No.175 - 半沢直樹は機械化できる [技術]
No.173「インフルエンザの流行はGoogleが予測する」と No.174「ディープマインド」は、いずれもAI(Artificial Intelligence。人工知能)の研究、ないしはAI技術によるビッグデータ解析の話でした。その継続で、AIについての話題です。
AI(人工知能)が広まってくると「今まで人間がやっていた仕事、人間しかできないと思われていた仕事で、AIに置き換えられるものが出てくるだろう」と予測されています。これについて、国立情報学研究所の新井紀子教授が新聞にユニークなコラムを書いていたので、それをまず紹介したいと思います。新井教授は、例の「ロボットは東大に入れるか」プロジェクトのディレクターです。
金融におけるITの活用
新井教授は、金融サービスにおける "フィンテック" が日本を含む世界で熱を帯びていることから話を始めます。
2014年末、三井住友銀行とみずほ銀行は、コールセンター業務にIBMの人工知能コンピュータ「ワトソン」を導入すると発表しました。新井教授はそういった銀行業界の動きを言っています。しかし新井教授によると、窓口業務よりも、もっとAI向きの銀行業務があると言います。
こういうコラムを読むと、研究者と言えども一般向けに文章を書く(ないしは講演をする)ときには、言葉の使い方が極めて重要だということがよく分かります。「銀行の融資業務は機械化できる」というよりも、「半沢直樹は機械化できる」と言った方が圧倒的にインパクトが強いわけです。研究者も、言いたい事の本質を伝えられる。
新井教授が主導している「ロボットは東大に入れるか」プロジェクトも同じです。「ロボットは大学入試に受かるか」ではなく、あえて「東大」としてあります。プロジェクトの存在感を内外に示すためには、ここは是非とも「東大」でないとまずいのでしょう。しかも最後は「か」という疑問形です。このプロジェクトによって「ロボットが東大に入れるようになるのか、ならないのか、分からない」ようにしてあるわけです。想像ですが、ロボットが東大入試問題を解いて合格するのは無理だと、新井教授は思っているのではないでしょうか。特定の科目で合格点をとるならまだしも・・・・・・。しかし、無理だと言ってしまうと身もフタもない。国立の研究所としては、このプロジェクトを進めることで日本のAI研究を底上げするのが目的でしょうから、ここは疑問形が最適なのですね。
コラムに戻って、では、新井教授は銀行の窓口業務をどう考えているのでしょうか。
確かに窓口での対応は、銀行が顧客に直に接する最前線の一つです。融資担当者(ローンオフィサー)も最前線ですが、接する顧客の数が全く違います。窓口では、顧客のそのときの状況にマッチした「一期一会」の対応が、本来、大変に需要なのです。
アマゾンによる与信審査の完全自動化
新井教授がコラムの最後で書いている「与信審査の完全自動化」ですが、アマゾンはすでに日本でもやっています。
アマゾンにとってみると、適切な事業者(=アマゾン出店者)に、適切な金額を必要な時期に融資できれば、アマゾン経由の通販の量が増え、それによって手数料収入が増える。さらに融資の金利が収入になる。一石二鳥とはこのことでしょう。
事業者のビジネス動向をつぶさにとらえられるという、インターネット通販の特性を生かしたアマゾンのビジネスです。その意味では「融資を断った地方銀行」とは立場が違うのですが、コトの本質は「与信審査は自動化できる」ということです。銀行にその波が押し寄せるのは時間の問題でしょう。
雇用の未来:The Future of Employment
新井教授のコラムに戻ります。新井教授はコラムの最後で言及しているのは、オックスフォード大学の研究チームが発表した「雇用の未来」という論文です。前回の No.174 でも引用した小林雅一著『AIの衝撃』(講談社 現代新書 2015)から、その概要を紹介します。『AIの衝撃』では、AIの進歩が "雇用の浸食" をもたらすだろうという、ビル・ゲイツ氏(マイクロソフト創業者)の講演の紹介に続いて、次のような文章が出てきます。
この引用における注意点が2つあります。まず、新井教授は「オックスフォード大学のチームが2014年に、機械に代替されやすい職業のトップ20にローンオフィサーをランクインさせた」という主旨の文を書いていますが、引用したオックスフォード大学の研究チームの論文は2013年9月に発表されたものです。従って新井教授が正しければ「機械に代替されやすい職業のトップ20」という発表が、2014年に別にされたことになります。ひょっとしたら新井教授の勘違いかもしれません(2014年となっている所は、正しくは2013年)。しかしどうであれ本質は変わらないので、2013年9月のオックスフォード大学の論文をベースに話を進めます。注意点の2つ目は、引用において、
と書いてあるところです。このうち、②の具体的な推定方法が大事だと思うのですが、そこが書かれていません。オックスフォード大学の論文はネットで公開されているので、それをざっと眺めてみると、おおよそ次のような方法です。
まず「機械に代替されやすさ」を採点するための「職業の数式モデル」を作る必要があります。このモデルの変数を、
の3つとします。それぞれの必要性や重要性が高い仕事ほど機械で代替しにくい、との仮説をまず置くのです。
次に米国・労働省の「O*NET」の各職業に関する記述項目のうち、A B C に影響すると考えれる項目、9個を選びます。たとえば A については3つで「指先の器用さ」「手の器用さ」「窮屈な姿勢での仕事」です。また B は「創造性」と「芸術性」、C は「交渉力」「説得力」「社会的理解力」「他人への援助やケア」です。各職業におけるこれら9つの項目の重要度と必要レベルの数値をもとに、回帰分析の手法で70の職業の "機械化されやすさ" の「採点関数」を求め、その関数を使って702の職業の採点をする、というのが大まか流れです。
これは No.174「ディープマインド」で書いた、コンピュータ将棋における局面の優劣の評価手法と本質的には同じです。つまり、プロの対局で実際に現れた局面をもとに、局面の優劣を判断する評価関数を回帰分析で求め、その関数を使って一般の局面の優劣を判断するという手法と同じです。オックスフォード大学の研究チームは70の代表的な職業が機械で代替されやすいかどうかのAI専門家の判断をもとに、702の職業全部についての判定をAIの手法でやったわけです。
銀行の「融資担当者」と「窓口係」
新井教授の意見とオックスフォード大学の研究チームの結論に共通しているのは、銀行においてAIで代替しやすい職業は融資担当者だということです。つまり半沢直樹は機械化できる、これが共通の結論です。
しかし違っているところもあります。それは、新井教授は窓口係は機械化しにくいと見ているのに対し、オックスフォード大学の研究チームは(融資担当者と同程度に)機械化しやすいと推測していることです。どちらが妥当なのでしょうか。
どうも新井教授に分があるのではと思います。窓口に来た顧客(ないしはコールセンターに電話した顧客)の要望や質問に対して正確に答えることは、十分、コンピュータで出来るようになると思います。しかし、そうであったとしても銀行としては窓口係を配置し、コンピュータの答えも参考にしつつ顧客に寄り添った応対をするのが本筋でしょう。顧客の年齢、緊急度、相談事項の重要度などは千差万別です。まさに新井教授の言うように「一期一会」の対応が必要であり、しかもその対応の数は融資申し込み数より圧倒的に多い。窓口係を機械化することは、銀行の存在基盤を危うくするでしょう。
さっきあげたアマゾンの例が象徴的です。アマゾンは与信審査を完全自動化しているが、アマゾンからオファーをうけた個人事業主は、アマゾンに電話していろいろ聞いているのですね。それで融資を受ける決断をしたわけです。もちろん、コールセンターで運営時間外の問合わせ応答を完全機械化するといったことは、顧客サービスの向上という視点から大いにありうると思います。
この考えからすると、銀行の融資担当者も完全にAIに置き変わるのではないかもしれない。融資可能か否か、可能だとしたらいくらまで可能かは、コンピュータが答えるようになるでしょう。しかし将来の融資担当者はその答えをもとに、融資を申し込んだ顧客と「一期一会の」対応をするのかもしれない。個人事業主からの1000万円の融資申し込みに対し500万円までしか貸せないとしたら、どのように事業を改善すればいいか、その相談に乗るとか・・・・・・。あくまで想定ですが、機械(AIを搭載したコンピュータ)をうまく使いつつ、より高度なサービスを展開するというやり方です。
とは言うものの、この銀行の融資担当者(半沢直樹)と窓口係の話は、我々に大きな意識変革を迫っていると感じます。私たちは暗黙に融資担当者の方が窓口係より価値が大きいと思い込んでいるわけです。実際、銀行に入社10年目の融資担当者と窓口係の給料を比較してみると、大きな差がついているはずです。前者の方が銀行にとって重要であり、ノウハウも知識も経験も必要な仕事だと見なされているからです。
しかし半沢直樹は機械化できる。窓口係よりも機械化しやすいか、少なくとも窓口係と同程度に機械化しやすいのです。つまり、仕事の付加価値は今後、大きく変貌するかもしれないという認識を私たちは持つべきでしょう。
料理人の価値とは
オックスフォード大学の『雇用の未来』という研究報告をつらつら眺めてみると、いろいろとおもしろい発見があります。その一つですが、上に引用した小林雅一著『AIの衝撃』で、仕事をコンピュータに奪われやすい職種として「料理人」がありました。
のところです。ここで言う料理人(Cook)とは、決められレシピ通りに料理を作る人という意味であり、新しい料理のレシピを考える人は、当然ですが「奪われにくい」のだと思います。実は、オックスフォード大学の研究報告では Cook が3つに分かれています。
つまり『AIの衝撃』に引用されている「料理人: 96%」とは「Cooks, Restaurant(レストランの料理人): 96%」のことであり、それよりも比較的仕事を奪われにくいのは「Cooks, Fast Food(ファストフードの料理人): 81%」なのです。我々は暗黙に、ファストフードで料理を作る店員の方が機械化しやすいと考えるのですが、そうではない。この報告では料理の値段が高いか安いかよりも「短時間に素早く料理をつくる必要性」が「機械に仕事を奪われにくい」理由になっているようです。
もちろんこれはAI専門家による推測に過ぎないし、15%程度の差異を議論するのは妥当ではないでしょう。たとえ機械化しやすいとしても、高価な料理は料理人が自らの手で "心をこめて" 作るのが当然とされるでしょうから、"社会的に" 機械化しにくいはずです。技術論だけで「仕事を奪われる・奪われない」という議論をするのも意味がありません。
しかし「料理人の機械化」の話は、先ほどの「融資担当者と窓口係」と同じく、仕事の価値とは何かについての一つの教訓と考えられると思います。我々には、現代社会における給料の多寡や "社会的地位" からくる暗黙の思い込みがあるのではないか・・・・・・。その思いこみを排して考えたとき、仕事の真の価値とは何かが見えてくるでしょう。
機械化によって仕事が変貌するとともに、不必要な仕事・職業が出てくるのも必定です。この数十年の例から言うと、たとえば「バスの車掌」という職業がそうです。バス内部の機械化によって運転手が車掌を兼ねるようになった。もっと大きく言うと、教科書で習った世界史では英国の産業革命の時代に機械化に反対する労働者の暴動まで起きました。何回か引用した『AIの衝撃』には、産業革命よりもっと前の歴史エピソードが出てきます。
エリザベス一世の思考に入っていなかったのは、靴下編み機を使うと製造コストが大きく下がり、臣民に広く靴下が行き渡るだろうということです。その方が、全体として英国経済の活性化に寄与するはずです。ただし仕事を追われる人たちが出てくる・・・・・・。
ともかく、エリザベス一世の時代から400数十年がたっているのですが、その間ずっと「機械が仕事を奪う」現象が世界のどこかで起き続けてきたわけです。その一方で、機械による効率化で国全体の経済が発展し、人々の暮らしが楽になり、余裕が出てきたとも言える。健康を損なうような "奴隷的肉体労働" も無くなった。ものごとには両面の見方があります。今また、その「機械化」の大きな波が来ようとしている。そう考えられると思いました。
みずほ銀行とソフトバンクは2016年9月15日、個人向け融資における与信審査を自動化したサービス提供に乗り出すことを発表しました。
あくまで個人向けの融資ですが、このブログの本文に書いた新井教授の「半沢直樹は機械化できる」という予想が、日本でも現実化してきたわけです。
ソフトバンクとみずほ銀行の発表の一番のポイントは、将来の能力や稼ぐ力も考慮して貸し出すというところですね。これには、いわゆるビッグデータが必要です。つまり現代日本の個人の年収と、その人の学歴や家族構成、家族の職歴、居住地区・番地をはじめとする個人情報のビッグデータです。これをAI技術で分析し、将来の能力や稼ぐ力を推定する。どこまでの個人情報を収集する(した)のか、それは完全に秘密にされるでしょうが、個人の購買履歴やライフスタイルに関するさまざまな情報が参考になると思われます。もちろん推定がハズレることもあるでしょうが、個人向けローンのビジネスが成立する程度の正確さで推定できればよいわけで、それが出来るというのが新会社設立の背景です。
「若者がもつ将来の能力や稼ぐ力に合わせて貸し出せる。若者が夢をかなえられる」という孫社長の発言の裏にあるのは、
ということであり、既にそういう時代に突入していることは認識しておくべきでしょう。
2018年1月22日、Amazon はシアトルに「レジ係がいないコンビニ」をオープンさせました。ここにはAI技術が駆使されています。本文の中で紹介したオックスフォード大学の「雇用の未来」に、AIによって職を奪われやすい職種として「小売店などのレジ係」が "97%の高確率" でリストアップされていました。それが現実化する第1歩が踏み出されたわけです。日本経済新聞の記事(オープン直前に書かれた記事)を引用します。
記事の見出しだけを読むと誤解しそうですが、この店舗は無人でありません。総菜を調理する人や商品の棚出しをする人、警備員などはいます。これは「レジ係無しの店舗」です。日本でも広がってきたセルフ・レジは決して無人のレジではなく、レジ係を利用客に代行させるという奇妙なレジですが、アマゾンの店舗は本物の無人レジであり、その意味では画期的でしょう。
報道で思ったのは、やはり AI(ないしは、AIを含む広い意味での機械)で代替しやすい仕事と、そうではない仕事があることです。多くのスーパーで見られるような「バーコードをスキャンし決済するだけのレジ係」は機械で完全に代替されてしまうことが証明されました。しかし日本のコンビニのような「多機能レジ係」はそうとも言えないでしょう。コンビニでは「スキャンと決済」だけでなく、保温商品の提供(おでんやフライなど)、代行収納、宅配便の保管、チケットの販売など、"コンビニエンス" を利用客に提供するための多様な業務を行っています。仕事の価値とは何かを考えさせられます。
アマゾンの店舗で使われているAI技術は非公開のようです。技術の詳細が分かると悪用されるからでしょうが、今後、研究が進んで徐々にメディアで報道されると思います。たとえば、利用者のプライバシーに配慮して顔認識はあえてせず、服装などで人を特定していると米メディアが既に報じています。この、店舗全体を自販機に変えてしまう技術に注目したいと思います。
AI(人工知能)が広まってくると「今まで人間がやっていた仕事、人間しかできないと思われていた仕事で、AIに置き換えられるものが出てくるだろう」と予測されています。これについて、国立情報学研究所の新井紀子教授が新聞にユニークなコラムを書いていたので、それをまず紹介したいと思います。新井教授は、例の「ロボットは東大に入れるか」プロジェクトのディレクターです。
金融におけるITの活用
新井教授は、金融サービスにおける "フィンテック" が日本を含む世界で熱を帯びていることから話を始めます。
|
2014年末、三井住友銀行とみずほ銀行は、コールセンター業務にIBMの人工知能コンピュータ「ワトソン」を導入すると発表しました。新井教授はそういった銀行業界の動きを言っています。しかし新井教授によると、窓口業務よりも、もっとAI向きの銀行業務があると言います。
|
こういうコラムを読むと、研究者と言えども一般向けに文章を書く(ないしは講演をする)ときには、言葉の使い方が極めて重要だということがよく分かります。「銀行の融資業務は機械化できる」というよりも、「半沢直樹は機械化できる」と言った方が圧倒的にインパクトが強いわけです。研究者も、言いたい事の本質を伝えられる。
