No.174 - ディープマインド [技術]
最近の記事で、AI(Artificial Intelligence。人工知能)について3回書きました。
の3つです。No.159 の "AIBO" は AI技術を利用したソニーの犬型ロボットで、1999年に発売が開始され、2006年に販売終了しました。さすがソニーと思える先進的な製品です。また、No.166「データの見えざる手(2)」で紹介したのは「ホームセンターの業績向上策」をAI技術を利用して見い出したという事例でした。さらにNo.173は、グーグルが人々の検索ワードを蓄積したビッグデータをもとに、AI技術を応用してインフルエンザの流行予測を行った例でした。
そのAI関連の継続で、今回はグーグルが2014年に買収した英国の会社、ディープマインド社について書きたいと思います。この会社がつくった「アルファ碁」というコンピュータ・プログラムは、囲碁の世界トップクラスの棋士と対戦して4勝1敗の成績をあげ、世界中で大変な話題になりました。
「アルファ碁」とイ・セドル九段の5番勝負
2016年3月、韓国のイ・セドル(李世乭)九段とディープマインド社の「アルファ碁」の5番勝負がソウル市内で行われ、「アルファ碁」の4勝1敗となりました。イ・セドル九段は世界のトップクラスの棋士であり(世界No.1とも、No.2とも言われる)、囲碁の世界では大変な強豪です。コンピュータはその棋士に "勝った" ことになります。
もっとも、これが真に "対等な勝負" なのかは疑問があります。それは、「アルファ碁」は世界のプロ棋士の過去の対局・数十万の棋譜を記憶しているが(数は推定。後述)、イ・セドル九段はもちろんそんな数の棋譜を知っているわけではないし、さらに「アルファ碁」の棋譜もほとんど知らなかったと想定できることです。想像ですが「アルファ碁」は過去のイ・セドル九段の全対局を "予習" したのではないでしょうか。ディープマインド社にとって(そしてグーグルにとって)イ・セドル九段に勝つことは会社の価値を上げる最大の見せ場になるからです。違うかもしれません。しかし「相手の手の内を知る」という意味で、双方には圧倒的な情報格差があったことは事実でしょう。
それに加えて、人間側には不利な面があります。それは「人間があるがゆえの弱点」です。まず、イ九段には "この対局に負けると囲碁2000年の歴史を汚す" というような精神的プレッシャーがあったと想像できます。また、第1局に負けたあとは当然、大きな焦りが出てきただろうし、人間には一般的に言って「体調が悪い」とか「疲れ」とか「集中力が切れる」とかの弱さがあります。機械にはこういった弱点は全くありません。単純には比較できない感じがします。
とはいえ従来、コンピュータ囲碁がトップクラスの棋士に勝てる日などいつになるか分からないと考えられていたものが、こんなにも早く勝利するとは素晴らしいことだと思います。報道で「機械が勝利するのにあと10年はかかると考えられていた」とありましたが、IT技術やコンピュータ技術がこれだけ急速に進歩する中で「10年はかかる」というのは「いつになるか分からない」と同じことでしょう。その意味で、ディープマインド社の技術は凄いと言えます。まるで生命の突然変異のように急激な進化を遂げたように感じます。
この「アルファ碁」を開発したディープマインドとはどういう会社でしょうか。
ディープマインドの設立
グーグルは2014年1月に英国・ディープマインド社を推定4億ポンド(約700億円)で買収しました。そのとき設立3年目に入っていたディープマインドは、まだ売り上げを出していなかったし、それどころか製品すら出していなかった。なぜグーグルは約700億円も投じてそんな会社を買収したのでしょうか。実績のないベンチャー・ビジネスに対する投資としては金額が大きすぎます。
ディープマインド社は 2011年に3人の共同創業者によってロンドンで設立されました。いずれも20~30代の青年です。その共同創業者の一人がデミス・ハサビス氏で、現在の最高経営責任者(CEO)であり、アルファ碁開発の中心人物です。イ・セドル九段との5番勝負の報道でも、たびたび登場しました。
以下、小林雅一著『AIの衝撃』(講談社 現代新書 2015) から引用します。小林氏はKDDI研究所のリサーチフェローです。
から引用します。小林氏はKDDI研究所のリサーチフェローです。
この経歴をみるとハサビス氏はコンピュータ・サイエンスを学んだあと、脳の研究に取り組み、そのあとにディープマインド社を設立しています。おそらく新たなAI技術を確立するため海馬を研究し、そしてベンンチャー・ビジネスを起こすという長期的な考えがあったと想像されます。
