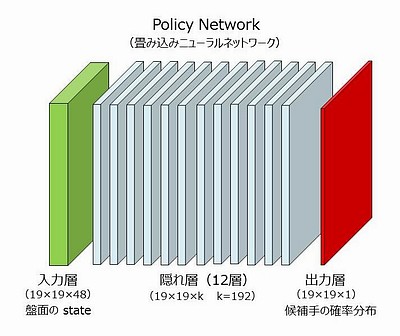
| ||
|
kは "フィルタ" の数で、プロとの実戦では 192 が使われた。入力層から第1隠れ層への "カーネル" は5×5である。従って、周辺に 0 を2つパディングした 23×23×48 が入力層となる(19+2+2=23)。5×5×48個の重み値(フィルタ)と、入力層の5×5×48の部分領域の値を掛け合わせて合計した値を活性化関数(ReLU関数)への入力として、第1隠れ層の1つの値が決まる。この操作を、入力層の部分領域を上下左右に1ずつずらしながら19×19回繰り返すと、第1隠れ層の1つのプレーンができる。さらにこの計算全体を、フィルタをかえて192回繰り返すと第1隠れ層ができあがる。
第1隠れ層から第12隠れ層に至るカーネルは3×3である。出力層へのカーネルは1×1であるが 19×19 個の異なったバイアスを使用し、また出力層の合計値が 1.0 になるように調整される。ニューラルネットワークの訓練とは、訓練データが示す出力(19×19のどこか1箇所が1で残りは全部ゼロ)と最も近くなるように、フィルタ(重み)およびバイアスの値を調整することである。 このニューラルネットの重みがいくつあるか計算してみると、第1隠れ層への重みは5×5×48×192、第2隠れ層から第12隠れ層については3×3×192×192×11(=11層)、出力層への重みは1×1×192である。さらに出力層には19×19のバイアスが加味される。これらをすべて合計すると約388万(3,880,489)である。388万個のパラメータ(重みとバイアス)を最適に決めるのがニューラルネットワークの訓練である。 なお、画像認識における「畳み込みニューラルネットワーク」で使われるプーリング層(画像を "サマライズ" する層)はない。19×19程度の "画像" をサマライズする意味はない。 | ||
このニューラルネットワークの出力層は 19×19×1 で、碁盤の 19×19個の交点(目)に対して 0.0 ~ 1.0の数値が出力されます。この数値は囲碁の熟練者がそこに打つ確率を表します。すべての交点の確率を合計すると1.0になります(いわゆる確率分布)。
入力層は 19×19×48 のサイズで、碁盤の19×19の交点が48層(48プレーン)があります。一つのプレーンの一つの交点は 1 か 0 の値をとります。コンピュータに詳しい人なら「19×19の交点のそれぞれに48ビットを割り当てた」と言った方が分かりやすいでしょう。No.174「ディープマインド」で紹介した「Nature ダイジェスト 2016年3月号」の記事では、「入力層は碁盤の黒石・白石の配置パターン」と受け取れる表現がありましたが、実際の入力層はそれよりもかなり複雑です。48のプレーンは以下のように構成されています。全ての情報は打ち手(次に手を打つ人)を基準に計算され、一手進むごとに再計算されます。
policy network の入力層の構成
の数 |
説明 |
| 1 | 打ち手の石(打ち手の石があれば 1) |
| 1 | 相手の石(相手の石があれば 1) |
| 1 | 空点(空点であれば 1) |
| 1 | すべて 1 |
| 8 | その交点に石が打たれてから現在までに進んだ手数。 |
| 8 | 石の呼吸点(上下左右の空点)の数。その交点の石と連結している石全体(いわゆる “連”)の呼吸点を表す。 |
| 8 | その交点に打ち手の石を打ったとしたとき、相手の石を取れる数。 |
| 8 | その交点に相手が石を打ったとしたとき、打ち手の石が取られる数。 |
| 8 | その交点に打ち手の石を打ったとき、その石と連結している石全体(連)の呼吸点の数。 |
| 1 | その交点に打ち手の石を打って相手の石をシチョウで取れるとき 1 |
| 1 | その交点に打ち手の石を打ってシチョウから逃げられるとき 1 |
| 1 | 合法手。その交点に打ち手の石を打つのが囲碁のルールで許されるとき 1。ただし打ち手の目をつぶす手は合法手とはしない。 |
| 1 | すべて 0 |
8つのプレーンで一つの数を表すものが5種類ありますが、いずれも「0, 1, 2, 3, 4, 5, 6, 7, 8以上」を表します。1 の場合は1番目のプレーンだけが 1、2 の場合は2番目のプレーンだけが 1、以下、8以上の時は8番目のプレーンだけが 1です。情報科学でいう one-hot encoding("8ビット" のうち 1 は一つだけ)になっています。