新井教授が主導している「ロボットは東大に入れるか」プロジェクトも同じです。「ロボットは大学入試に受かるか」ではなく、あえて「東大」としてあります。プロジェクトの存在感を内外に示すためには、ここは是非とも「東大」でないとまずいのでしょう。しかも最後は「か」という疑問形です。このプロジェクトによって「ロボットが東大に入れるようになるのか、ならないのか、分からない」ようにしてあるわけです。想像ですが、ロボットが東大入試問題を解いて合格するのは無理だと、新井教授は思っているのではないでしょうか。特定の科目で合格点をとるならまだしも・・・・・・。しかし、無理だと言ってしまうと身もフタもない。国立の研究所としては、このプロジェクトを進めることで日本のAI研究を底上げするのが目的でしょうから、ここは疑問形が最適なのですね。
コラムに戻って、では、新井教授は銀行の窓口業務をどう考えているのでしょうか。
|
確かに窓口での対応は、銀行が顧客に直に接する最前線の一つです。融資担当者(ローンオフィサー)も最前線ですが、接する顧客の数が全く違います。窓口では、顧客のそのときの状況にマッチした「一期一会」の対応が、本来、大変に需要なのです。
|
アマゾンによる与信審査の完全自動化
新井教授がコラムの最後で書いている「与信審査の完全自動化」ですが、アマゾンはすでに日本でもやっています。
|
アマゾンにとってみると、適切な事業者(=アマゾン出店者)に、適切な金額を必要な時期に融資できれば、アマゾン経由の通販の量が増え、それによって手数料収入が増える。さらに融資の金利が収入になる。一石二鳥とはこのことでしょう。
事業者のビジネス動向をつぶさにとらえられるという、インターネット通販の特性を生かしたアマゾンのビジネスです。その意味では「融資を断った地方銀行」とは立場が違うのですが、コトの本質は「与信審査は自動化できる」ということです。銀行にその波が押し寄せるのは時間の問題でしょう。
雇用の未来:The Future of Employment
新井教授のコラムに戻ります。新井教授はコラムの最後で言及しているのは、オックスフォード大学の研究チームが発表した「雇用の未来」という論文です。前回の No.174 でも引用した小林雅一著『AIの衝撃』(講談社 現代新書 2015)から、その概要を紹介します。『AIの衝撃』では、AIの進歩が "雇用の浸食" をもたらすだろうという、ビル・ゲイツ氏(マイクロソフト創業者)の講演の紹介に続いて、次のような文章が出てきます。
|

| |||
| ① | 70の職業の「機械に代替されやすさ」をAI専門家が採点し、 | ||
| ② | この採点をもとに、702の職業の「機械に代替されやすさ」を、回帰分析の手法で推定した |
と書いてあるところです。このうち、②の具体的な推定方法が大事だと思うのですが、そこが書かれていません。オックスフォード大学の論文はネットで公開されているので、それをざっと眺めてみると、おおよそ次のような方法です。
まず「機械に代替されやすさ」を採点するための「職業の数式モデル」を作る必要があります。このモデルの変数を、
| 知覚による手作業 | |||
| 知的創造 | |||
| 社会スキル |
の3つとします。それぞれの必要性や重要性が高い仕事ほど機械で代替しにくい、との仮説をまず置くのです。
次に米国・労働省の「O*NET」の各職業に関する記述項目のうち、A B C に影響すると考えれる項目、9個を選びます。たとえば A については3つで「指先の器用さ」「手の器用さ」「窮屈な姿勢での仕事」です。また B は「創造性」と「芸術性」、C は「交渉力」「説得力」「社会的理解力」「他人への援助やケア」です。各職業におけるこれら9つの項目の重要度と必要レベルの数値をもとに、回帰分析の手法で70の職業の "機械化されやすさ" の「採点関数」を求め、その関数を使って702の職業の採点をする、というのが大まか流れです。
これは No.174「ディープマインド」で書いた、コンピュータ将棋における局面の優劣の評価手法と本質的には同じです。つまり、プロの対局で実際に現れた局面をもとに、局面の優劣を判断する評価関数を回帰分析で求め、その関数を使って一般の局面の優劣を判断するという手法と同じです。オックスフォード大学の研究チームは70の代表的な職業が機械で代替されやすいかどうかのAI専門家の判断をもとに、702の職業全部についての判定をAIの手法でやったわけです。
銀行の「融資担当者」と「窓口係」
新井教授の意見とオックスフォード大学の研究チームの結論に共通しているのは、銀行においてAIで代替しやすい職業は融資担当者だということです。つまり半沢直樹は機械化できる、これが共通の結論です。
しかし違っているところもあります。それは、新井教授は窓口係は機械化しにくいと見ているのに対し、オックスフォード大学の研究チームは(融資担当者と同程度に)機械化しやすいと推測していることです。どちらが妥当なのでしょうか。
どうも新井教授に分があるのではと思います。窓口に来た顧客(ないしはコールセンターに電話した顧客)の要望や質問に対して正確に答えることは、十分、コンピュータで出来るようになると思います。しかし、そうであったとしても銀行としては窓口係を配置し、コンピュータの答えも参考にしつつ顧客に寄り添った応対をするのが本筋でしょう。顧客の年齢、緊急度、相談事項の重要度などは千差万別です。まさに新井教授の言うように「一期一会」の対応が必要であり、しかもその対応の数は融資申し込み数より圧倒的に多い。窓口係を機械化することは、銀行の存在基盤を危うくするでしょう。
さっきあげたアマゾンの例が象徴的です。アマゾンは与信審査を完全自動化しているが、アマゾンからオファーをうけた個人事業主は、アマゾンに電話していろいろ聞いているのですね。それで融資を受ける決断をしたわけです。もちろん、コールセンターで運営時間外の問合わせ応答を完全機械化するといったことは、顧客サービスの向上という視点から大いにありうると思います。
この考えからすると、銀行の融資担当者も完全にAIに置き変わるのではないかもしれない。融資可能か否か、可能だとしたらいくらまで可能かは、コンピュータが答えるようになるでしょう。しかし将来の融資担当者はその答えをもとに、融資を申し込んだ顧客と「一期一会の」対応をするのかもしれない。個人事業主からの1000万円の融資申し込みに対し500万円までしか貸せないとしたら、どのように事業を改善すればいいか、その相談に乗るとか・・・・・・。あくまで想定ですが、機械(AIを搭載したコンピュータ)をうまく使いつつ、より高度なサービスを展開するというやり方です。
とは言うものの、この銀行の融資担当者(半沢直樹)と窓口係の話は、我々に大きな意識変革を迫っていると感じます。私たちは暗黙に融資担当者の方が窓口係より価値が大きいと思い込んでいるわけです。実際、銀行に入社10年目の融資担当者と窓口係の給料を比較してみると、大きな差がついているはずです。前者の方が銀行にとって重要であり、ノウハウも知識も経験も必要な仕事だと見なされているからです。
しかし半沢直樹は機械化できる。窓口係よりも機械化しやすいか、少なくとも窓口係と同程度に機械化しやすいのです。つまり、仕事の付加価値は今後、大きく変貌するかもしれないという認識を私たちは持つべきでしょう。
料理人の価値とは
オックスフォード大学の『雇用の未来』という研究報告をつらつら眺めてみると、いろいろとおもしろい発見があります。その一つですが、上に引用した小林雅一著『AIの衝撃』で、仕事をコンピュータに奪われやすい職種として「料理人」がありました。
| 職 業 | 奪われる確率 |
| 料理人 | 96% |
のところです。ここで言う料理人(Cook)とは、決められレシピ通りに料理を作る人という意味であり、新しい料理のレシピを考える人は、当然ですが「奪われにくい」のだと思います。実は、オックスフォード大学の研究報告では Cook が3つに分かれています。
| 職 業 | 奪われる確率 |
| Cooks, Restaurant | 96% |
| Cooks, Short Order | 94% |
| Cooks, Fast Food | 81% |
つまり『AIの衝撃』に引用されている「料理人: 96%」とは「Cooks, Restaurant(レストランの料理人): 96%」のことであり、それよりも比較的仕事を奪われにくいのは「Cooks, Fast Food(ファストフードの料理人): 81%」なのです。我々は暗黙に、ファストフードで料理を作る店員の方が機械化しやすいと考えるのですが、そうではない。この報告では料理の値段が高いか安いかよりも「短時間に素早く料理をつくる必要性」が「機械に仕事を奪われにくい」理由になっているようです。
もちろんこれはAI専門家による推測に過ぎないし、15%程度の差異を議論するのは妥当ではないでしょう。たとえ機械化しやすいとしても、高価な料理は料理人が自らの手で "心をこめて" 作るのが当然とされるでしょうから、"社会的に" 機械化しにくいはずです。技術論だけで「仕事を奪われる・奪われない」という議論をするのも意味がありません。
しかし「料理人の機械化」の話は、先ほどの「融資担当者と窓口係」と同じく、仕事の価値とは何かについての一つの教訓と考えられると思います。我々には、現代社会における給料の多寡や "社会的地位" からくる暗黙の思い込みがあるのではないか・・・・・・。その思いこみを排して考えたとき、仕事の真の価値とは何かが見えてくるでしょう。
機械化によって仕事が変貌するとともに、不必要な仕事・職業が出てくるのも必定です。この数十年の例から言うと、たとえば「バスの車掌」という職業がそうです。バス内部の機械化によって運転手が車掌を兼ねるようになった。もっと大きく言うと、教科書で習った世界史では英国の産業革命の時代に機械化に反対する労働者の暴動まで起きました。何回か引用した『AIの衝撃』には、産業革命よりもっと前の歴史エピソードが出てきます。
|
エリザベス一世の思考に入っていなかったのは、靴下編み機を使うと製造コストが大きく下がり、臣民に広く靴下が行き渡るだろうということです。その方が、全体として英国経済の活性化に寄与するはずです。ただし仕事を追われる人たちが出てくる・・・・・・。
ともかく、エリザベス一世の時代から400数十年がたっているのですが、その間ずっと「機械が仕事を奪う」現象が世界のどこかで起き続けてきたわけです。その一方で、機械による効率化で国全体の経済が発展し、人々の暮らしが楽になり、余裕が出てきたとも言える。健康を損なうような "奴隷的肉体労働" も無くなった。ものごとには両面の見方があります。今また、その「機械化」の大きな波が来ようとしている。そう考えられると思いました。
| 補記1:与信審査の自動化 |
みずほ銀行とソフトバンクは2016年9月15日、個人向け融資における与信審査を自動化したサービス提供に乗り出すことを発表しました。
|

| |||
|
みずほフィナンシャルグループの佐藤康博社長とソフトバンクグループの孫正義社長の記者会見。2016年9月15日。
(site : mainichi.jp)
| |||
ソフトバンクとみずほ銀行の発表の一番のポイントは、将来の能力や稼ぐ力も考慮して貸し出すというところですね。これには、いわゆるビッグデータが必要です。つまり現代日本の個人の年収と、その人の学歴や家族構成、家族の職歴、居住地区・番地をはじめとする個人情報のビッグデータです。これをAI技術で分析し、将来の能力や稼ぐ力を推定する。どこまでの個人情報を収集する(した)のか、それは完全に秘密にされるでしょうが、個人の購買履歴やライフスタイルに関するさまざまな情報が参考になると思われます。もちろん推定がハズレることもあるでしょうが、個人向けローンのビジネスが成立する程度の正確さで推定できればよいわけで、それが出来るというのが新会社設立の背景です。
「若者がもつ将来の能力や稼ぐ力に合わせて貸し出せる。若者が夢をかなえられる」という孫社長の発言の裏にあるのは、
| 「本人からの申告データ」と「合法的に入手できるデータから推定できる個人情報」をもとに、AI技術を使って、個人向け融資ビジネスに使える程度の正確さで、本人の将来の稼ぐ力を推定できる |
ということであり、既にそういう時代に突入していることは認識しておくべきでしょう。
(2016.9.18)
| 補記2:アマゾン・ゴー |
2018年1月22日、Amazon はシアトルに「レジ係がいないコンビニ」をオープンさせました。ここにはAI技術が駆使されています。本文の中で紹介したオックスフォード大学の「雇用の未来」に、AIによって職を奪われやすい職種として「小売店などのレジ係」が "97%の高確率" でリストアップされていました。それが現実化する第1歩が踏み出されたわけです。日本経済新聞の記事(オープン直前に書かれた記事)を引用します。
|

| |||
|
Amazon Goの出入り口
| |||
報道で思ったのは、やはり AI(ないしは、AIを含む広い意味での機械)で代替しやすい仕事と、そうではない仕事があることです。多くのスーパーで見られるような「バーコードをスキャンし決済するだけのレジ係」は機械で完全に代替されてしまうことが証明されました。しかし日本のコンビニのような「多機能レジ係」はそうとも言えないでしょう。コンビニでは「スキャンと決済」だけでなく、保温商品の提供(おでんやフライなど)、代行収納、宅配便の保管、チケットの販売など、"コンビニエンス" を利用客に提供するための多様な業務を行っています。仕事の価値とは何かを考えさせられます。
アマゾンの店舗で使われているAI技術は非公開のようです。技術の詳細が分かると悪用されるからでしょうが、今後、研究が進んで徐々にメディアで報道されると思います。たとえば、利用者のプライバシーに配慮して顔認識はあえてせず、服装などで人を特定していると米メディアが既に報じています。この、店舗全体を自販機に変えてしまう技術に注目したいと思います。
(2018.1.23)
No.174 - ディープマインド [技術]
最近の記事で、AI(Artificial Intelligence。人工知能)について3回書きました。
の3つです。No.159 の "AIBO" は AI技術を利用したソニーの犬型ロボットで、1999年に発売が開始され、2006年に販売終了しました。さすがソニーと思える先進的な製品です。また、No.166「データの見えざる手(2)」で紹介したのは「ホームセンターの業績向上策」をAI技術を利用して見い出したという事例でした。さらにNo.173は、グーグルが人々の検索ワードを蓄積したビッグデータをもとに、AI技術を応用してインフルエンザの流行予測を行った例でした。
そのAI関連の継続で、今回はグーグルが2014年に買収した英国の会社、ディープマインド社について書きたいと思います。この会社がつくった「アルファ碁」というコンピュータ・プログラムは、囲碁の世界トップクラスの棋士と対戦して4勝1敗の成績をあげ、世界中で大変な話題になりました。
「アルファ碁」とイ・セドル九段の5番勝負
2016年3月、韓国のイ・セドル(李世乭)九段とディープマインド社の「アルファ碁」の5番勝負がソウル市内で行われ、「アルファ碁」の4勝1敗となりました。イ・セドル九段は世界のトップクラスの棋士であり(世界No.1とも、No.2とも言われる)、囲碁の世界では大変な強豪です。コンピュータはその棋士に "勝った" ことになります。
もっとも、これが真に "対等な勝負" なのかは疑問があります。それは、「アルファ碁」は世界のプロ棋士の過去の対局・数十万の棋譜を記憶しているが(数は推定。後述)、イ・セドル九段はもちろんそんな数の棋譜を知っているわけではないし、さらに「アルファ碁」の棋譜もほとんど知らなかったと想定できることです。想像ですが「アルファ碁」は過去のイ・セドル九段の全対局を "予習" したのではないでしょうか。ディープマインド社にとって(そしてグーグルにとって)イ・セドル九段に勝つことは会社の価値を上げる最大の見せ場になるからです。違うかもしれません。しかし「相手の手の内を知る」という意味で、双方には圧倒的な情報格差があったことは事実でしょう。
それに加えて、人間側には不利な面があります。それは「人間があるがゆえの弱点」です。まず、イ九段には "この対局に負けると囲碁2000年の歴史を汚す" というような精神的プレッシャーがあったと想像できます。また、第1局に負けたあとは当然、大きな焦りが出てきただろうし、人間には一般的に言って「体調が悪い」とか「疲れ」とか「集中力が切れる」とかの弱さがあります。機械にはこういった弱点は全くありません。単純には比較できない感じがします。