引用中で "ニューラルネット" と書かれているのは、脳の神経細胞(ニューロン)の機能を模擬したコンピュータ・プログラムです。その中でも、多段に構成したニューラルネット(ディープ・ニューラルネットワーク)を用いて機械に学習をさせる「深層学習(ディープ・ラーニング)」が、現在のAI研究の主流になっています。ハサビス氏がディープマインド社で開発したのは深層学習の一分野である「強化学習」と呼ばれるジャンルのプログラムです。では、引用にある「過去の経験から何かを学んで、それを未来の行動に反映させるニューラルネット」とはどういうものでしょうか。
小林氏の『AIの衝撃』は一般読者向けに書かれた新書であり、その制約の中で「強化学習」を説明するのは難しいことがよく分かります。ちゃんと説明するのなら本来、数式を出さざるを得ないのでしょう。従って上の引用のような説明になり、我々読者としても "感覚的に" 理解するしかありません。
この説明のポイントは「限定的なフィードバック」というところですね。プログラムが出した答えに対して、OK / NG などの簡潔なフィードバックを与えることで、プログラムが学習し、正しい答えを出すように自ら変化していく。OK / NG だけでなく、どの程度 OK か、どの程度ダメかという点数を教えるのも「限定的なフィードバック」と考えられます。とにかく「この点がダメだから、ここをもう少しこういう風に直したらいい」というような "微に入り細に渡る" フィードバックではなく「限定的なフィードバック」を返すことによって、ニューラルネットのプログラムを成長させる。ここがポイントでしょう。
ゲーム機でスカッシュを模した単純なゲームで遊ぶことを考えてみます。ビデオ画面にはボールが上方から投げられ、それを下辺にあるラケットを左ボタン・右ボタンを動かすだけで打ち返す。再び上・左・右の壁で跳ね返ってきたボールをまた打ち返す。ボールのスピードはだんだん早くなり、打ち返せなかったらゲーム終了。打ち返した数がポイントになり、そのポイントの多さを競う。そういうゲームを想定します。
とすると、ディープマインド社の「強化学習型のディープ・ラーニング = 深層強化学習」は次のようなことが出来ることになります。そのコンピュータ・プログラムに、0.1秒ごとのビデオ画面の画像データを送り込む。そうすると直前の数個の画面データを覚えていたコンピュータ・プログラムは、どのボタンを押すか(押し続けるか・離すか)を判断する。これを0.1秒ごとに繰り返す。ボールを打ち返せなければNGのフィードバックを与え、多く打ち返せるとOKのフィードバックをポイント分だけ与える。そうすると、初めはすぐにゲーム終了になるが、次第にコンピュータ・プログラムは玉を打ち返すようになる・・・・・・。
強化学習ができるということは、そういうことになります。当初、コンピュータ・プログラムはゲームのルールを知りません。次第に上達するということは、コンピュータ・プログラムがルールを「理解した」と考えてもいいわけです。
これは革新的な技術です。なぜなら、ゲームをしてフィードバックを返すということがすべてコンピュータ内部で出来るわけであり、24時間、365日、延々とゲームを繰り返えせるからです。そのたびに深層強化学習のプログラムは、少づつ "賢く" なっていく。ついには人間に追いつくでしょう。この "スカッシュ ゲーム" どおりのことがあったわけではありませんが、ごく簡略化して書くと、本質的にはこのようだと思います。
事実、ディープマインド社はゲームソフトで有名なアタリ社の商用ゲームで強化学習の有用性を実証したのです。
実はグーグルのディープマインド買収のきっかけになったのは、この「ビデオ・ゲームを人間並に(人間以上に)うまくやるAIプログラム」だったのです。
アルファ碁(AlphaGo)
ディープマインドが開発したアルファ碁の話です。「Nature ダイジェスト 2016年3月号」にその技術の紹介が載っていました。この号が発売された時点で、イ・セドル九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。ディープマインド社はそれを踏まえ、「Nature誌 1月17日号」に「機械学習によって人工知能(AI)が囲碁をマスターした」との発表をしました。そのダイジェストが2016年3月号の記事です。
まず大切なことがあります。従来のボード・ゲームのプログラムは、そのゲーム専用のものでした。チェスの世界チャンピオンを破ったIBMのディープ・ブルー、日本で多く開発されているコンピュータ将棋のソフト、欧米や日本で盛んな囲碁ソフトなどは皆そうです。しかしアルファ碁は違います。
小林雅一『AIの衝撃』にも、アタリ社が開発した卓球ゲームをAIがマスターしたことが書かれていました。それと同じ種類のプログラムが囲碁をマスターしたというわけです。もちろん、基本的な囲碁のルール(たとえば、ダメを打てるのは相手の石を取る時だけとか、コウはすぐには取り返せないとか、地の多さで勝敗を決めるとか・・・・・・)は覚え込ませる必要があります。しかし基本的にはビデオ・ゲームをプレイするのと同じアルゴリズムで囲碁をするというわけです。ここは重要だと思います。というのも、汎用アルゴリズムであるからには他のゲームにも応用が利くし、さらにはゲームを越えて各種の社会問題にも適用できる可能性を示唆しているからです。「Nature ダイジェスト」には、囲碁をマスターした具体的なやりかたが書かれています。