この構成で分かるように、入力層は単なる黒石・白石の配置パターンではありません。囲碁のルールが加味されています。さらに「シチョウに取る・シチョウから逃げる」や「ダメヅマリ(連結する石の呼吸点の数)」というような、ルールから派生する囲碁の常識(が判別できる情報)も含まれています。
以上の 19×19×48 の入力層の情報をディープマインド社の研究報告では盤面の "state" と読んでいます。これに従って、以下「盤面(state)」ないしは単に「state」と書くことにします。
当然ですが、盤面(state)の情報は、打った手の履歴が分かれば計算できます。アルファ碁は着手を決定する際に policy network を使うのですが、まず state を計算し(再計算し)、ニューラルネットワークの計算を行って、囲碁の熟練者がどこに打つかの確率を求める。これを着手ごとに繰り返すことになります。
SL policy network
ディープマインド社がまず作成した policy network は、教師あり機械学習(supervised learning)による policy network で、これを SL policy network と呼びます。以下、単に SL と書くこともあります。SL policy networkの「訓練データ」は、KGS Go Server からダウンロードされた、囲碁の対局データです。
KGS Go Serverは、もともと神奈川県茅ヶ崎市の囲碁用品店、棋聖堂が運営していた無料の囲碁対局サイト(Kiseido Go Server : KGS)で、現在はアメリカの篤志家と各国のボランティアが運営しています。このサイトには世界の囲碁愛好家が集まっていて、無料の囲碁対局サイトとしては最も広まっているものの一つです。
参加者はアマチュア30級(30k)から1級(1k)、アマ初段(1d)から九段(9d)までにレーティングされます。このレーティングは、KGSの独自のアルゴリズムにより対局が行われるたびに自動更新されます。KGS にはプロ棋士も参加しており、自ら参加を公表しているプロ棋士もいます。プロの段位は d ではなく p と表示します(レーティングはなく申請方式)。アマチュアの中には、コンピュータ囲碁のプログラムも参加しているようです。
ディープマインド社が SL policy network の訓練データとしたのは、KGS のアマチュア高段者(6段~9段。6d~9d)の約16万局の対局データで、それには2940万の盤面データがありました。このうち100万の盤面データは、できあがった SL policy network の評価に使用されました。従って実際の訓練データは「2840万の盤面データと、その場面で囲碁熟練者が実際に打った手」です。もっとも、囲碁には対称性があるので盤面を90度づつ回転した4つの盤面データ、およびそれらの裏返しを含めた合計8つの盤面データが教師データとして使われました。従ってSL policy networkにとっての訓練データの総数は2億2720万ということになります。訓練データの数が2840万とか2億2720万というと非常に多いようにみえますが、SL policy network のパラメータの数(重みとバイアス。上の policy network の図の説明参照)は388万もあります。これと比較すると約7倍とか60倍という数です。深層学習の訓練データの必要数はパラメータの数の数倍以上とされているようなので、この数はリーズナブルな数なのでしょう。
これら訓練データの state をあらかじめ計算しておき、policy networkを "教育" しました。つまり「出力層の確率分布」と「実際に打たれた手の確率分布(どこか1箇所が 1 で、その他は 0)」との誤差の総体が最も小さくなるように、ニューラルネットワークの重みを調整していったわけです。この調整には "確率的勾配降下法"(stochastic gradient descent。SGD。報告では ascent も何回か使われているが、同じ意味)という手法が使われました。こうして出来あがったのが SL policy network です。
この SL policy network が、どの程度の精度で熟練者の実際の手を予測できるかを、訓練データとしては使わなかった100万の盤面データで調べた値があります。それによると予測精度は57.0%とのことです。この定義ですが、実際に打たれた手に対応する SL policy network の出力層での確率(の100万個の平均値)だと読み取れます。とすると、出力層の最高確率の手を打てばアマチュア高段者の手がかなりの精度で近似できるということになります。57.0%は100万のテストデータの平均値なので、中にはハズレもあるでしょう。また、アマチュア高段者が打った手が最善手だとは限りません。しかしこの57.0%という数字は SL policy network が有効だということを示しています。想像するに、確率が上位の3つぐらいの手の中にアマチュア高段者が実際に打った手が極めて高い確率で含まれるのではないでしょうか。