とはいえ従来、コンピュータ囲碁がトップクラスの棋士に勝てる日などいつになるか分からないと考えられていたものが、こんなにも早く勝利するとは素晴らしいことだと思います。報道で「機械が勝利するのにあと10年はかかると考えられていた」とありましたが、IT技術やコンピュータ技術がこれだけ急速に進歩する中で「10年はかかる」というのは「いつになるか分からない」と同じことでしょう。その意味で、ディープマインド社の技術は凄いと言えます。まるで生命の突然変異のように急激な進化を遂げたように感じます。
この「アルファ碁」を開発したディープマインドとはどういう会社でしょうか。
ディープマインドの設立
グーグルは2014年1月に英国・ディープマインド社を推定4億ポンド(約700億円)で買収しました。そのとき設立3年目に入っていたディープマインドは、まだ売り上げを出していなかったし、それどころか製品すら出していなかった。なぜグーグルは約700億円も投じてそんな会社を買収したのでしょうか。実績のないベンチャー・ビジネスに対する投資としては金額が大きすぎます。
ディープマインド社は 2011年に3人の共同創業者によってロンドンで設立されました。いずれも20~30代の青年です。その共同創業者の一人がデミス・ハサビス氏で、現在の最高経営責任者(CEO)であり、アルファ碁開発の中心人物です。イ・セドル九段との5番勝負の報道でも、たびたび登場しました。
以下、小林雅一著『AIの衝撃』(講談社 現代新書 2015) から引用します。小林氏はKDDI研究所のリサーチフェローです。
から引用します。小林氏はKDDI研究所のリサーチフェローです。
この経歴をみるとハサビス氏はコンピュータ・サイエンスを学んだあと、脳の研究に取り組み、そのあとにディープマインド社を設立しています。おそらく新たなAI技術を確立するため海馬を研究し、そしてベンンチャー・ビジネスを起こすという長期的な考えがあったと想像されます。
引用中で "ニューラルネット" と書かれているのは、脳の神経細胞(ニューロン)の機能を模擬したコンピュータ・プログラムです。その中でも、多段に構成したニューラルネット(ディープ・ニューラルネットワーク)を用いて機械に学習をさせる「深層学習(ディープ・ラーニング)」が、現在のAI研究の主流になっています。ハサビス氏がディープマインド社で開発したのは深層学習の一分野である「強化学習」と呼ばれるジャンルのプログラムです。では、引用にある「過去の経験から何かを学んで、それを未来の行動に反映させるニューラルネット」とはどういうものでしょうか。
小林氏の『AIの衝撃』は一般読者向けに書かれた新書であり、その制約の中で「強化学習」を説明するのは難しいことがよく分かります。ちゃんと説明するのなら本来、数式を出さざるを得ないのでしょう。従って上の引用のような説明になり、我々読者としても "感覚的に" 理解するしかありません。
この説明のポイントは「限定的なフィードバック」というところですね。プログラムが出した答えに対して、OK / NG などの簡潔なフィードバックを与えることで、プログラムが学習し、正しい答えを出すように自ら変化していく。OK / NG だけでなく、どの程度 OK か、どの程度ダメかという点数を教えるのも「限定的なフィードバック」と考えられます。とにかく「この点がダメだから、ここをもう少しこういう風に直したらいい」というような "微に入り細に渡る" フィードバックではなく「限定的なフィードバック」を返すことによって、ニューラルネットのプログラムを成長させる。ここがポイントでしょう。
ゲーム機でスカッシュを模した単純なゲームで遊ぶことを考えてみます。ビデオ画面にはボールが上方から投げられ、それを下辺にあるラケットを左ボタン・右ボタンを動かすだけで打ち返す。再び上・左・右の壁で跳ね返ってきたボールをまた打ち返す。ボールのスピードはだんだん早くなり、打ち返せなかったらゲーム終了。打ち返した数がポイントになり、そのポイントの多さを競う。そういうゲームを想定します。
とすると、ディープマインド社の「強化学習型のディープ・ラーニング = 深層強化学習」は次のようなことが出来ることになります。そのコンピュータ・プログラムに、0.1秒ごとのビデオ画面の画像データを送り込む。そうすると直前の数個の画面データを覚えていたコンピュータ・プログラムは、どのボタンを押すか(押し続けるか・離すか)を判断する。これを0.1秒ごとに繰り返す。ボールを打ち返せなければNGのフィードバックを与え、多く打ち返せるとOKのフィードバックをポイント分だけ与える。そうすると、初めはすぐにゲーム終了になるが、次第にコンピュータ・プログラムは玉を打ち返すようになる・・・・・・。
強化学習ができるということは、そういうことになります。当初、コンピュータ・プログラムはゲームのルールを知りません。次第に上達するということは、コンピュータ・プログラムがルールを「理解した」と考えてもいいわけです。
これは革新的な技術です。なぜなら、ゲームをしてフィードバックを返すということがすべてコンピュータ内部で出来るわけであり、24時間、365日、延々とゲームを繰り返えせるからです。そのたびに深層強化学習のプログラムは、少づつ "賢く" なっていく。ついには人間に追いつくでしょう。この "スカッシュ ゲーム" どおりのことがあったわけではありませんが、ごく簡略化して書くと、本質的にはこのようだと思います。
事実、ディープマインド社はゲームソフトで有名なアタリ社の商用ゲームで強化学習の有用性を実証したのです。
実はグーグルのディープマインド買収のきっかけになったのは、この「ビデオ・ゲームを人間並に(人間以上に)うまくやるAIプログラム」だったのです。
アルファ碁(AlphaGo)
ディープマインドが開発したアルファ碁の話です。「Nature ダイジェスト 2016年3月号」にその技術の紹介が載っていました。この号が発売された時点で、イ・セドル九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。ディープマインド社はそれを踏まえ、「Nature誌 1月17日号」に「機械学習によって人工知能(AI)が囲碁をマスターした」との発表をしました。そのダイジェストが2016年3月号の記事です。
まず大切なことがあります。従来のボード・ゲームのプログラムは、そのゲーム専用のものでした。チェスの世界チャンピオンを破ったIBMのディープ・ブルー、日本で多く開発されているコンピュータ将棋のソフト、欧米や日本で盛んな囲碁ソフトなどは皆そうです。しかしアルファ碁は違います。
小林雅一『AIの衝撃』にも、アタリ社が開発した卓球ゲームをAIがマスターしたことが書かれていました。それと同じ種類のプログラムが囲碁をマスターしたというわけです。もちろん、基本的な囲碁のルール(たとえば、ダメを打てるのは相手の石を取る時だけとか、コウはすぐには取り返せないとか、地の多さで勝敗を決めるとか・・・・・・)は覚え込ませる必要があります。しかし基本的にはビデオ・ゲームをプレイするのと同じアルゴリズムで囲碁をするというわけです。ここは重要だと思います。というのも、汎用アルゴリズムであるからには他のゲームにも応用が利くし、さらにはゲームを越えて各種の社会問題にも適用できる可能性を示唆しているからです。「Nature ダイジェスト」には、囲碁をマスターした具体的なやりかたが書かれています。
ここの説明のポイントは、
というところです。日本で盛んなコンピュータ将棋のプログラムからの類推で考えますと、コンピュータ将棋で第一に重要なのは、局面の形勢(優劣)を判断する「評価関数」を作ることです。コンピュータ将棋の初期において、評価関数は将棋の知識のあるプログラム開発者の "手作り" でした。つまり、どういう変数を使い、どのような演算をして局面の優劣を的確に判断できる「評価値」を導くのか、それはプログラム開発者の将棋の経験にたよっていました。
この状況を一変させ、コンピュータ将棋がプロの棋士を破るまでになったのは、2005年に公開された Bonanza(ボナンザ)が契機でした。Bonanzaは当時カナダのトロント在住の学者(専門は化学)、保木邦仁氏が開発したプログラムですが、画期的だったのは評価関数の作成に「機械学習」を取り入れたことです。つまり保木氏はプロ棋士の棋譜を6万局以上集め、統計で用いる回帰分析の手法で評価関数を作り出したのです。この関数に使われた変数は1万以上と言います。
将棋の平均手数を120手とすると(これはいろんな説があります。仮に、ということです)、6万局の棋譜には720万の局面があることになります。この720万の局面には、それぞれ一つ前の局面があります。そこからプロが1手を指してその局面になったわけです。ということは、プロが指さなかった多数の手(将棋のルールでは可能な手)があることになり、その多数の手によって実際には現れなかった局面が仮定できます。評価関数としては「実際には現れなかった局面」より「実際に現れた局面」の評価が高くなるように変数を決め、関数を調整するということになります。
もちろんプロと言えども「最善手」を常に指せるわけではないし、中には「悪手」もあるでしょう。しかし悪手といっても「プロが指した悪手」です。アマチュアの悪手とはわけが違う。さらに6万局の中には「アマチュアでもやらないようなポカミス」が混じっていることもありうる。しかしそのような手はプロである限りごく少数であり、評価関数の大勢には影響しないでしょう。
重要なことは、こういった機械学習の手法で評価関数を作るのに将棋の棋力はあまりいらないことです。保木氏は著書(「ボナンザ VS 勝負脳」角川書店 )で、自分の棋力をアマチュア5級程度と述べています。棋力よりも統計学や数学、コンピュータ・サイエンス、論理的思考の勝負です。
)で、自分の棋力をアマチュア5級程度と述べています。棋力よりも統計学や数学、コンピュータ・サイエンス、論理的思考の勝負です。
以上を踏まえてアルファ碁の話に戻りますと、上の引用の中に、
と書かれているのは、コンピュータ将棋で言うと「評価関数を作った」ということと同等でしょう。それをディープマインド社はニューラルネットワークを用い、深層学習の手法で行った。その手順は引用にあるように、
なわけです。グーグルがネット上に公開されている大量の猫の写真をもとに深層学習で「与えられた画像が、猫か猫でないか」を判別するプログラムを作ったと話題になったことがありました。また深層学習を使った手書き文字の認識プログラムも同じです。人間は猫の特徴やアルファベットの各文字の特徴をプログラムに教えず、プログラムが深層学習で判別能力をつけていく。アルファ碁もそれと同様です。囲碁のある局面は、19×19の合計361の交点に白石があるか、黒石があるか、何もないかのパターンです。そのパターンを入力すると、形勢判断ができる。そういうプログラム(ニューラルネットワーク)を深層学習で作ったことになります。
プロ棋士の3000万通りの局面と書かれています。囲碁の平均手数を仮に200とすると、15万局の棋譜ということになります。囲碁の自由度の多さを考えると、コンピュータ将棋・Bonanzaが機械学習に使った6万局と比べて少ないと感じますが、これがプロ棋士の棋譜を集められる限界だったのかもしれません。
ここでディープマインドの得意技術である「強化学習」が出てきます。「強化学習」とは、先に引用した小林雅一『AIの衝撃』に書かれている通りですが、その強化学習はプログラム同士の自己対局で行ったわけです。もともとアルファ碁が機械学習で "評価関数" を作る際に用いたプロの対局は15万局程度と推定されるのですが、自己対局による強化学習ではそれより遙かに多い対局数をこなしたと想像できます。このあたりに、強化学習というAI技術のメリットが現れていると思います。強化学習を終えたアルファ碁は「市販の(最強の)囲碁プログラムと同等の強さ」になったようです。
このあとは「読みの力」をつける作業です。ふたたびコンピュータ将棋から考えますと、評価関数に続く第二のポイントは「指し手の探索アルゴリズム」です。先手に(評価の高い)数手が考えられ、それぞれの手について後手にも数手が考えられるとすると、これを続けていくことで、いわゆる「ゲーム木(ツリー)」ができます。この「ゲーム木」を探索する必要がある。このとき、先手も後手も最善を尽くすと仮定します。数手~数十手先の「先手にとっての評価が高い局面」を探索するのですが、しかしその先手有利の局面が直前の後手の「悪手」で引き起こされたのなら、それは読みから排除しなければならない(双方が最善の原則)。というように、先々どうなるかを読んで次の一手を決める必要があります。
「ゲーム木」は先読みの数が増えるとすぐに膨大な数になるので、制限時間内にどこまで先を読むか、どの手を評価してどの手を評価しない(読まない)のか、プログラムが判断する必要があります。もちろんコンピュータの性能にも大きく依存します。この「ゲーム木の探索アルゴリズム」の優劣が、プログラムの強さを決める第二のポイントです。上の引用における
のところは、この「ゲーム木の探索」のことを言っているのですが、少々分かりにくい文章です。まず「この探索アプローチ」とは、文のつながり上、「市販の囲碁プログラム(手筋のシミュレーションによって最良の手を選択する)の探索アプローチ」だと理解できます。そして「次に打つ手を選択して碁盤を読む能力」とは、強化学習の結果得られた「盤面の意味を読み取って最良の一手を選択する術」のことだと読めます。つまりアルファ碁は、強化学習で得られたディープマインド独自の "評価関数" と、市販の(最強の)囲碁プログラムと同等の「ゲーム木探索アルゴリズム」を組み合わせたということでしょう。もちろんここで書いた "評価関数" は、多層に重ねられたニューラルネットワーク(ディープ・ニューラルネットワーク)で実現されているものです。
以上の「Nature ダイジェスト」の記事を総括すると、ディープマインドのアルファ碁の独自性とは、
の二つだと読み取れます。つまり一言で言うと「深層強化学習」です。このうち、①の深層学習は他の囲碁プログラムにも実装例があるようです(例:フェイスブック開発のdarkforest)。ということは、最初に紹介した小林氏の『AIの衝撃』にあった「ディープマインドが専門とするAI技術は、ディープラーニングの中でも強化学習と呼ばれる細分化された領域」というところに戻るわけです。そこがアルファ碁の強さの秘密だと判断できます。もっと詳しい技術情報が Wikipedia などのネットで公開されているのですが、細かくなるので割愛したいと思います。
以降、この対局とディープマインドについて強く印象に残った4点をまとめます。「囲碁に新しい風を吹き込む」「コンピュータの歴史の転換点」「人工知能のリスク」「ゲームが導いた革新」の4つの視点です。
囲碁に新しい風を吹き込む
まず「アルファ碁」とイ・セドル九段の5番勝負ですが、この対局に関する各種の報道で印象的だったのは、勝負を観戦した日本のトップ・プロの感想でした。第5局(アルファ碁の勝ち)についての朝日新聞(2016.3.24 夕刊)の記事からです。
二人の意見に共通しているのは、アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということです。これには、なるほどと思いました。
囲碁は最終的には地の多少を争うゲームです。地は隅が作りやすく、その次に作りやすいのが辺で、中央が一番作りにくい。手を読むのも、特に序盤から中盤にかけては、隅→辺→中央の順に読みにくくなります。中央はいちばん手が広い(=たくさんの選択肢がありうる)からです。中央が読みにくいということから、中央を打つときには "感覚" に頼ることが多くなる。この "感覚" がくせ者です。それは先生から弟子へと(王九段が言うように、弟子は先生に叱り飛ばされながら)受け継がれてきたものでしょう。さらには先人から現代の棋士へと受け継がれてきた。その囲碁の歴史で醸成されてきた "感覚" は、果たしてどの程度まで正しいのか。中央の手を読むより、隅や辺の手を精密に読むことに慣れた人間の "感覚" がどこまで正当化できるのか、ということがあると思うのです。
アルファ碁にとって、隅・辺・中央の違いはありません。盤面全体を一つのパターンとしてとらえて最善手を見つけようとする。辺の打ち方で20手先を読むのも、中央の打ち方で20手先を読むのも変わらない。中央の手が広ければ、読みの探索範囲が増えます。従って読みを省略する手は相対的に増えるでしょうが、読む "深さ" は、隅や辺と変わらないはずです。
アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということは、はからずも今までのプロ棋士たちの囲碁研究で「手薄だった」部分が露呈したということではないでしょうか。アルファ碁はそれを明らかにした。上に引用した王九段も井上名人もそれを感じたのではと思います。