ここの説明のポイントは、
というところです。日本で盛んなコンピュータ将棋のプログラムからの類推で考えますと、コンピュータ将棋で第一に重要なのは、局面の形勢(優劣)を判断する「評価関数」を作ることです。コンピュータ将棋の初期において、評価関数は将棋の知識のあるプログラム開発者の "手作り" でした。つまり、どういう変数を使い、どのような演算をして局面の優劣を的確に判断できる「評価値」を導くのか、それはプログラム開発者の将棋の経験にたよっていました。
この状況を一変させ、コンピュータ将棋がプロの棋士を破るまでになったのは、2005年に公開された Bonanza(ボナンザ)が契機でした。Bonanzaは当時カナダのトロント在住の学者(専門は化学)、保木邦仁氏が開発したプログラムですが、画期的だったのは評価関数の作成に「機械学習」を取り入れたことです。つまり保木氏はプロ棋士の棋譜を6万局以上集め、統計で用いる回帰分析の手法で評価関数を作り出したのです。この関数に使われた変数は1万以上と言います。
将棋の平均手数を120手とすると(これはいろんな説があります。仮に、ということです)、6万局の棋譜には720万の局面があることになります。この720万の局面には、それぞれ一つ前の局面があります。そこからプロが1手を指してその局面になったわけです。ということは、プロが指さなかった多数の手(将棋のルールでは可能な手)があることになり、その多数の手によって実際には現れなかった局面が仮定できます。評価関数としては「実際には現れなかった局面」より「実際に現れた局面」の評価が高くなるように変数を決め、関数を調整するということになります。
もちろんプロと言えども「最善手」を常に指せるわけではないし、中には「悪手」もあるでしょう。しかし悪手といっても「プロが指した悪手」です。アマチュアの悪手とはわけが違う。さらに6万局の中には「アマチュアでもやらないようなポカミス」が混じっていることもありうる。しかしそのような手はプロである限りごく少数であり、評価関数の大勢には影響しないでしょう。
重要なことは、こういった機械学習の手法で評価関数を作るのに将棋の棋力はあまりいらないことです。保木氏は著書(「ボナンザ VS 勝負脳」角川書店 )で、自分の棋力をアマチュア5級程度と述べています。棋力よりも統計学や数学、コンピュータ・サイエンス、論理的思考の勝負です。
)で、自分の棋力をアマチュア5級程度と述べています。棋力よりも統計学や数学、コンピュータ・サイエンス、論理的思考の勝負です。
以上を踏まえてアルファ碁の話に戻りますと、上の引用の中に、
と書かれているのは、コンピュータ将棋で言うと「評価関数を作った」ということと同等でしょう。それをディープマインド社はニューラルネットワークを用い、深層学習の手法で行った。その手順は引用にあるように、
なわけです。グーグルがネット上に公開されている大量の猫の写真をもとに深層学習で「与えられた画像が、猫か猫でないか」を判別するプログラムを作ったと話題になったことがありました。また深層学習を使った手書き文字の認識プログラムも同じです。人間は猫の特徴やアルファベットの各文字の特徴をプログラムに教えず、プログラムが深層学習で判別能力をつけていく。アルファ碁もそれと同様です。囲碁のある局面は、19×19の合計361の交点に白石があるか、黒石があるか、何もないかのパターンです。そのパターンを入力すると、形勢判断ができる。そういうプログラム(ニューラルネットワーク)を深層学習で作ったことになります。
プロ棋士の3000万通りの局面と書かれています。囲碁の平均手数を仮に200とすると、15万局の棋譜ということになります。囲碁の自由度の多さを考えると、コンピュータ将棋・Bonanzaが機械学習に使った6万局と比べて少ないと感じますが、これがプロ棋士の棋譜を集められる限界だったのかもしれません。
ここでディープマインドの得意技術である「強化学習」が出てきます。「強化学習」とは、先に引用した小林雅一『AIの衝撃』に書かれている通りですが、その強化学習はプログラム同士の自己対局で行ったわけです。もともとアルファ碁が機械学習で "評価関数" を作る際に用いたプロの対局は15万局程度と推定されるのですが、自己対局による強化学習ではそれより遙かに多い対局数をこなしたと想像できます。このあたりに、強化学習というAI技術のメリットが現れていると思います。強化学習を終えたアルファ碁は「市販の(最強の)囲碁プログラムと同等の強さ」になったようです。