興味あるデータがあります。もし SL policy network の入力層が48プレーンではなく11プレーン(石の配置が3プレーン、手数が8プレーン)ならどうなるかということです。それを実際にやってみると、予測精度は 55.7% になったとのことです。わずか 1.3% の違いなのですが、研究報告で強調してあるのは、この程度の予測精度のわずかな違いが囲碁の強さに大きく影響するということです。
予測精度をあげるためには、畳み込みニューラルネットワークの隠れ層を増やすという案も当然考えられます。しかしそうすると、policy network の計算時間が増えます。つまり、限られた時間内に「読める」手が少なくなる。ディープマインド社は超高速コンピュータシステムを使っているので、policy network の一回の計算は3ミリ秒で終わります。しかしあとから出てくるように、コンピュータ囲碁に適用するにはこの速度でも遅すぎるのです(その回避策もあとで説明します)。
入力層のプレーンが48や、畳み込みニューラルネットワークの隠れ層が12というのは、ディープマインド社が精度と速度のバランスを試行錯誤して決めたものだと想像できます。
| 補足ですが、No.174「ディープマインド」で紹介した「Nature ダイジェスト 2016年3月号」に「プロ棋士どうしの対局の3000万通りの局面を調べ」とあるのは間違いです(原文か訳か、どちらかの間違い)。SL policy network の訓練データは KGS Go Server のアマ高段者の対局データです。 |
RL policy network
RL policy networkとは、強化学習(reinforcement learning)の手法を使って、SL policy network をさらに "強く" したものです。基本的な方針は policy network 同士の「自己対局」です。policy network に従って碁を打つということは、policy network が示す確率分布に従って手を打つということになります。
まず初期値として RL = SL とします。そして「強化試合相手の集合(policy pool)」を設定し、初期状態ではSLをひとつだけ policy pool に入れておきます。
一回の「強化」は次のように進みます。policy poolの中から「強化試合相手」をランダムに選び、RLをその相手と128回対戦させます。この対戦過程の全盤面を記憶しておき、RLの対戦成績が最も高くなるように、RLのニューラルネットワークのパラメータ(重み)を調節します。つまり、勝った対戦では勝ちに至った手をできるだけ選ぶようにパラメータを調節し、負けた対戦では負けに至った手を選びにくいように調節するわけです。このあたり、ディープマインド社のCNNを使った強化学習の技術蓄積が生きているところです。
以上の強化を500回行うごとに、その時点でのRLを policy pool に入れます。この強化を1万回(1回あたりの対戦は128回)繰り返して、最終的なRLとします。従って「自己対戦」は128万回行ったことになります。もともと SL policy network は KGS Go Server の約16万局のデータをもとに訓練されたものでした。それからすると RL の作成で行った自己対局の128万回は断然多いことになります。
こうして作成された RL policy network を市販のコンピュータ囲碁プログラムと対戦させた結果が報告に載っています。Pachi というプログラムは、オープンソースの(ソースコードが公開されている)コンピュータ囲碁プログラムでは最強と言われていて、KGSのレーティングではアマチュア2段(2d)です。RL はPachi と対戦して 85%の勝率でした。一方、SL は 11%の勝率でした。RL policy network は SL policy network に比べて格段に強くなったと言えるでしょう。このように、すべてコンピュータ内部で自動的に行える「自己対局」を繰り返すことで強くできるアルゴリズムを作れることが、ニューラルネットワークをコンピュータ囲碁に持ち込む大きなメリットでしょう。