二人の発言から感じるのは、囲碁の世界においてもコンピュータと共存していこうという意志です。確かに今回は教えられた、しかしその教えられたことをベースに、自分自身ももっと強くなるぞ、というような二人の意欲を感じます。コンピュータ技術と人間の知恵の相乗効果で、双方がレベルアップしていくという未来を感じさせる、爽やかなコメントでした。
コンピュータの歴史の転換点
アルファ碁の勝利を前にすると、AIは万能のように考えてしまう人が出てくると思いますが、それは違うでしょう。まず、アルファ碁は「人間の知恵の集積」がベースになっています。アルファ碁が機械学習に使った3000万の局面はあくまで近年のものだと思いますが、そのバックには「囲碁2000年の歴史」があり、アルファ碁はそこからスタートしているわけです。しかも人間なら3000万の局面を記憶する必要はなく、少量の過去の棋譜から類推・推量が可能です。
さらに囲碁は「情報が全部開示されている」ゲームですが、ゲームにはそうでないもの(たとえば麻雀)があります。またゲームを離れてAIを広く適用すること考えると、たとえば医療診断では情報は不完全なことが多いし、中には間違った情報があるかも知れない。医療診断にかかわらず、社会で行われている判断の多くはそうです。情報は不完全であり、しかもルールが変わったり、グレーだったりする。囲碁のルールは変わりませんが・・・・・・。AIを万能のように考えるのは大きな誤りでしょう。
とはいえ、アルファ碁がトッププロとの5番勝負に勝ったという「事件」は、非常に素晴らしいことだし、単にゲームの世界の話に留まらないと感じます。IBMのコンピュータがチェスの世界チャンピオンを負かしたことや、クイズ番組で優勝したことよりも格段に大きな事件でしょう。現代のデジタル・コンピュータのルーツは1946年のENIAC(ペンシルヴァニア大学。真空管式)と言われていますが、そうするとコンピュータには70年の歴史があることになります。そのコンピュータ70年の歴史の転換点がこの対局であり、後世の人から必ずそう言われると確信します。
人工知能(AI)のリスク
ディープマインド社は大きなブレークスルーを成し遂げました。しかし一般に科学技術には負の側面があることが多いわけです。ディープマインド社について非常に印象に残った逸話があります。グーグルに買収されるにあたって、ディープマインド社はグーグルに対し「AI倫理委員会」の設立を要求したという件です。
「人類はテクノロジーによって絶滅するだろう」というのは、ずいぶんペシミスティックな発言(ないしは人)ですが、核兵器の前例があるわけですね。AI専門家の重大な警告と受け取った方がいいでしょう。ふと、アーノルド・シュワルツネッガーを一躍スターにした「ターミネーター」を思い出しました。あの映画において、未来は人間とロボットの戦争状態になっているのですが、その発端は「人工知能が人間に核戦争をしかけた」という想定です。
しかし、AIのリスクはそういうことではないと思います。たとえばAI技術を使って新型の核兵器が開発できるかもしれません。現在の核兵器の開発は(条約加盟国は)実験ができず、コンピュータ・シミュレーションで開発されています。AIもコンピュータ技術の一種なのです。また、極めて効果的なサイバー攻撃(テロ)の手段がAI技術で生み出されるかもしれません。もっと一般には、AIを「活用」した犯罪はいくらでも考えられそうな気がします。
他の有用な科学技術と同様、AIも「光」とともに「影」を背負っているということでしょう。ディープマインドのレッグ氏の発言はそれを最も強い形で言ったと解釈できます。逆にいうと AI はそれだけ人間社会へのインパクトが強い技術である。そいういうことかと思いました。
ゲームが導いた革新
ディープマインド社が、自社の「強化学習」の有用性を検証するのに、米・アタリ社のビデオ・ゲームを使ったという話が出てきました。アタリ社は1972年に設立されたビデオ・ゲームの老舗です。設立者はノーラン・ブッシュネルという人ですが、彼は囲碁が大好きで、日本棋院の初段の免状を持っていました。社名の「アタリ」は囲碁用語の「アタリ」(次の手で相手の石が取れる状態)です。
ひょっとしたらノーラン・ブッシュネルはゲーム会社を設立しながら、将来に囲碁プログラムが出てきて人間との対局が可能になり、それがアマチュア高段者なみになり、ついにはプロのトップ棋士を破るまでになることを夢見ていたのかもしれません。反対に、そんなことは夢想だにできなかったのかもしれない。しかし、囲碁プログラムがトップ棋士を破る日は、アタリ社が設立されてから 44年後にやってきた。IT技術の驚くべき進歩です。
さらにコンピュータ・ゲームつながりで言うと、アルファ碁を開発したディープマインド社のデミス・ハサビス氏は、ディープマインドを設立する前にゲーム会社を作っているのですね(小林雅一著『AIの衝撃』)。おそらく彼はゲームのプログラムを開発しながら、そのゲームをプレイするプログラムを作りたいと強く思ったのではないでしょうか。
囲碁、アタリ社、デミス・ハサビス、アルファ碁は、すべて「ゲーム」というキーワードで相互につながっています。人間社会を革新するかもしれない重要なAI技術が、ゲームとの深い関わりの中で生まれてきた。その中でも特に囲碁がAI技術者の挑戦意欲をかき立て、そこで実証された革新が社会に応用されようとしているわけです。
ゲームは「暇つぶし」であり「娯楽」ですが、同時に「頭脳のスポーツ」でもあり、また、それを職業とする人が成立するほど人間社会に根を下ろしたものです。しかしゲームはそれ以上のものでしょう。それは人間社会における革新を導く何かでもある。今回のアルファ碁の勝利で強く思ったのは、それが「ゲームに導かれた技術革新」だということでした。
ディープマインド社のアルファ碁が実現しているアルゴリズムの詳細を、次の二つの記事に書きました。合わせて参照ください。
| AIBOは最後のモルモットか | |||
| データの見えざる手(2) | |||
| インフルエンザの流行はGoogleが予測する |
の3つです。No.159 の "AIBO" は AI技術を利用したソニーの犬型ロボットで、1999年に発売が開始され、2006年に販売終了しました。さすがソニーと思える先進的な製品です。また、No.166「データの見えざる手(2)」で紹介したのは「ホームセンターの業績向上策」をAI技術を利用して見い出したという事例でした。さらにNo.173は、グーグルが人々の検索ワードを蓄積したビッグデータをもとに、AI技術を応用してインフルエンザの流行予測を行った例でした。
そのAI関連の継続で、今回はグーグルが2014年に買収した英国の会社、ディープマインド社について書きたいと思います。この会社がつくった「アルファ碁」というコンピュータ・プログラムは、囲碁の世界トップクラスの棋士と対戦して4勝1敗の成績をあげ、世界中で大変な話題になりました。
「アルファ碁」とイ・セドル九段の5番勝負
2016年3月、韓国のイ・セドル(李世乭)九段とディープマインド社の「アルファ碁」の5番勝負がソウル市内で行われ、「アルファ碁」の4勝1敗となりました。イ・セドル九段は世界のトップクラスの棋士であり(世界No.1とも、No.2とも言われる)、囲碁の世界では大変な強豪です。コンピュータはその棋士に "勝った" ことになります。

| ||
|
AlphaGo vs イ・セドル9段(右)第1局
(YouTube)
| ||
もっとも、これが真に "対等な勝負" なのかは疑問があります。それは、「アルファ碁」は世界のプロ棋士の過去の対局・数十万の棋譜を記憶しているが(数は推定。後述)、イ・セドル九段はもちろんそんな数の棋譜を知っているわけではないし、さらに「アルファ碁」の棋譜もほとんど知らなかったと想定できることです。想像ですが「アルファ碁」は過去のイ・セドル九段の全対局を "予習" したのではないでしょうか。ディープマインド社にとって(そしてグーグルにとって)イ・セドル九段に勝つことは会社の価値を上げる最大の見せ場になるからです。違うかもしれません。しかし「相手の手の内を知る」という意味で、双方には圧倒的な情報格差があったことは事実でしょう。
それに加えて、人間側には不利な面があります。それは「人間があるがゆえの弱点」です。まず、イ九段には "この対局に負けると囲碁2000年の歴史を汚す" というような精神的プレッシャーがあったと想像できます。また、第1局に負けたあとは当然、大きな焦りが出てきただろうし、人間には一般的に言って「体調が悪い」とか「疲れ」とか「集中力が切れる」とかの弱さがあります。機械にはこういった弱点は全くありません。単純には比較できない感じがします。
とはいえ従来、コンピュータ囲碁がトップクラスの棋士に勝てる日などいつになるか分からないと考えられていたものが、こんなにも早く勝利するとは素晴らしいことだと思います。報道で「機械が勝利するのにあと10年はかかると考えられていた」とありましたが、IT技術やコンピュータ技術がこれだけ急速に進歩する中で「10年はかかる」というのは「いつになるか分からない」と同じことでしょう。その意味で、ディープマインド社の技術は凄いと言えます。まるで生命の突然変異のように急激な進化を遂げたように感じます。
この「アルファ碁」を開発したディープマインドとはどういう会社でしょうか。
ディープマインドの設立
グーグルは2014年1月に英国・ディープマインド社を推定4億ポンド(約700億円)で買収しました。そのとき設立3年目に入っていたディープマインドは、まだ売り上げを出していなかったし、それどころか製品すら出していなかった。なぜグーグルは約700億円も投じてそんな会社を買収したのでしょうか。実績のないベンチャー・ビジネスに対する投資としては金額が大きすぎます。
ディープマインド社は 2011年に3人の共同創業者によってロンドンで設立されました。いずれも20~30代の青年です。その共同創業者の一人がデミス・ハサビス氏で、現在の最高経営責任者(CEO)であり、アルファ碁開発の中心人物です。イ・セドル九段との5番勝負の報道でも、たびたび登場しました。
以下、小林雅一著『AIの衝撃』(講談社 現代新書 2015)
|
この経歴をみるとハサビス氏はコンピュータ・サイエンスを学んだあと、脳の研究に取り組み、そのあとにディープマインド社を設立しています。おそらく新たなAI技術を確立するため海馬を研究し、そしてベンンチャー・ビジネスを起こすという長期的な考えがあったと想像されます。

| ||
|
ディープマインド社 デミス・ハサビスCEO
(sie : www.nature.com)
| ||
引用中で "ニューラルネット" と書かれているのは、脳の神経細胞(ニューロン)の機能を模擬したコンピュータ・プログラムです。その中でも、多段に構成したニューラルネット(ディープ・ニューラルネットワーク)を用いて機械に学習をさせる「深層学習(ディープ・ラーニング)」が、現在のAI研究の主流になっています。ハサビス氏がディープマインド社で開発したのは深層学習の一分野である「強化学習」と呼ばれるジャンルのプログラムです。では、引用にある「過去の経験から何かを学んで、それを未来の行動に反映させるニューラルネット」とはどういうものでしょうか。
|
|
| |||
この説明のポイントは「限定的なフィードバック」というところですね。プログラムが出した答えに対して、OK / NG などの簡潔なフィードバックを与えることで、プログラムが学習し、正しい答えを出すように自ら変化していく。OK / NG だけでなく、どの程度 OK か、どの程度ダメかという点数を教えるのも「限定的なフィードバック」と考えられます。とにかく「この点がダメだから、ここをもう少しこういう風に直したらいい」というような "微に入り細に渡る" フィードバックではなく「限定的なフィードバック」を返すことによって、ニューラルネットのプログラムを成長させる。ここがポイントでしょう。
ゲーム機でスカッシュを模した単純なゲームで遊ぶことを考えてみます。ビデオ画面にはボールが上方から投げられ、それを下辺にあるラケットを左ボタン・右ボタンを動かすだけで打ち返す。再び上・左・右の壁で跳ね返ってきたボールをまた打ち返す。ボールのスピードはだんだん早くなり、打ち返せなかったらゲーム終了。打ち返した数がポイントになり、そのポイントの多さを競う。そういうゲームを想定します。
とすると、ディープマインド社の「強化学習型のディープ・ラーニング = 深層強化学習」は次のようなことが出来ることになります。そのコンピュータ・プログラムに、0.1秒ごとのビデオ画面の画像データを送り込む。そうすると直前の数個の画面データを覚えていたコンピュータ・プログラムは、どのボタンを押すか(押し続けるか・離すか)を判断する。これを0.1秒ごとに繰り返す。ボールを打ち返せなければNGのフィードバックを与え、多く打ち返せるとOKのフィードバックをポイント分だけ与える。そうすると、初めはすぐにゲーム終了になるが、次第にコンピュータ・プログラムは玉を打ち返すようになる・・・・・・。
強化学習ができるということは、そういうことになります。当初、コンピュータ・プログラムはゲームのルールを知りません。次第に上達するということは、コンピュータ・プログラムがルールを「理解した」と考えてもいいわけです。
これは革新的な技術です。なぜなら、ゲームをしてフィードバックを返すということがすべてコンピュータ内部で出来るわけであり、24時間、365日、延々とゲームを繰り返えせるからです。そのたびに深層強化学習のプログラムは、少づつ "賢く" なっていく。ついには人間に追いつくでしょう。この "スカッシュ ゲーム" どおりのことがあったわけではありませんが、ごく簡略化して書くと、本質的にはこのようだと思います。
事実、ディープマインド社はゲームソフトで有名なアタリ社の商用ゲームで強化学習の有用性を実証したのです。
|
実はグーグルのディープマインド買収のきっかけになったのは、この「ビデオ・ゲームを人間並に(人間以上に)うまくやるAIプログラム」だったのです。
|
アルファ碁(AlphaGo)
ディープマインドが開発したアルファ碁の話です。「Nature ダイジェスト 2016年3月号」にその技術の紹介が載っていました。この号が発売された時点で、イ・セドル九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。ディープマインド社はそれを踏まえ、「Nature誌 1月17日号」に「機械学習によって人工知能(AI)が囲碁をマスターした」との発表をしました。そのダイジェストが2016年3月号の記事です。
まず大切なことがあります。従来のボード・ゲームのプログラムは、そのゲーム専用のものでした。チェスの世界チャンピオンを破ったIBMのディープ・ブルー、日本で多く開発されているコンピュータ将棋のソフト、欧米や日本で盛んな囲碁ソフトなどは皆そうです。しかしアルファ碁は違います。
|
小林雅一『AIの衝撃』にも、アタリ社が開発した卓球ゲームをAIがマスターしたことが書かれていました。それと同じ種類のプログラムが囲碁をマスターしたというわけです。もちろん、基本的な囲碁のルール(たとえば、ダメを打てるのは相手の石を取る時だけとか、コウはすぐには取り返せないとか、地の多さで勝敗を決めるとか・・・・・・)は覚え込ませる必要があります。しかし基本的にはビデオ・ゲームをプレイするのと同じアルゴリズムで囲碁をするというわけです。ここは重要だと思います。というのも、汎用アルゴリズムであるからには他のゲームにも応用が利くし、さらにはゲームを越えて各種の社会問題にも適用できる可能性を示唆しているからです。「Nature ダイジェスト」には、囲碁をマスターした具体的なやりかたが書かれています。
|
ここの説明のポイントは、
| 何層にも重ねられたニューラルネットワークを使った、ディープラーニング(深層学習)を使って、盤面の形勢を判断する手法を確立した |
というところです。日本で盛んなコンピュータ将棋のプログラムからの類推で考えますと、コンピュータ将棋で第一に重要なのは、局面の形勢(優劣)を判断する「評価関数」を作ることです。コンピュータ将棋の初期において、評価関数は将棋の知識のあるプログラム開発者の "手作り" でした。つまり、どういう変数を使い、どのような演算をして局面の優劣を的確に判断できる「評価値」を導くのか、それはプログラム開発者の将棋の経験にたよっていました。
この状況を一変させ、コンピュータ将棋がプロの棋士を破るまでになったのは、2005年に公開された Bonanza(ボナンザ)が契機でした。Bonanzaは当時カナダのトロント在住の学者(専門は化学)、保木邦仁氏が開発したプログラムですが、画期的だったのは評価関数の作成に「機械学習」を取り入れたことです。つまり保木氏はプロ棋士の棋譜を6万局以上集め、統計で用いる回帰分析の手法で評価関数を作り出したのです。この関数に使われた変数は1万以上と言います。
将棋の平均手数を120手とすると(これはいろんな説があります。仮に、ということです)、6万局の棋譜には720万の局面があることになります。この720万の局面には、それぞれ一つ前の局面があります。そこからプロが1手を指してその局面になったわけです。ということは、プロが指さなかった多数の手(将棋のルールでは可能な手)があることになり、その多数の手によって実際には現れなかった局面が仮定できます。評価関数としては「実際には現れなかった局面」より「実際に現れた局面」の評価が高くなるように変数を決め、関数を調整するということになります。
もちろんプロと言えども「最善手」を常に指せるわけではないし、中には「悪手」もあるでしょう。しかし悪手といっても「プロが指した悪手」です。アマチュアの悪手とはわけが違う。さらに6万局の中には「アマチュアでもやらないようなポカミス」が混じっていることもありうる。しかしそのような手はプロである限りごく少数であり、評価関数の大勢には影響しないでしょう。
重要なことは、こういった機械学習の手法で評価関数を作るのに将棋の棋力はあまりいらないことです。保木氏は著書(「ボナンザ VS 勝負脳」角川書店
以上を踏まえてアルファ碁の話に戻りますと、上の引用の中に、
| 盤面データから形勢に関する抽象的な情報を抽出した |
と書かれているのは、コンピュータ将棋で言うと「評価関数を作った」ということと同等でしょう。それをディープマインド社はニューラルネットワークを用い、深層学習の手法で行った。その手順は引用にあるように、
| 画素に基づいて画像を分類するプログラムと同様 |
なわけです。グーグルがネット上に公開されている大量の猫の写真をもとに深層学習で「与えられた画像が、猫か猫でないか」を判別するプログラムを作ったと話題になったことがありました。また深層学習を使った手書き文字の認識プログラムも同じです。人間は猫の特徴やアルファベットの各文字の特徴をプログラムに教えず、プログラムが深層学習で判別能力をつけていく。アルファ碁もそれと同様です。囲碁のある局面は、19×19の合計361の交点に白石があるか、黒石があるか、何もないかのパターンです。そのパターンを入力すると、形勢判断ができる。そういうプログラム(ニューラルネットワーク)を深層学習で作ったことになります。
プロ棋士の3000万通りの局面と書かれています。囲碁の平均手数を仮に200とすると、15万局の棋譜ということになります。囲碁の自由度の多さを考えると、コンピュータ将棋・Bonanzaが機械学習に使った6万局と比べて少ないと感じますが、これがプロ棋士の棋譜を集められる限界だったのかもしれません。
|
ここでディープマインドの得意技術である「強化学習」が出てきます。「強化学習」とは、先に引用した小林雅一『AIの衝撃』に書かれている通りですが、その強化学習はプログラム同士の自己対局で行ったわけです。もともとアルファ碁が機械学習で "評価関数" を作る際に用いたプロの対局は15万局程度と推定されるのですが、自己対局による強化学習ではそれより遙かに多い対局数をこなしたと想像できます。このあたりに、強化学習というAI技術のメリットが現れていると思います。強化学習を終えたアルファ碁は「市販の(最強の)囲碁プログラムと同等の強さ」になったようです。
このあとは「読みの力」をつける作業です。ふたたびコンピュータ将棋から考えますと、評価関数に続く第二のポイントは「指し手の探索アルゴリズム」です。先手に(評価の高い)数手が考えられ、それぞれの手について後手にも数手が考えられるとすると、これを続けていくことで、いわゆる「ゲーム木(ツリー)」ができます。この「ゲーム木」を探索する必要がある。このとき、先手も後手も最善を尽くすと仮定します。数手~数十手先の「先手にとっての評価が高い局面」を探索するのですが、しかしその先手有利の局面が直前の後手の「悪手」で引き起こされたのなら、それは読みから排除しなければならない(双方が最善の原則)。というように、先々どうなるかを読んで次の一手を決める必要があります。
「ゲーム木」は先読みの数が増えるとすぐに膨大な数になるので、制限時間内にどこまで先を読むか、どの手を評価してどの手を評価しない(読まない)のか、プログラムが判断する必要があります。もちろんコンピュータの性能にも大きく依存します。この「ゲーム木の探索アルゴリズム」の優劣が、プログラムの強さを決める第二のポイントです。上の引用における
| 次にハサビスらはこの探索アプローチを次に打つ手を選択して碁盤を読む能力と組み合わせた |
のところは、この「ゲーム木の探索」のことを言っているのですが、少々分かりにくい文章です。まず「この探索アプローチ」とは、文のつながり上、「市販の囲碁プログラム(手筋のシミュレーションによって最良の手を選択する)の探索アプローチ」だと理解できます。そして「次に打つ手を選択して碁盤を読む能力」とは、強化学習の結果得られた「盤面の意味を読み取って最良の一手を選択する術」のことだと読めます。つまりアルファ碁は、強化学習で得られたディープマインド独自の "評価関数" と、市販の(最強の)囲碁プログラムと同等の「ゲーム木探索アルゴリズム」を組み合わせたということでしょう。もちろんここで書いた "評価関数" は、多層に重ねられたニューラルネットワーク(ディープ・ニューラルネットワーク)で実現されているものです。
以上の「Nature ダイジェスト」の記事を総括すると、ディープマインドのアルファ碁の独自性とは、
| ① | 局面の優劣の判断にディープラーニング(深層学習)による機械学習を用いた | ||
| ② | さらにディープマインド独自の強化学習によって正確な優劣判断ができるようになった |
の二つだと読み取れます。つまり一言で言うと「深層強化学習」です。このうち、①の深層学習は他の囲碁プログラムにも実装例があるようです(例:フェイスブック開発のdarkforest)。ということは、最初に紹介した小林氏の『AIの衝撃』にあった「ディープマインドが専門とするAI技術は、ディープラーニングの中でも強化学習と呼ばれる細分化された領域」というところに戻るわけです。そこがアルファ碁の強さの秘密だと判断できます。もっと詳しい技術情報が Wikipedia などのネットで公開されているのですが、細かくなるので割愛したいと思います。
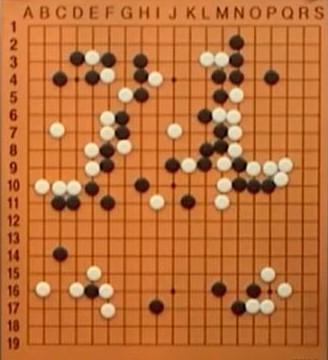
| ||
|
アルファ碁(黒)対 イ・セドル九段(白)第4局
白78(K9)が打たれた局面 イ・セドル九段がアルファ碁に唯一勝ったのが第4局だが、上の図はイ・セドル九段が白78(K9)のワリコミを打った局面。ライブ中継の解説を担当していたマイケル・レドモンド九段は白78を予想していなかったが、打たれた瞬間 "Exciting" と評していた。イ・セドル九段が放った勝負手である。レドモンド九段の解説にあったように、この手は白H6のキリを睨んでいて、黒の応手は難しい。黒にシノギの筋はあるのだが、その読みが簡単ではない。 これ以降、アルファ碁は疑問手を続発し、明らかな悪手も加わって、アルファ碁の投了で終わった。イ・セドル九段の白78は人間の創造力を見せつけた一手だった。 (YouTube)
| ||
以降、この対局とディープマインドについて強く印象に残った4点をまとめます。「囲碁に新しい風を吹き込む」「コンピュータの歴史の転換点」「人工知能のリスク」「ゲームが導いた革新」の4つの視点です。
囲碁に新しい風を吹き込む
まず「アルファ碁」とイ・セドル九段の5番勝負ですが、この対局に関する各種の報道で印象的だったのは、勝負を観戦した日本のトップ・プロの感想でした。第5局(アルファ碁の勝ち)についての朝日新聞(2016.3.24 夕刊)の記事からです。
| 「勉強になりました。右辺を広げる手の中には、いままでの感覚とはかけ離れたものがあった。弟子が打ったら、しかり飛ばすような」(王 銘琬 九段) | |||
| 「こう打てばいいんだよ、と教えてくれているような感じでした。空間や中央の感覚が人間と違う。懐が深い」(井山 裕太 名人) |
二人の意見に共通しているのは、アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということです。これには、なるほどと思いました。
囲碁は最終的には地の多少を争うゲームです。地は隅が作りやすく、その次に作りやすいのが辺で、中央が一番作りにくい。手を読むのも、特に序盤から中盤にかけては、隅→辺→中央の順に読みにくくなります。中央はいちばん手が広い(=たくさんの選択肢がありうる)からです。中央が読みにくいということから、中央を打つときには "感覚" に頼ることが多くなる。この "感覚" がくせ者です。それは先生から弟子へと(王九段が言うように、弟子は先生に叱り飛ばされながら)受け継がれてきたものでしょう。さらには先人から現代の棋士へと受け継がれてきた。その囲碁の歴史で醸成されてきた "感覚" は、果たしてどの程度まで正しいのか。中央の手を読むより、隅や辺の手を精密に読むことに慣れた人間の "感覚" がどこまで正当化できるのか、ということがあると思うのです。
アルファ碁にとって、隅・辺・中央の違いはありません。盤面全体を一つのパターンとしてとらえて最善手を見つけようとする。辺の打ち方で20手先を読むのも、中央の打ち方で20手先を読むのも変わらない。中央の手が広ければ、読みの探索範囲が増えます。従って読みを省略する手は相対的に増えるでしょうが、読む "深さ" は、隅や辺と変わらないはずです。
アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということは、はからずも今までのプロ棋士たちの囲碁研究で「手薄だった」部分が露呈したということではないでしょうか。アルファ碁はそれを明らかにした。上に引用した王九段も井上名人もそれを感じたのではと思います。
二人の発言から感じるのは、囲碁の世界においてもコンピュータと共存していこうという意志です。確かに今回は教えられた、しかしその教えられたことをベースに、自分自身ももっと強くなるぞ、というような二人の意欲を感じます。コンピュータ技術と人間の知恵の相乗効果で、双方がレベルアップしていくという未来を感じさせる、爽やかなコメントでした。
コンピュータの歴史の転換点
アルファ碁の勝利を前にすると、AIは万能のように考えてしまう人が出てくると思いますが、それは違うでしょう。まず、アルファ碁は「人間の知恵の集積」がベースになっています。アルファ碁が機械学習に使った3000万の局面はあくまで近年のものだと思いますが、そのバックには「囲碁2000年の歴史」があり、アルファ碁はそこからスタートしているわけです。しかも人間なら3000万の局面を記憶する必要はなく、少量の過去の棋譜から類推・推量が可能です。
さらに囲碁は「情報が全部開示されている」ゲームですが、ゲームにはそうでないもの(たとえば麻雀)があります。またゲームを離れてAIを広く適用すること考えると、たとえば医療診断では情報は不完全なことが多いし、中には間違った情報があるかも知れない。医療診断にかかわらず、社会で行われている判断の多くはそうです。情報は不完全であり、しかもルールが変わったり、グレーだったりする。囲碁のルールは変わりませんが・・・・・・。AIを万能のように考えるのは大きな誤りでしょう。
とはいえ、アルファ碁がトッププロとの5番勝負に勝ったという「事件」は、非常に素晴らしいことだし、単にゲームの世界の話に留まらないと感じます。IBMのコンピュータがチェスの世界チャンピオンを負かしたことや、クイズ番組で優勝したことよりも格段に大きな事件でしょう。現代のデジタル・コンピュータのルーツは1946年のENIAC(ペンシルヴァニア大学。真空管式)と言われていますが、そうするとコンピュータには70年の歴史があることになります。そのコンピュータ70年の歴史の転換点がこの対局であり、後世の人から必ずそう言われると確信します。
人工知能(AI)のリスク
ディープマインド社は大きなブレークスルーを成し遂げました。しかし一般に科学技術には負の側面があることが多いわけです。ディープマインド社について非常に印象に残った逸話があります。グーグルに買収されるにあたって、ディープマインド社はグーグルに対し「AI倫理委員会」の設立を要求したという件です。
|
「人類はテクノロジーによって絶滅するだろう」というのは、ずいぶんペシミスティックな発言(ないしは人)ですが、核兵器の前例があるわけですね。AI専門家の重大な警告と受け取った方がいいでしょう。ふと、アーノルド・シュワルツネッガーを一躍スターにした「ターミネーター」を思い出しました。あの映画において、未来は人間とロボットの戦争状態になっているのですが、その発端は「人工知能が人間に核戦争をしかけた」という想定です。
しかし、AIのリスクはそういうことではないと思います。たとえばAI技術を使って新型の核兵器が開発できるかもしれません。現在の核兵器の開発は(条約加盟国は)実験ができず、コンピュータ・シミュレーションで開発されています。AIもコンピュータ技術の一種なのです。また、極めて効果的なサイバー攻撃(テロ)の手段がAI技術で生み出されるかもしれません。もっと一般には、AIを「活用」した犯罪はいくらでも考えられそうな気がします。
他の有用な科学技術と同様、AIも「光」とともに「影」を背負っているということでしょう。ディープマインドのレッグ氏の発言はそれを最も強い形で言ったと解釈できます。逆にいうと AI はそれだけ人間社会へのインパクトが強い技術である。そいういうことかと思いました。
ゲームが導いた革新
ディープマインド社が、自社の「強化学習」の有用性を検証するのに、米・アタリ社のビデオ・ゲームを使ったという話が出てきました。アタリ社は1972年に設立されたビデオ・ゲームの老舗です。設立者はノーラン・ブッシュネルという人ですが、彼は囲碁が大好きで、日本棋院の初段の免状を持っていました。社名の「アタリ」は囲碁用語の「アタリ」(次の手で相手の石が取れる状態)です。
| つまり「アタリ」は日本語(=当たり)です。囲碁は中国が発祥ですが、近代囲碁が発達したのは日本で、そのため英語の囲碁用語も「ハネ」「シチョウ」「ダメヅマリ」など、日本語が多い。そもそも、英語で囲碁を示す Go は「碁」の日本語発音です。 |
ひょっとしたらノーラン・ブッシュネルはゲーム会社を設立しながら、将来に囲碁プログラムが出てきて人間との対局が可能になり、それがアマチュア高段者なみになり、ついにはプロのトップ棋士を破るまでになることを夢見ていたのかもしれません。反対に、そんなことは夢想だにできなかったのかもしれない。しかし、囲碁プログラムがトップ棋士を破る日は、アタリ社が設立されてから 44年後にやってきた。IT技術の驚くべき進歩です。
さらにコンピュータ・ゲームつながりで言うと、アルファ碁を開発したディープマインド社のデミス・ハサビス氏は、ディープマインドを設立する前にゲーム会社を作っているのですね(小林雅一著『AIの衝撃』)。おそらく彼はゲームのプログラムを開発しながら、そのゲームをプレイするプログラムを作りたいと強く思ったのではないでしょうか。
囲碁、アタリ社、デミス・ハサビス、アルファ碁は、すべて「ゲーム」というキーワードで相互につながっています。人間社会を革新するかもしれない重要なAI技術が、ゲームとの深い関わりの中で生まれてきた。その中でも特に囲碁がAI技術者の挑戦意欲をかき立て、そこで実証された革新が社会に応用されようとしているわけです。
ゲームは「暇つぶし」であり「娯楽」ですが、同時に「頭脳のスポーツ」でもあり、また、それを職業とする人が成立するほど人間社会に根を下ろしたものです。しかしゲームはそれ以上のものでしょう。それは人間社会における革新を導く何かでもある。今回のアルファ碁の勝利で強く思ったのは、それが「ゲームに導かれた技術革新」だということでした。
| 補記 : アルファ碁のロジック |
ディープマインド社のアルファ碁が実現しているアルゴリズムの詳細を、次の二つの記事に書きました。合わせて参照ください。
| アルファ碁の着手決定ロジック(1) | |||
| アルファ碁の着手決定ロジック(2) |
(2016.6.24)
No.173 - インフルエンザの流行はGoogleが予測する [技術]
No.166「データの見えざる手(2)」において、『データの見えざる手』という本の著者である矢野和男氏が行った「ホームセンターの業績向上策」の実験を紹介しました。今回はこれと関係のある話を書きます。ホームセンターの業績向上策がどういうものだったか、復習すると以下のようになります。
という経緯でした。この話のポイントは2つあります。
の2点です。①についていうと、従来行われていたサンプリング(サンプル従業員、サンプル顧客、サンプル時間帯)ではないところに意義があります。とにかく「人の行動と体の動き」に関するデータを網羅的に全部集めた。ここがポイントです。これを可能にしたのがセンサー技術とIT技術の発達です。また②に関しては、人間が経験に基づいて仮説(=顧客単価の向上と相関関係にありそうな項目)を設定するのではなく、AI技術を使ってコンピュータが網羅的に設定したのがポイントです(約6000項目のデータの組み合わせ)。