RL policy network はなぜ強くなったのかを推定してみます。SL policy network の最大の弱点は、機械学習の教師データとした「2840万の盤面における次の一手」が最善手とは限らないことです。教師データは、あくまでアマチュア高段者の実際の対局データ(約16万局)です。高段者と言えども、次の一手には悪手や疑問手が多数含まれているはずだし、中には "ポカ" もあるでしょう。それらを全部 "正しい" 教師データとして機械学習したのが SL です。
RL は SL 同士の自己対局で作られました。「SL に勝つような SLの修正版が RL」であり、そういった "カイゼン" を次々と繰り返していって完成したのが最終的な RL です。しかも "カイゼン" のための自己対局の数は、元の教師データの対局数より圧倒的に多い。この結果、元々の SL に含まれていた「疑問手・悪手・ポカ」を打つ傾向が薄まったと考えられます。RL が最善手を打てるとは言わないまでも「最善手を打たない傾向は、かなり弱まった」と考えられるのです。想像するに「アマチュア高段者が実際に打った手を予測できる」という点に絞れば、RL は SL より予測精度が悪いのかも知れません。RL の予測精度は研究報告には書いてないのですが、つまり「そういった議論は意味がない」ということでしょう。しかし RL が最善手を示す確率は SL よりも高い。おそらくそういうことだと考えられます。
強化学習というと何か新しい能力を獲得したように感じてしまいますが、この学習はあくまで自己対局によるものです。「SLには無かった良い面」を新たに獲得したとは考えにくい。むしろ「SLの悪い面」を少なくした、これが強化学習の意義だと思います。市販のプログラム、Pachi との対戦で 85%もの勝率をあげたのは、このような理由だと推定できます。
Pachi との対戦での重要な注意点は、市販のコンピュータ囲碁プログラムは、打つ手の先を次々と読んで有力な次の手を判断していることです。一方の policy network は「手を先読みする」ことは一切せず、現在の盤面(state)だけから、次に打つべき有力手を計算します。つまり人間同士の囲碁の勝負でいうと、盤面を見て直感で打つことに相当します。直感で手を打つ RL policy network が、手を先読みする市販のコンピュータ囲碁プログラムと対戦して85%の勝率をあげたということは、RL policy network を手を先読みする機能と組み合わせれば非常に強いコンピュータ囲碁プログラムができるだろう、と推定できるのです。
ディープマインド社がやったことはまさにそういうことであり、市販のコンピュータ囲碁プログラムで「手を先読みする」ときに広く使われているモンテカルロ木検索(Monte Carlo Tree Serch. MCTS)と policy network を組み合わせることでした。
次にその「モンテカルロ木検索」ですが、その前に、モンテカルロ木検索で使われる「ロールアウト」です。ロールアウトもディープマインド社の発明ではなく、現在のコンピュータ囲碁プログラムで一般的に使われている手法です。ディープマインド社の研究報告にロールアウトの具体的な説明はなく、既知のものとしてありますが、モンテカルロ木検索の理解のためには必須の事項なので、以下に説明します。
ロールアウト(rollout)という手法
ロールアウトとは、モンテカルロ木検索で使われる重要な手法です。プレイアウト(playout)と呼ぶことが多いのですが、ディープマインド社の研究報告に従ってロールアウトとします。ロールアウトとは次のようなものです。
| ◆ | ある盤面において次に打つ候補手が複数あるとする(たとえば合法手のすべて)。 | ||
| ◆ | どの候補手が一番有力かを見極めるために、候補手の次から始まって黒白交互に合法手をランダムに打って終局まで進め、その勝敗をみる(=ロールアウト)。 | ||
| ◆ | これを何回か繰り返して勝率を計算する。そして勝率のよい候補手ほど有力とする。別の言い方をすると、候補手を打ったときの盤面の優劣を、そこからのロールアウトの勝率で判断する。 |
この「黒白交互に終局まで合法手をランダムに打って勝敗をみる」のがロールアウトです。ランダムということは、候補手の有力な度合いを確率的に判断するということです(自分の目をつぶす手は合法手から除外します)。かつ、序盤であれ中盤であれ、また終盤であれ、とにかく最後までヨセてみる。それを繰り返してその勝率で候補手の有力度合をみるということです。これは人間の思考とはかなり違います。人間なら「最後までヨセたらどうなるか」という思考で打つのは終盤だけです。序盤・中盤でそんなことは考えない(考えられない)。ロールアウトはコンピュータ囲碁の着手に人間とは違った要素を持ち込むと考えられます。
ロールアウトという "乱暴な" 手法がなぜ成立するのかと言うと、囲碁というゲームが「どこに打ってもいいから合法手を順に打っていくと終局に至るゲーム」だからです。囲碁は着手をするたびに打てる所が少なくなっていきます。だから成り立つ。ちなみに将棋だとこうはいきません。将棋の合法手を互いにランダムに指していって王様が詰むという保証はどこにもありません(逃げられる王手を見逃すのは将棋のルール違反)。
ロールアウトを使うと、次のような着手決定アルゴリズムが考えられます。まず許された時間に何回ロールアウトが可能かを見積もります。囲碁は持ち時間(考える時間)が決まっています。たとえばアルファ碁とイ・セドル 九段の対戦では、持ち時間はそれぞれ2時間でした。囲碁の平均手数を200手とすると、黒白それぞれ100手ですから、1手あたり許される思考時間は72秒です。もちろんそれは平均であって、思考時間の配分もコンピュータ囲碁プログラムを設計する時のポイントです。とにかく許される思考時間の間に、たとえば10万回のロールアウトが可能だとしましょう。そして着手可能な合法手(囲碁のルール上許される手)は100手だとします。そうすると、100手のそれぞれで1000回のロールアウトを行い、最も勝率の良い手を着手する・・・・・・。
もちろん、こんな単純なアルゴリズムでは強いコンピュータ囲碁プログラムにはなりません。なぜなら「無駄なロールアウト」をいっぱいやっているからです。ルール上許される合法手といっても、アマチュア初心者でも絶対打たないような手がいっぱいあります。そんな手にたくさんのロールアウトを繰り返すのは時間の無駄です。ロールアウトはあくまで「確率的判断」で有力な手を見極めようとするものです。有力そうな手にはできるだけ多くのロールアウトを割り当て、ダメそうな手は早々に切り上げる。そうしないと確率的に最善手に近づくことができません。つまり、まず候補手をそれぞれ何回かロールアウトして様子を見て、その中から良さそうな手を選択し、さらにそこをロールアウトする・・・・・・。そのようなアルゴリズムが必要です。しかしロールアウトによる勝敗判断はあくまで確率的なので、何回かロールアウトしてみてダメそうな手であっても、もっとロールアウトすると勝率が良い手に "化ける" かもしれないのです。では、どうしたらよいのか。
実は、どの手をロールアウトすべきか、それを決めるための「数学的に最良な方法」が知られています。それが、候補手の Upper Confidence Bound(UCB。信頼上限)という値を計算し、常にUCB値が最大となる手をロールアウトするというアルゴリズムです。UCBは1回のロールアウトのたびに変化していく値で、次の式で計算されます。
| 候補手i のUCB | |||
| 候補手i をロールアウトした数 | |||
| 候補手i のロールアウトによる勝ち数 | |||
| ロールアウトの総数(logは自然対数) | |||
| 定数(理論的には2の平方根だが囲碁プログラム依存) |
その時点で「UCB最大の手」をロールアウトします。もしUCBが第1項(Wi/Ni)だけだと「その時点で最も勝率が高い手を常にロールアウトする」ことになってしまいます。しかし第2項があるためにそうはなりません。第2項にはNiの逆数があるので「その時点でロールアウトの配分が少ない手」ほどロールアウト候補として有利になります。しかし第2項を見ると分子には logN があります。この意味するところは、ロールアウトの配分率が少ない手が有利だとはいうものの、ロールアウトの総数(N)が大きくなると第2項の効果は相対的に薄れていくということです(logN ではなく N だと薄れない)。k は第2項をどの程度重要視するかという定数です。k が小さいと、より勝率の高い手をロールアウトするようになり、k が大きいと勝率が小さくても "チャレンジ" するようになる。このあたりの決め方がコンピュータ囲碁プログラムのノウハウとなっています。第1項を開拓(exploitation)、第2項を探検(exploration)と呼んだりします。
UCB についての補足です。UCB(Upper Confidence Bound。信頼上限)は、教師なし機械学習の理論の一つである「多腕バンディット問題」で出てくる値です。バンディット(Bandit)は山賊の意味ですが、ここではスロットマシンのことです。山賊は旅人や商人からお金を巻き上げるので、これをスロットマシンになぞらえたものです。