ところで、以上の「ホームセンターの業績向上策」と類似の話が『ビッグデータの正体』(講談社 2013)という本に載っていました。アメリカの事例ですが、それを紹介したいと思います。本の著者は、ビクター・マイヤー=ショーンベルガー(オックスフォード大学教授)とケネス・クキエ(英・エコノミスト誌)の二人です。
インフルエンザの流行予測
2009年、新型インフルエンザである「H1N1ウイルス」が発見されました。鳥インフルエンザ・ウイルスと豚インフルエンザ・ウイルスが部分的に組み合わさり、人間に感染する新型ウイルスが出現したのです。
米国の場合、インフルエンザのような感染症の実態を把握し、対策を指示するのは疾病予防管理センター(CDC)と呼ばれる政府機関です。2009年のインフルエンザの場合もCDCは全米の医療機関に報告を求め、それを集計してインフルエンザの流行状況を公表しました。
しかし、CDCのデータ集計には問題点がありました。一つは医療機関からCDCへの報告のズレであり、情報としては1~2週間前のものが集まることです。そもそも感染患者は具合が悪いと感じてから病院に行くまでに数日かかるのが普通です。またCDCの集計と公表は1週間ごとでした。あれこれの要因で、CDCの公表データはインフルエンザ流行の実態から2週間程度遅れていたのです。新型インフルエンザのように人々に免疫がなく感染力の強い病気の場合、2週間の遅れは、的確な対策を講じる上で "致命的遅れ" になりかねません。
ところが、2009年のH1N1ウイルスがマスコミをにぎわす数週間前、グーグルのチームが有力科学論文誌「ネイチャー」で注目すべき発表をしていました。米国の冬のインフルエンザの流行を州単位まで予測できたという論文です。グーグルが予測のもとにしたのは人々の「検索行動」です。グーグルでは、2009年当時でも1日 30億件の検索が全世界で実行されていて、グーグルは長年にわたってそれを蓄積していたのです。
インターネットでどのようなキーワードを検索をするかは、人々のその時点での関心事そのものと言えるでしょう。従って、感染症の流行と検索語に相関関係があるはずと考えるのは自然な発想です。しかしその発想を実行に移すには、ビッグデータを利用可能な形で蓄積していることと、コンピュータのパワー、そして分析技術が必要なのです。上の引用はそのことを言っています。
「合計4億5000万にも上る膨大な数式モデル」と書かれているところは、冒頭に引用した「ホームセンターの業績向上策」における「6000項目のデータの組み合わせ」と、本質的には同じことでしょう。その中に「宝物」が潜んでいた。
インターネットにおける人々の検索というのは、玉石混交です。自分がインフルエンザにかかったのではと思う人は検索するでしょうが、単なる興味もあるだろうし、ワクチンを製造する製薬会社の株購入を検討している人もいるはずです。とにかく種々雑多であることはだけは確かです。そもそもインフルエンザが流行している時にも "普通の風邪" をひく人だっていっぱいるわけです。従って「咳の薬」や「解熱剤」という検索ワードが増えたからインフルエンザが流行しているとか、そういった単純なことには絶対にならないのです。
「意味」を考えていてはダメなのですね。あくまで膨大なビッグデータをもとに、統計処理で(AI技術でと言ってもよい)インフルエンザの流行と関係のありそうな4億5000万種のデータの組み合わせを自動抽出し、それとCDCの流行データとの相関関係を網羅的に全部チェックする。その結果判明したのが「検索語45個を使ったある数式」だった。
おそらくグーグルの技術者にも、この検索語45語からなぜ流行が推定できるのか、分からないのではないでしょうか。45語の中に「咳の薬」や「解熱剤」が入っていることは間違いないと思いますが、残りは43語もあります。医療関係者や社会衛生の専門家、心理学者を集めて検討したとしても、その43語は分からなかったに違いありません。インフルエンザの流行予測という視点からすると「玉石混交」である検索データは、そのほとんどが「石」だったはずです。しかし検索語45個を使うことで中から「玉」が現れた・・・・・・。
このグーグルの事例は、冒頭の「ホームセンターの業績向上策」と本質的に同じです。つまり、「網羅的に集められたビッグデータの中から、目的とする情報と強い相関関係をもつ "データの組み合わせ" をAI技術で見いだした」という点で "全く同じ" です。社会衛生と店舗の営業業績は性質の異なる問題ですが、ビッグデータとAIに問題を還元できれば同様の手法で解決できることを、この二つの例は示しています。
ビッグデータの分析から分かること。
『ビッグデータの正体』という本には、グーグルが行ったインフルエンザの流行予測以外にも、いろいろと興味ある事例が紹介されています。AI技術を使ったもの、使わないもの、さまざまですが、いずれもビッグデータの解析をビジネスや研究に生かしたものです。そのうちの3点を紹介します。
No.149「我々は直感に裏切られる」で、アルバート = ラズロ・バラバシ教授の『新ネットワーク思考』という本から「6次の隔たり」という仮説を紹介しました。この本を書いたバラバシ教授の研究が『ビッグデータの正体』に出てきます。
「人々の交流のあり方」というような社会科学の分野において、従来の研究手法は「サンプリング(標本)調査」しかなかったわけです。あるコミュニティー(町、組織など)を選び、アンケート用紙を配り、あるいは面接調査をする。もちろん全員の調査はできないことが多いので、標本の抽出が必要であり、どのように抽出するかが非常に重要です。「全体の傾向を表す、少ない標本」の選び方が研究の最重要事項と言ってもいいでしょう。
しかし携帯電話の通話記録をもとにするという方法では、サンプル抽出の必要はありません。国民の約5分の1と書いてあるので、アメリカ人の4000万人とか5000万人とか、そういった数です。全国民というわけではありませんが、このレベルの数となると実質的にアメリカ人全員と言っていい数字です。サンプルの数(N)は "全部" である。「N=全部」とはそのことを言っています。その全員の4ヶ月間の通話記録を網羅的に調査したわけです。その結果、新たな発見があったと言います。
分析の具体的な手順は書いていないのですが、容易に想像できるは次のような手順です。
詳細手順は分かりませんが、ほぼこのような手順だと想像できます。この手順において「通話量が多い・少ない」「通話量が激減」「退出者」などを判定するには、それなりの "しきい値" やロジックが必要です。このあたりをどう決めればよいのか、その決め方には試行錯誤があったと考えられます。
この分析は「匿名化(暗号化)された携帯電話番号と、その携帯電話の時系列の全通話記録」というデータさえあればできます。逆に言うと、かたまり(クラスター)が何なのかは不明なはずです(暗号化されているのだから)。それは地域のサークルかもしれないし、企業のある部門かもしれない。また「退出者」がクラスターからいなくなった理由も不明です。引っ越しかもしれないし、死亡かもしれない。入院かもしれないし、転勤かもしれません。
とにかくこの調査手法では分からないことがいっぱいあるのですが、逆に言うと、それだけ「汎用的」「一般的」な「交友関係を盛り上げる原理」が見つかったことになります。さらに従来のサンプリングとアンケート(面接)調査では「キーマンがいなくなったら、交友関係はどう変化するのか」といった調査は非常に難しいわけです。運がよければそういったサンプルにぶつかるでしょうが・・・・・・。しかし4000~5000万人の通話記録の全数分析をすれば、中にはそういう事例があり、その原因が推定できるわけです。まさに「N=全部」の威力と言えるでしょう。
引用の最後にある「集団や社会の中では、多様性がいかに大切であるかを物語っている」というのは、この結果だけからは言い過ぎだと思いますが、新たな知見が得られたことは確かだと思います。
個人のライフスタイルのデータを抽出し、そこから健康リスクを算出するという、保険会社の例も紹介されていました。
善悪判断は別にして、このようなことも現実味を帯びてきた時代だという認識は必要でしょう。また、個人のライフスタイルまで "筒抜け" になりかねない時代という認識も必要です。
ビッグデータの活用例として有名なアマゾンの「おすすめ」機能(リコメンデーション)も本書に紹介されています。アマゾンはユーザの閲覧履歴・購入履歴を蓄積し、そこからリコメンデーションを行っています。しかし初期のシステムは、
ようなリコメンデーションだった。つまり、
わけです。この状況を大きく変えたのが、ワシントン大学の博士課程で人工知能を研究していたグレッグ・リンデンという人です。彼は地元のアマゾンで働きだしました。彼はリコメンデーションの問題点を解決する方法が分かったのです。
村上春樹の本を購入した人に、村上春樹の新刊の「おすすめ」を表示する。これはよく分かります。そういう購買行動をする人(村上ファン)が多いからです。しかしアマゾンの「おすすめ」では、村上春樹の本を購入した人に、ある特定メーカーのトースターの「おすすめ」がされることがありうるわけです(これは、上の引用にトースターとあったための架空の例です)。「村上春樹の本」と「特定メーカーのトースター」に購買行為の相関関係が強ければ、そういう「おすすめ」になる。アマゾンはなぜそういう相関関係があるのか知らないわけです。いや、知る必要はないのです。もし理由を考えるとしたら「村上春樹の(ある)小説の主人公が、そのトースターを愛用していたのか?」となるでしょう。確かにそうかも知れない。しかしそれも仮説に過ぎません。
理由や因果関係を推定したり顧客をカテゴリーに分類することは必要ないし、むしろ有害なのです。有害というのが言い過ぎなら、労多くして実りが少ないということでしょう。大量のデータに語らせる、つまり大量データに含まれる相関関係に注目すればよいのです。
ビッグデータの本質
以上、紹介したのは5つの事例でした。
の5つですが、これらに共通している事項があります。
まず言えることは、分析のもとになったデータには「無関係データ」がいっぱいあるだろう、ということです。つまり、分析の目的には全く関係のないデータです。それどころか、中には意図的に歪曲されたデータさえあるでしょう。
しかしそうであっても、大量に集めれば分析技術によって本質(目的)に到達できる。質の良い少量のデータではなく、大量のデータ(ないしは全部のデータ)を集め、それを質に転化させる。各事例に共通している点です。
共通している2番目は「因果関係」や「理由」を問題にせず、相関関係だけに着目していることです。私たちはどうしても理由を求めます。事象の裏にある「因果関係」を知りたがります。それは人間の性ともいえる。科学の発達は、因果関係を知りたい、原因を知りたいという欲求が大きな動機でしょう。
しかしその一方で、理由は分からないが「Aという入力をするとBという結果が出た」「Aが多いとBも多い」という相関も大切なのですね。数百年続く職人技術はすべてそうです。先人たちの膨大な試行錯誤の積み重ねから、結果がよいものが選択され、絞り込まれて「技術体系」になっている。今から考えるとそれは「科学的に見ても正しい」となるのですが、それは結果論です。正しい理由があって体系ができたのではありません。これは伝統技術だけでなく、現代のものづくりの現場での品質向上活動や改善活動も同じだと思います。
こういった「質より量」「因果より相関」という流れの中では、専門家のありかたも変化してきます。『ビッグデータの正体』には次のように書かれていました。
「因果」の専門家と「相関」の専門家は違うということでしょう。もうすこし広く考えると、さきほど書いた「ものづくりの現場での品質向上活動や改善活動」も同じと思います。現場で品質向上の中心になっているのは、現場で働いている人たちです。学歴もさまざまで決して専門家ではない人たちの改善提案、アイデアです。一方で生産技術の専門家が必要であり、その一方で現場の知恵の集積がある。それが "ものづくり企業" の強さです。この両方が必要ということかと思いました。
こういった「質より量」「因果関係より相関関係」をさして『ビッグデータの正体』の著者は「価値感の転換」と言っていますが、それはちょっと大袈裟だと思います。人間社会に昔からある "2つのものの見方" であり「帰納か演繹か」「論理か統計か」といったことともつながる事項です。
ただ、現代のデジタル技術、情報技術は、扱えるデータの規模と網羅性が格段にアップしました。これにはデータを集めるセンサーの発達も大きく寄与しています。またそれを分析する統計処理や人工知能関連の技術も進化した。さらにコンピュータのパワーが急激にアップしました。今、日本を含む世界で、ビッグデータを分析して得られた知見をビジネスから農業・漁業にまで生かそうという動きが急速に進んでいます。
「データそのものに語らせる」のは昔も今も重要ですが、昔は「一部のデータ」「選んだデータ」「特徴的なデータ」だった。そこに既に人間の判断が入っていた。そうではなく「すべてのデータに語らせる」ことができるようになった。そこが重要だと思いました。
| ◆ | 実験の目的は、あるホームセンター顧客単価(顧客一人当たりの購買金額)を向上させることである。 | ||
| ◆ | まず、従業員と客にセンサー内蔵のカードを身につけてもらい、店内における行動と体の動きの全データ(以下、ビッグデータ)を詳細に記録した(2週間分)。 | ||
| ◆ | 次に、人工知能(AI)の技術を利用し、顧客単価に影響がありうるデータの組み合わせ、約6000項目を自動抽出した。 | ||
| ◆ | それらの項目の実測データとレジでの購買データを付き合わせ、相関関係をチェックした。 | ||
| ◆ | その結果、「従業員の滞在時間が長いと顧客単価があがる特定の場所=ホットスポット」の存在が明らかになった。 | ||
| ◆ | 従業員がホットスポットに意図的に長く滞在するようにして実測したところ、実際に顧客単価が上昇した。 |
という経緯でした。この話のポイントは2つあります。
| ① | ビッグデータを網羅的に全部収集した。 | ||
| ② | 目的(顧客単価の向上)と相関関係にありそうな項目を、AI技術を使って自動抽出した。 |
の2点です。①についていうと、従来行われていたサンプリング(サンプル従業員、サンプル顧客、サンプル時間帯)ではないところに意義があります。とにかく「人の行動と体の動き」に関するデータを網羅的に全部集めた。ここがポイントです。これを可能にしたのがセンサー技術とIT技術の発達です。また②に関しては、人間が経験に基づいて仮説(=顧客単価の向上と相関関係にありそうな項目)を設定するのではなく、AI技術を使ってコンピュータが網羅的に設定したのがポイントです(約6000項目のデータの組み合わせ)。
ところで、以上の「ホームセンターの業績向上策」と類似の話が『ビッグデータの正体』(講談社 2013)という本に載っていました。アメリカの事例ですが、それを紹介したいと思います。本の著者は、ビクター・マイヤー=ショーンベルガー(オックスフォード大学教授)とケネス・クキエ(英・エコノミスト誌)の二人です。
インフルエンザの流行予測

| |||
|
ビクター・マイヤー=
ショーンベルガー ケネス・クキエ 「ビッグデータの正体」 (講談社 2013) | |||
米国の場合、インフルエンザのような感染症の実態を把握し、対策を指示するのは疾病予防管理センター(CDC)と呼ばれる政府機関です。2009年のインフルエンザの場合もCDCは全米の医療機関に報告を求め、それを集計してインフルエンザの流行状況を公表しました。
しかし、CDCのデータ集計には問題点がありました。一つは医療機関からCDCへの報告のズレであり、情報としては1~2週間前のものが集まることです。そもそも感染患者は具合が悪いと感じてから病院に行くまでに数日かかるのが普通です。またCDCの集計と公表は1週間ごとでした。あれこれの要因で、CDCの公表データはインフルエンザ流行の実態から2週間程度遅れていたのです。新型インフルエンザのように人々に免疫がなく感染力の強い病気の場合、2週間の遅れは、的確な対策を講じる上で "致命的遅れ" になりかねません。
ところが、2009年のH1N1ウイルスがマスコミをにぎわす数週間前、グーグルのチームが有力科学論文誌「ネイチャー」で注目すべき発表をしていました。米国の冬のインフルエンザの流行を州単位まで予測できたという論文です。グーグルが予測のもとにしたのは人々の「検索行動」です。グーグルでは、2009年当時でも1日 30億件の検索が全世界で実行されていて、グーグルは長年にわたってそれを蓄積していたのです。