スロットマシンにはアーム(腕)があり、コインを入れてアームを操作すると "当たり" か "ハズレ" になる。「多腕」とは、そのアームが複数あるという意味です。説明をシンプルにするために、以降同じことですが、複数のスロットマシンがあることとします。
ポイントは、複数のスロットマシンで "当たり" の出る確率がそれぞれ異なっていて、事前にはその確率が分からないことです。プレーヤーの持っているコインは限られていますが、スロットマシンの台数に比べて十分な量とします。では、この複数のスロットマシンを相手にどういう戦略でプレーをすれば最大の利得が得られる(=当たりの回数を最大化できる)でしょうか。これが問題です。
とりあえず、まず全部のマシンを試してみるのが妥当でしょう。そうすると、たとえば2台のマシンが "当たり" だったとします。では残りのコインでその2台を集中的に試すべきでしょうか。
もちろんこんな戦略ではダメです。最初に "当たり" が出なかったマシンにも高い確率のものがあるかもしれないからです。また2台を試してみてずっと "当たり" が出なかったとき、いつ諦めるべきかという問題もある。では、どうするか。
要は、結果として "当たり" の出る確率が高いマシンにより多くのコインを投資するようにプレーを誘導できればいいわけです。それ実現する "数学的に正しい戦略" が「UCB を判定し、常に最大UCBのマシンを試す」というものなのです。
これがスロットマシンの問題だとすると実用性はありませんが、この理論の応用は現代のビジネスで使われています。その例ですが、今、あるWebページがあり、そのページには50のコンテンツがあるとします。1画面には10のコンテンツが表示できるので、別画面に移るときにはクリックして移ることとします(全部で5つの画面)。最初に表示される第1画面は一般的にコンテンツの良し悪しにかかわらずクリックされる確率が高く、第2、第3となるにつれて急速に確率が落ち、第5画面が最低になる。
この状況で、Webページのページビューを最大化するにはどうすべきでしょうか。そのためには「本質的に最も人気のあるコンテンツを上位画面に集める」ことができればよい。しかしどれが人気が出るコンテンツかは、事前にはわからない。こういう場合サイトの設計者としてはログをとり、そのログを見ながらコンテンツの表示順位を決めますが、よく閲覧されたコンテンツを決めるファクターは「人気がある」と「過去に上位に表示された」の2つがあるので、この2つのバランスをどうとって判断するか、そのアルゴリズムが問題です。
これは、条件はスロットマシンよりは複雑ですが、本質的に「多腕バンディット問題」と同じです。教師なし機械学習はAIの一部と言ってもいいわけで、このような「AI技術を使ってページビューを最大化」しているサイトは多々あるはずです。
コンピュータ囲碁の話に戻ります。この数学的裏付けにもとづいたUCBを使うアルゴリズムでも、まだ問題点があります。一つはランダムに合法手を打ってロールアウトするところです。これではいくらなんでも単純すぎる。囲碁には「常識的な手」があります。相手の石が取れるなら取るとか、ノゾキにはツグとか、また、アマチュアで段位を持っている人なら誰でも知っている手筋も多い。そういう常識的な手が打てるなら打つ。そうした方がランダムなロールアウトより盤面の優劣の判断がより正確になると考えられるのです。
実際、現代のコンピュータ囲碁プログラムでは、ランダムではなく一定のロジックに基づいてロールアウトをしています。このロジックをロールアウト・ポリシー(rollout policy)と呼びます。後で書きますが、アルファ碁もロールアウト・ポリシーによるロールアウトを使っています。ロールアウト・ポリシーの必須条件は、高速に計算できることです。ロールアウトによる勝率の推定は、あくまで確率的なものです。ロールアウトの回数が多いほど推定が正確になるので、高速性が大変重要です。
さらに上のアルゴリズムの問題点は、候補手をリストアップする段階で「合法手すべて」としていることです。少なくともロールアウト総数が少ない初期の段階では、それらを均等に扱っている。合法手の中には「囲碁の常識上ダメな手」があるはずです。「囲碁の常識上ダメな手」がロールアウトなしで高速に判別できれば、候補手の中でもロールアウトの優先度を落とすべきでしょう。このロジックも、現代のコンピュータ囲碁プログラムで採用されています。
以上の「常にUCB値を再計算しながら、それが最大となる候補手をロールアウトし、その勝敗の数で手の有力度合いを判定する」アルゴリズムに「手を先読みする」機能を加えたのが、次の「モンテカルロ木検索」です。
(次回に続く)