|
インターネットでどのようなキーワードを検索をするかは、人々のその時点での関心事そのものと言えるでしょう。従って、感染症の流行と検索語に相関関係があるはずと考えるのは自然な発想です。しかしその発想を実行に移すには、ビッグデータを利用可能な形で蓄積していることと、コンピュータのパワー、そして分析技術が必要なのです。上の引用はそのことを言っています。
|
「合計4億5000万にも上る膨大な数式モデル」と書かれているところは、冒頭に引用した「ホームセンターの業績向上策」における「6000項目のデータの組み合わせ」と、本質的には同じことでしょう。その中に「宝物」が潜んでいた。
インターネットにおける人々の検索というのは、玉石混交です。自分がインフルエンザにかかったのではと思う人は検索するでしょうが、単なる興味もあるだろうし、ワクチンを製造する製薬会社の株購入を検討している人もいるはずです。とにかく種々雑多であることはだけは確かです。そもそもインフルエンザが流行している時にも "普通の風邪" をひく人だっていっぱいるわけです。従って「咳の薬」や「解熱剤」という検索ワードが増えたからインフルエンザが流行しているとか、そういった単純なことには絶対にならないのです。
「意味」を考えていてはダメなのですね。あくまで膨大なビッグデータをもとに、統計処理で(AI技術でと言ってもよい)インフルエンザの流行と関係のありそうな4億5000万種のデータの組み合わせを自動抽出し、それとCDCの流行データとの相関関係を網羅的に全部チェックする。その結果判明したのが「検索語45個を使ったある数式」だった。
おそらくグーグルの技術者にも、この検索語45語からなぜ流行が推定できるのか、分からないのではないでしょうか。45語の中に「咳の薬」や「解熱剤」が入っていることは間違いないと思いますが、残りは43語もあります。医療関係者や社会衛生の専門家、心理学者を集めて検討したとしても、その43語は分からなかったに違いありません。インフルエンザの流行予測という視点からすると「玉石混交」である検索データは、そのほとんどが「石」だったはずです。しかし検索語45個を使うことで中から「玉」が現れた・・・・・・。
|
このグーグルの事例は、冒頭の「ホームセンターの業績向上策」と本質的に同じです。つまり、「網羅的に集められたビッグデータの中から、目的とする情報と強い相関関係をもつ "データの組み合わせ" をAI技術で見いだした」という点で "全く同じ" です。社会衛生と店舗の営業業績は性質の異なる問題ですが、ビッグデータとAIに問題を還元できれば同様の手法で解決できることを、この二つの例は示しています。
ビッグデータの分析から分かること。
『ビッグデータの正体』という本には、グーグルが行ったインフルエンザの流行予測以外にも、いろいろと興味ある事例が紹介されています。AI技術を使ったもの、使わないもの、さまざまですが、いずれもビッグデータの解析をビジネスや研究に生かしたものです。そのうちの3点を紹介します。
No.149「我々は直感に裏切られる」で、アルバート = ラズロ・バラバシ教授の『新ネットワーク思考』という本から「6次の隔たり」という仮説を紹介しました。この本を書いたバラバシ教授の研究が『ビッグデータの正体』に出てきます。
|
「人々の交流のあり方」というような社会科学の分野において、従来の研究手法は「サンプリング(標本)調査」しかなかったわけです。あるコミュニティー(町、組織など)を選び、アンケート用紙を配り、あるいは面接調査をする。もちろん全員の調査はできないことが多いので、標本の抽出が必要であり、どのように抽出するかが非常に重要です。「全体の傾向を表す、少ない標本」の選び方が研究の最重要事項と言ってもいいでしょう。
しかし携帯電話の通話記録をもとにするという方法では、サンプル抽出の必要はありません。国民の約5分の1と書いてあるので、アメリカ人の4000万人とか5000万人とか、そういった数です。全国民というわけではありませんが、このレベルの数となると実質的にアメリカ人全員と言っていい数字です。サンプルの数(N)は "全部" である。「N=全部」とはそのことを言っています。その全員の4ヶ月間の通話記録を網羅的に調査したわけです。その結果、新たな発見があったと言います。
|
分析の具体的な手順は書いていないのですが、容易に想像できるは次のような手順です。
| ◆ | 通話頻度が高い人の間で構成されるネットワークを分析し、そのネットワークを人間集団の「かたまり=クラスター」に分解する。つまり、クラスターの内部では頻繁に会話が行われ、クラスター内とクラスター外の会話は少ないようにクラスターを選び出す。 | ||
| ◆ | クラスターの4ヶ月間の時間的な通話量を追いかける。この中から、ある時点を境に全体の通話量が激減したクラスターを見つけだす(全体通話量が激減したものは、交友関係が減少したものとみなす)。 | ||
| ◆ | 一方、クラスターからいなくなった人(退出者)がいるかどうか調べる。ある時点からクラスターでの通話がなくなった人(激減した人)は退出者と見なせる。 | ||
| ◆ | 退出者の存在と、クラスターの全体通話量の激減の相関関係を調べる。相関関係があるのなら、退出者のクラスターでの位置づけを調べる。 | ||
| ◆ | この結果、クラスター外部との通話が多い人が退出者となった場合に、クラスターの全体通話量が激減することが分かった。 |
詳細手順は分かりませんが、ほぼこのような手順だと想像できます。この手順において「通話量が多い・少ない」「通話量が激減」「退出者」などを判定するには、それなりの "しきい値" やロジックが必要です。このあたりをどう決めればよいのか、その決め方には試行錯誤があったと考えられます。
この分析は「匿名化(暗号化)された携帯電話番号と、その携帯電話の時系列の全通話記録」というデータさえあればできます。逆に言うと、かたまり(クラスター)が何なのかは不明なはずです(暗号化されているのだから)。それは地域のサークルかもしれないし、企業のある部門かもしれない。また「退出者」がクラスターからいなくなった理由も不明です。引っ越しかもしれないし、死亡かもしれない。入院かもしれないし、転勤かもしれません。
とにかくこの調査手法では分からないことがいっぱいあるのですが、逆に言うと、それだけ「汎用的」「一般的」な「交友関係を盛り上げる原理」が見つかったことになります。さらに従来のサンプリングとアンケート(面接)調査では「キーマンがいなくなったら、交友関係はどう変化するのか」といった調査は非常に難しいわけです。運がよければそういったサンプルにぶつかるでしょうが・・・・・・。しかし4000~5000万人の通話記録の全数分析をすれば、中にはそういう事例があり、その原因が推定できるわけです。まさに「N=全部」の威力と言えるでしょう。
引用の最後にある「集団や社会の中では、多様性がいかに大切であるかを物語っている」というのは、この結果だけからは言い過ぎだと思いますが、新たな知見が得られたことは確かだと思います。
個人のライフスタイルのデータを抽出し、そこから健康リスクを算出するという、保険会社の例も紹介されていました。
|
善悪判断は別にして、このようなことも現実味を帯びてきた時代だという認識は必要でしょう。また、個人のライフスタイルまで "筒抜け" になりかねない時代という認識も必要です。
ビッグデータの活用例として有名なアマゾンの「おすすめ」機能(リコメンデーション)も本書に紹介されています。アマゾンはユーザの閲覧履歴・購入履歴を蓄積し、そこからリコメンデーションを行っています。しかし初期のシステムは、
| ポーランドの書籍を1冊買っただけで、東欧関係の書籍案内が怒濤のごとく送られてきたり、赤ちゃん関係の書籍を買えば、似たような本の紹介であふれかえる(本書) |
ようなリコメンデーションだった。つまり、
| 前回の購入書と大差ない書籍を延々と紹介し続けていた。客にしてみれば、はた迷惑な店員につきまとわれながら買い物をしているようなものだった(本書) |
わけです。この状況を大きく変えたのが、ワシントン大学の博士課程で人工知能を研究していたグレッグ・リンデンという人です。彼は地元のアマゾンで働きだしました。彼はリコメンデーションの問題点を解決する方法が分かったのです。
|
村上春樹の本を購入した人に、村上春樹の新刊の「おすすめ」を表示する。これはよく分かります。そういう購買行動をする人(村上ファン)が多いからです。しかしアマゾンの「おすすめ」では、村上春樹の本を購入した人に、ある特定メーカーのトースターの「おすすめ」がされることがありうるわけです(これは、上の引用にトースターとあったための架空の例です)。「村上春樹の本」と「特定メーカーのトースター」に購買行為の相関関係が強ければ、そういう「おすすめ」になる。アマゾンはなぜそういう相関関係があるのか知らないわけです。いや、知る必要はないのです。もし理由を考えるとしたら「村上春樹の(ある)小説の主人公が、そのトースターを愛用していたのか?」となるでしょう。確かにそうかも知れない。しかしそれも仮説に過ぎません。
理由や因果関係を推定したり顧客をカテゴリーに分類することは必要ないし、むしろ有害なのです。有害というのが言い過ぎなら、労多くして実りが少ないということでしょう。大量のデータに語らせる、つまり大量データに含まれる相関関係に注目すればよいのです。
ビッグデータの本質
以上、紹介したのは5つの事例でした。
| ◆ | ホームセンターの業績向上策 | ||
| ◆ | インフルエンザの流行予測 | ||
| ◆ | 人々の交流関係を盛り上げるのは誰か | ||
| ◆ | ライフスタイルのデータから健康リスクを推定する | ||
| ◆ | アマゾンのリコメンデーション(おすすめ) |
の5つですが、これらに共通している事項があります。
| 質より量 |
まず言えることは、分析のもとになったデータには「無関係データ」がいっぱいあるだろう、ということです。つまり、分析の目的には全く関係のないデータです。それどころか、中には意図的に歪曲されたデータさえあるでしょう。
しかしそうであっても、大量に集めれば分析技術によって本質(目的)に到達できる。質の良い少量のデータではなく、大量のデータ(ないしは全部のデータ)を集め、それを質に転化させる。各事例に共通している点です。
| 因果関係より相関関係 |
共通している2番目は「因果関係」や「理由」を問題にせず、相関関係だけに着目していることです。私たちはどうしても理由を求めます。事象の裏にある「因果関係」を知りたがります。それは人間の性ともいえる。科学の発達は、因果関係を知りたい、原因を知りたいという欲求が大きな動機でしょう。
しかしその一方で、理由は分からないが「Aという入力をするとBという結果が出た」「Aが多いとBも多い」という相関も大切なのですね。数百年続く職人技術はすべてそうです。先人たちの膨大な試行錯誤の積み重ねから、結果がよいものが選択され、絞り込まれて「技術体系」になっている。今から考えるとそれは「科学的に見ても正しい」となるのですが、それは結果論です。正しい理由があって体系ができたのではありません。これは伝統技術だけでなく、現代のものづくりの現場での品質向上活動や改善活動も同じだと思います。
こういった「質より量」「因果より相関」という流れの中では、専門家のありかたも変化してきます。『ビッグデータの正体』には次のように書かれていました。
|
「因果」の専門家と「相関」の専門家は違うということでしょう。もうすこし広く考えると、さきほど書いた「ものづくりの現場での品質向上活動や改善活動」も同じと思います。現場で品質向上の中心になっているのは、現場で働いている人たちです。学歴もさまざまで決して専門家ではない人たちの改善提案、アイデアです。一方で生産技術の専門家が必要であり、その一方で現場の知恵の集積がある。それが "ものづくり企業" の強さです。この両方が必要ということかと思いました。
こういった「質より量」「因果関係より相関関係」をさして『ビッグデータの正体』の著者は「価値感の転換」と言っていますが、それはちょっと大袈裟だと思います。人間社会に昔からある "2つのものの見方" であり「帰納か演繹か」「論理か統計か」といったことともつながる事項です。
ただ、現代のデジタル技術、情報技術は、扱えるデータの規模と網羅性が格段にアップしました。これにはデータを集めるセンサーの発達も大きく寄与しています。またそれを分析する統計処理や人工知能関連の技術も進化した。さらにコンピュータのパワーが急激にアップしました。今、日本を含む世界で、ビッグデータを分析して得られた知見をビジネスから農業・漁業にまで生かそうという動きが急速に進んでいます。
「データそのものに語らせる」のは昔も今も重要ですが、昔は「一部のデータ」「選んだデータ」「特徴的なデータ」だった。そこに既に人間の判断が入っていた。そうではなく「すべてのデータに語らせる」ことができるようになった。そこが重要だと思いました。
No.172 - 鴻海を見下す人たち [技術]
今回は、2016年4月2日に正式決定された「鴻海精密工業のシャープ買収」について書きたいと思います。鴻海精密工業(Hon Hai Precision Industry)に関連しては、前に4つの記事を書きました。
の4つです。これらの記事で "フォックスコン" と書いたは、鴻海精密工業の中国子会社、富士康科技集団の通称です。記事の中心はアップル製品の中国大陸における組立てのことだったので "フォックスコン" としました。しかし最近では「鴻海精密工業」の名前が広がってきたし、特にシャープ買収の報道では "鴻海" の名前が広く報道されました。この記事も以下、鴻海としたいと思います。
この買収劇については、さまざな報道がなされました。特に、この買収をどう見るかについて、企業M&Aの専門家から一般市民の街頭インタビューまで、各種の意見が報道されました。その中で私が一番印象的だったのは、以下に紹介する朝日新聞のコラムです。その内容について感想を書きたいと思います。
鴻海隆隆 シャープ寂寂
2016年3月20日(日)の朝日新聞のコラム、"日曜に想う" に「鴻海隆隆 シャープ寂寂」と題したコラムが掲載されました。著者は、朝日新聞の特別編集委員の山中 季広氏です。大変興味ある内容だったので、以下に引用してみたいと想います。まずコラムの出だしは、筆者が鴻海の本社を訪問した時の話です。
このコラムが印象的なのは、「鴻海のシャープ買収」を台湾サイドでどう受け止めているかを書いていることです。鴻海の本社前には台湾の各種メディアの「張り番」が陣取り、人の出入りを全部チェックしているわけです。台湾の人たちの関心の高さがうかがえます。
なるほど・・・・・・。台湾の人たちの心情(の一端)が分かるリポートです。あくまで投資会社を経営する一個人の感想ですが、「かつて日本に植民地化され」というところまで遡るわけですね。日本の台湾植民地政策はインフラや学校の整備など台湾の "役にたった" ことも多く、今の台湾の人たちも日本に好意的な人が多いと聞きます。それでも「植民地にされた」のは事実なのです。さらにコラムでは鴻海の郭会長の人物像についても書かれています。
これは従来から報道されている通りです。とにかく郭台銘会長は大変な "やり手" であり、カリスマ経営者であることは間違いないようです。ここまでのコラムは、従来の報道(郭会長の人物像)に加えて、台湾の人たちがこの買収をどう見ているかという情報があり、有用な記事だと思いました。
ところが、その次の文章を読んで「あれっー」と思ってしまいました。コラムが変な方向に行くのです。次の引用です。
鴻海を "見下す" 態度
「鴻海は技術力で伸びてきた会社ではない」と書いてあるのですが、朝日新聞の編集委員ともあろう人が、こんないいかげんなことを言っていいのですかね。
鴻海は、No.71「アップルとフォックスコン」で紹介したように「技術力で伸びてきた」会社だと思います。それはまず「金型製造技術」です。コラムに「テレビのチャンネルのつまみ製造」とあるように、鴻海は電機製品のプラスチック(樹脂)部品の製造で始まった会社です。"つまみ" もそうだし、No.71に書いた各種のコネクタがそうです。これらの部品を製造するためには金型が必要ですが、鴻海はその金型を内製化しているのですね。これは日本の企業では珍しいことです。日本なら「金型専門会社」に製造委託するのが普通だからです。
No.71は中川・東京大学名誉教授の雑誌記事からの紹介でしたが、鴻海は社内に「金型学校」をもち、グループ全体の金型技術者は3万人いるそうです。もちろんエキスパートから経験の浅い技術者まで "ピンキリ" なのでしょうが、3万人というのはありえないような数です。日本全国の金型製造業の従業員総数は10万人程度と推定されているのだから。
金型を製造するためには、金属の塊を工作機械で切削する必要があります。この切削技術が生きたのが、鴻海が製造しているアップル製品の筐体(= 外装ボディ)です。この外装部品をアップルは "Unibody" と呼んでいますが、この "Unibody" は金属塊から一つ一つ削り出すことで作られているのですね。これに使う工作機械はほとんどがファナックなどの日本製だと言われています。しかし切削に使う超硬工具(ダイヤモンド工具)は鴻海が自社で製造しています。
No.71に紹介したのですが、アップルは "Unibody" の美しさ、デザインの良さをホームページで誇らしげにうたっています。もちろんデザインしたのはアップルですが、そのデザインを具現化し、製造して精密に仕上げたのは鴻海です。アップル社が自社製品の一つの部品だけを取り上げて誇っているのは、この "Unibody" 以外には見たことがありません。
アップル製品は大量生産されます。それは多い時には日に50万台とか、そういうレベルの数です。こんな大量生産品の部品を一個一個削りだしで作るというのは、完全に製造業の常識を越えています。その常識を越えた破天荒な製造方法をちゃんとやっている鴻海の技術力は大したものだと思わずにはいられません。会社の正式名称は鴻海精密工業です。「精密」の2文字を入れた創業者の意気込みを感じます。
さらに上の引用での違和感は、アップルとの契約のところの、(スマホなどを安く大量に)「代行製造した」という表現です。「代行製造」とは聞きなれない言葉です。ここはなぜ「製造」ではまずいのでしょうか。鴻海はアップルのスマホなどの最終組立てを行っていますが、代行とは「代わりにやる」という意味であり、アップルがやるべきことを鴻海が代わりにやっているという意味になります。
スマホなどの最終組立ては機械化できず、人手に頼るしかありません。従って鴻海は中国大陸に工場を作り、従業員を集めて人海戦術で行っています。さっき書いたようにアップル製品の製造は日に50万台といった大量製造です。これだけの数の組立てを品質よく、市場不具合を起こさずにやることは必ずしも容易なことではないと思います。確かに金型製造というような意味での精密技術は必要ないかもしれない。しかし従業員の教育から始まって、これだけの大量生産をうまく "廻す" のは、それなりのノウハウの蓄積が必要なはずです。朝日新聞のコラムは「代行」という言葉で、なんとなく価値が低いというニュアンスを匂わせていますが、そんなことはありません。No.58「アップルはファブレス企業か」で書いたように、アップルは自社では絶対にできないことを鴻海に委託しているのだと思います。
この朝日新聞の編集委員氏は「鴻海は技術力がない代行製造会社」と言いたいようですが、何となく鴻海を「見下している」と感じます。しかし、鴻海は「見下す」ような会社ではない。
鴻海ごときに・・・・・・
さらにこのコラムには、違和感を覚える記述が続きます。
あたりまえですが「町工場風の簡素な4階建ての本社」は別に悪いことではありません。鴻海はシャープ買収に4000億円を出す会社です。最新のデザインと建築技術を盛り込んだ本社を建てることぐらい、わけないと思います。なぜ「町工場風」のままなのかは分かりませんが、厳しくコストを削減するという宣言かもしれないし、創業時代を忘れるなという意味なのかもしれない。それに、大阪市のシャープ本社だってそんなに豪華なものではありません。編集委員氏がシャープ本社を取材したのかどうか知りませんが・・・・・・。
朝日新聞の編集委員氏が鴻海について書いた言葉を並べてみると、彼の言いたいことが見えてきます。
つまり、鴻海精密工業は「技術力はないけれど、猛烈に働くカリスマ経営者に率いられ、馬力で伸びた会社」と言いたいのでしょう。そして、
と思っているのでしょう。そうはっきりは書いていないが、言外にそう言っている。これでは鴻海傘下になるシャープの社員が可哀想です。
思い起こすと、日本の名門大企業が海外企業の傘下に入ったのはシャープが初めてではありません。そうです。1999年にルノーの傘下になった日産自動車です。朝日新聞の編集委員氏はそのとき「ルノーのような会社に日産が買収されるのは寂しい」と感じたのでしょうか。ルノーのパリ本社は "町工場風" ではなくて立派だから寂しくはなかったでしょうか。それとも、フランスの名門企業に買収されるのはいいが、台湾企業では寂しいのでしょうか。
鴻海のシャープ買収についての各種報道に接して、何となく暗に台湾企業を見下しているような発言を何回か聞いたことがあります。その典型が、この朝日新聞の編集委員氏ということでしょう。
付け加えますと、現在、シャープの社員で不安を感じていない人はいないと思います。しかし第三者の視点で冷静に見ると、鴻海傘下になることで液晶およびシャープの技術の販路が広がり、今後のシャープがグローバルに活躍するチャンスが訪れたことは明白だと思います。そう感じているシャープ社員の方も少なからずいるのではないでしょうか。
海外企業に「学ぶ」姿勢
朝日新聞の編集委員氏のような見方をしている限り、日本のものづくり企業は危うくなると思います。もちろん彼は新聞社の人間であり、ものづくりとは何の関係もありません。しかし新聞社の編集委員といえば、日本のオピニオンリーダー層の人間のはずです。その人が鴻海精密工業を "見下す" ようなコラムを書いて公表すること自体、大いに問題だと思います。こんな「オピニオン」で「リード」されては、日本の製造業にとって大迷惑というものです。
鴻海精密工業のシャープ買収をひとつのきっかけとして、むしろ "鴻海に学ぶ" という態度が必要だと思います。ものづくりの技術やビジネスモデル、市場の中心はどんどん変化していきます。鴻海精密工業がこれだけの大会社になった理由を研究する意義は十分あると思います。もちろんマネをする必要はないし、また "カリスマ経営者" をマネることなど出来ないのですが、日本企業が参考にすべきものがあるかもしれない。そういった謙虚な態度が必要でしょう。傲慢な態度を続けると転落する。買収のきっかけとなったシャープの液晶ビジネスの経緯は、まさにそいういうことなのだから。
| アップルはファブレス企業か | |||
| アップルとフォックスコン | |||
| アップル製品の原価 | |||
| アップルとサプライヤー |
の4つです。これらの記事で "フォックスコン" と書いたは、鴻海精密工業の中国子会社、富士康科技集団の通称です。記事の中心はアップル製品の中国大陸における組立てのことだったので "フォックスコン" としました。しかし最近では「鴻海精密工業」の名前が広がってきたし、特にシャープ買収の報道では "鴻海" の名前が広く報道されました。この記事も以下、鴻海としたいと思います。
この買収劇については、さまざな報道がなされました。特に、この買収をどう見るかについて、企業M&Aの専門家から一般市民の街頭インタビューまで、各種の意見が報道されました。その中で私が一番印象的だったのは、以下に紹介する朝日新聞のコラムです。その内容について感想を書きたいと思います。
鴻海隆隆 シャープ寂寂
2016年3月20日(日)の朝日新聞のコラム、"日曜に想う" に「鴻海隆隆 シャープ寂寂」と題したコラムが掲載されました。著者は、朝日新聞の特別編集委員の山中 季広氏です。大変興味ある内容だったので、以下に引用してみたいと想います。まずコラムの出だしは、筆者が鴻海の本社を訪問した時の話です。
|
このコラムが印象的なのは、「鴻海のシャープ買収」を台湾サイドでどう受け止めているかを書いていることです。鴻海の本社前には台湾の各種メディアの「張り番」が陣取り、人の出入りを全部チェックしているわけです。台湾の人たちの関心の高さがうかがえます。
|
なるほど・・・・・・。台湾の人たちの心情(の一端)が分かるリポートです。あくまで投資会社を経営する一個人の感想ですが、「かつて日本に植民地化され」というところまで遡るわけですね。日本の台湾植民地政策はインフラや学校の整備など台湾の "役にたった" ことも多く、今の台湾の人たちも日本に好意的な人が多いと聞きます。それでも「植民地にされた」のは事実なのです。さらにコラムでは鴻海の郭会長の人物像についても書かれています。
|
これは従来から報道されている通りです。とにかく郭台銘会長は大変な "やり手" であり、カリスマ経営者であることは間違いないようです。ここまでのコラムは、従来の報道(郭会長の人物像)に加えて、台湾の人たちがこの買収をどう見ているかという情報があり、有用な記事だと思いました。
.jpg)
| ||
|
鴻海精密工業・本社ビル(台北)
(www.asahi.com)
| ||
ところが、その次の文章を読んで「あれっー」と思ってしまいました。コラムが変な方向に行くのです。次の引用です。
鴻海を "見下す" 態度
|
「鴻海は技術力で伸びてきた会社ではない」と書いてあるのですが、朝日新聞の編集委員ともあろう人が、こんないいかげんなことを言っていいのですかね。
鴻海は、No.71「アップルとフォックスコン」で紹介したように「技術力で伸びてきた」会社だと思います。それはまず「金型製造技術」です。コラムに「テレビのチャンネルのつまみ製造」とあるように、鴻海は電機製品のプラスチック(樹脂)部品の製造で始まった会社です。"つまみ" もそうだし、No.71に書いた各種のコネクタがそうです。これらの部品を製造するためには金型が必要ですが、鴻海はその金型を内製化しているのですね。これは日本の企業では珍しいことです。日本なら「金型専門会社」に製造委託するのが普通だからです。
No.71は中川・東京大学名誉教授の雑誌記事からの紹介でしたが、鴻海は社内に「金型学校」をもち、グループ全体の金型技術者は3万人いるそうです。もちろんエキスパートから経験の浅い技術者まで "ピンキリ" なのでしょうが、3万人というのはありえないような数です。日本全国の金型製造業の従業員総数は10万人程度と推定されているのだから。
| ここでちょっと疑うのですが、ひょっとしたら朝日新聞の編集委員氏は「金型」のような昔からあるアナログ的技術は「技術」の中に入らないと見ているのかもしれません。デジタル技術や、いわゆるハイテクしか目に入っていないのかもしれない。だとすると、ものづくりのことが何も分かっていないということになります。 |
金型を製造するためには、金属の塊を工作機械で切削する必要があります。この切削技術が生きたのが、鴻海が製造しているアップル製品の筐体(= 外装ボディ)です。この外装部品をアップルは "Unibody" と呼んでいますが、この "Unibody" は金属塊から一つ一つ削り出すことで作られているのですね。これに使う工作機械はほとんどがファナックなどの日本製だと言われています。しかし切削に使う超硬工具(ダイヤモンド工具)は鴻海が自社で製造しています。
No.71に紹介したのですが、アップルは "Unibody" の美しさ、デザインの良さをホームページで誇らしげにうたっています。もちろんデザインしたのはアップルですが、そのデザインを具現化し、製造して精密に仕上げたのは鴻海です。アップル社が自社製品の一つの部品だけを取り上げて誇っているのは、この "Unibody" 以外には見たことがありません。
アップル製品は大量生産されます。それは多い時には日に50万台とか、そういうレベルの数です。こんな大量生産品の部品を一個一個削りだしで作るというのは、完全に製造業の常識を越えています。その常識を越えた破天荒な製造方法をちゃんとやっている鴻海の技術力は大したものだと思わずにはいられません。会社の正式名称は鴻海精密工業です。「精密」の2文字を入れた創業者の意気込みを感じます。
さらに上の引用での違和感は、アップルとの契約のところの、(スマホなどを安く大量に)「代行製造した」という表現です。「代行製造」とは聞きなれない言葉です。ここはなぜ「製造」ではまずいのでしょうか。鴻海はアップルのスマホなどの最終組立てを行っていますが、代行とは「代わりにやる」という意味であり、アップルがやるべきことを鴻海が代わりにやっているという意味になります。
スマホなどの最終組立ては機械化できず、人手に頼るしかありません。従って鴻海は中国大陸に工場を作り、従業員を集めて人海戦術で行っています。さっき書いたようにアップル製品の製造は日に50万台といった大量製造です。これだけの数の組立てを品質よく、市場不具合を起こさずにやることは必ずしも容易なことではないと思います。確かに金型製造というような意味での精密技術は必要ないかもしれない。しかし従業員の教育から始まって、これだけの大量生産をうまく "廻す" のは、それなりのノウハウの蓄積が必要なはずです。朝日新聞のコラムは「代行」という言葉で、なんとなく価値が低いというニュアンスを匂わせていますが、そんなことはありません。No.58「アップルはファブレス企業か」で書いたように、アップルは自社では絶対にできないことを鴻海に委託しているのだと思います。
この朝日新聞の編集委員氏は「鴻海は技術力がない代行製造会社」と言いたいようですが、何となく鴻海を「見下している」と感じます。しかし、鴻海は「見下す」ような会社ではない。
鴻海ごときに・・・・・・
さらにこのコラムには、違和感を覚える記述が続きます。
|
あたりまえですが「町工場風の簡素な4階建ての本社」は別に悪いことではありません。鴻海はシャープ買収に4000億円を出す会社です。最新のデザインと建築技術を盛り込んだ本社を建てることぐらい、わけないと思います。なぜ「町工場風」のままなのかは分かりませんが、厳しくコストを削減するという宣言かもしれないし、創業時代を忘れるなという意味なのかもしれない。それに、大阪市のシャープ本社だってそんなに豪華なものではありません。編集委員氏がシャープ本社を取材したのかどうか知りませんが・・・・・・。
朝日新聞の編集委員氏が鴻海について書いた言葉を並べてみると、彼の言いたいことが見えてきます。
| ・ | テレビのチャンネルのつまみ製造 | ||
| ・ | 夜の24時から幹部会議を開く | ||
| ・ | 技術力で伸びてきた会社ではない | ||
| ・ | 粘りに粘った(アップルとの交渉) | ||
| ・ | 安く大量に代行製造した | ||
| ・ | 一見どこかの町工場風 |
つまり、鴻海精密工業は「技術力はないけれど、猛烈に働くカリスマ経営者に率いられ、馬力で伸びた会社」と言いたいのでしょう。そして、
| このような鴻海ごときに(しかも台湾企業ごときに)シャープが買収されるのは寂しい |
と思っているのでしょう。そうはっきりは書いていないが、言外にそう言っている。これでは鴻海傘下になるシャープの社員が可哀想です。
思い起こすと、日本の名門大企業が海外企業の傘下に入ったのはシャープが初めてではありません。そうです。1999年にルノーの傘下になった日産自動車です。朝日新聞の編集委員氏はそのとき「ルノーのような会社に日産が買収されるのは寂しい」と感じたのでしょうか。ルノーのパリ本社は "町工場風" ではなくて立派だから寂しくはなかったでしょうか。それとも、フランスの名門企業に買収されるのはいいが、台湾企業では寂しいのでしょうか。
鴻海のシャープ買収についての各種報道に接して、何となく暗に台湾企業を見下しているような発言を何回か聞いたことがあります。その典型が、この朝日新聞の編集委員氏ということでしょう。
付け加えますと、現在、シャープの社員で不安を感じていない人はいないと思います。しかし第三者の視点で冷静に見ると、鴻海傘下になることで液晶およびシャープの技術の販路が広がり、今後のシャープがグローバルに活躍するチャンスが訪れたことは明白だと思います。そう感じているシャープ社員の方も少なからずいるのではないでしょうか。
3-3f857.jpg)
| ||
|
シャープ・本社ビル(大阪市)
(www.asahi.com)
| ||
海外企業に「学ぶ」姿勢
朝日新聞の編集委員氏のような見方をしている限り、日本のものづくり企業は危うくなると思います。もちろん彼は新聞社の人間であり、ものづくりとは何の関係もありません。しかし新聞社の編集委員といえば、日本のオピニオンリーダー層の人間のはずです。その人が鴻海精密工業を "見下す" ようなコラムを書いて公表すること自体、大いに問題だと思います。こんな「オピニオン」で「リード」されては、日本の製造業にとって大迷惑というものです。
鴻海精密工業のシャープ買収をひとつのきっかけとして、むしろ "鴻海に学ぶ" という態度が必要だと思います。ものづくりの技術やビジネスモデル、市場の中心はどんどん変化していきます。鴻海精密工業がこれだけの大会社になった理由を研究する意義は十分あると思います。もちろんマネをする必要はないし、また "カリスマ経営者" をマネることなど出来ないのですが、日本企業が参考にすべきものがあるかもしれない。そういった謙虚な態度が必要でしょう。傲慢な態度を続けると転落する。買収のきっかけとなったシャープの液晶ビジネスの経緯は、まさにそいういうことなのだから。