このあとは「読みの力」をつける作業です。ふたたびコンピュータ将棋から考えますと、評価関数に続く第二のポイントは「指し手の探索アルゴリズム」です。先手に(評価の高い)数手が考えられ、それぞれの手について後手にも数手が考えられるとすると、これを続けていくことで、いわゆる「ゲーム木(ツリー)」ができます。この「ゲーム木」を探索する必要がある。このとき、先手も後手も最善を尽くすと仮定します。数手~数十手先の「先手にとっての評価が高い局面」を探索するのですが、しかしその先手有利の局面が直前の後手の「悪手」で引き起こされたのなら、それは読みから排除しなければならない(双方が最善の原則)。というように、先々どうなるかを読んで次の一手を決める必要があります。
「ゲーム木」は先読みの数が増えるとすぐに膨大な数になるので、制限時間内にどこまで先を読むか、どの手を評価してどの手を評価しない(読まない)のか、プログラムが判断する必要があります。もちろんコンピュータの性能にも大きく依存します。この「ゲーム木の探索アルゴリズム」の優劣が、プログラムの強さを決める第二のポイントです。上の引用における
のところは、この「ゲーム木の探索」のことを言っているのですが、少々分かりにくい文章です。まず「この探索アプローチ」とは、文のつながり上、「市販の囲碁プログラム(手筋のシミュレーションによって最良の手を選択する)の探索アプローチ」だと理解できます。そして「次に打つ手を選択して碁盤を読む能力」とは、強化学習の結果得られた「盤面の意味を読み取って最良の一手を選択する術」のことだと読めます。つまりアルファ碁は、強化学習で得られたディープマインド独自の "評価関数" と、市販の(最強の)囲碁プログラムと同等の「ゲーム木探索アルゴリズム」を組み合わせたということでしょう。もちろんここで書いた "評価関数" は、多層に重ねられたニューラルネットワーク(ディープ・ニューラルネットワーク)で実現されているものです。
以上の「Nature ダイジェスト」の記事を総括すると、ディープマインドのアルファ碁の独自性とは、
の二つだと読み取れます。つまり一言で言うと「深層強化学習」です。このうち、①の深層学習は他の囲碁プログラムにも実装例があるようです(例:フェイスブック開発のdarkforest)。ということは、最初に紹介した小林氏の『AIの衝撃』にあった「ディープマインドが専門とするAI技術は、ディープラーニングの中でも強化学習と呼ばれる細分化された領域」というところに戻るわけです。そこがアルファ碁の強さの秘密だと判断できます。もっと詳しい技術情報が Wikipedia などのネットで公開されているのですが、細かくなるので割愛したいと思います。
以降、この対局とディープマインドについて強く印象に残った4点をまとめます。「囲碁に新しい風を吹き込む」「コンピュータの歴史の転換点」「人工知能のリスク」「ゲームが導いた革新」の4つの視点です。
囲碁に新しい風を吹き込む
まず「アルファ碁」とイ・セドル九段の5番勝負ですが、この対局に関する各種の報道で印象的だったのは、勝負を観戦した日本のトップ・プロの感想でした。第5局(アルファ碁の勝ち)についての朝日新聞(2016.3.24 夕刊)の記事からです。
二人の意見に共通しているのは、アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということです。これには、なるほどと思いました。
囲碁は最終的には地の多少を争うゲームです。地は隅が作りやすく、その次に作りやすいのが辺で、中央が一番作りにくい。手を読むのも、特に序盤から中盤にかけては、隅→辺→中央の順に読みにくくなります。中央はいちばん手が広い(=たくさんの選択肢がありうる)からです。中央が読みにくいということから、中央を打つときには "感覚" に頼ることが多くなる。この "感覚" がくせ者です。それは先生から弟子へと(王九段が言うように、弟子は先生に叱り飛ばされながら)受け継がれてきたものでしょう。さらには先人から現代の棋士へと受け継がれてきた。その囲碁の歴史で醸成されてきた "感覚" は、果たしてどの程度まで正しいのか。中央の手を読むより、隅や辺の手を精密に読むことに慣れた人間の "感覚" がどこまで正当化できるのか、ということがあると思うのです。
アルファ碁にとって、隅・辺・中央の違いはありません。盤面全体を一つのパターンとしてとらえて最善手を見つけようとする。辺の打ち方で20手先を読むのも、中央の打ち方で20手先を読むのも変わらない。中央の手が広ければ、読みの探索範囲が増えます。従って読みを省略する手は相対的に増えるでしょうが、読む "深さ" は、隅や辺と変わらないはずです。
アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということは、はからずも今までのプロ棋士たちの囲碁研究で「手薄だった」部分が露呈したということではないでしょうか。アルファ碁はそれを明らかにした。上に引用した王九段も井上名人もそれを感じたのではと思います。
二人の発言から感じるのは、囲碁の世界においてもコンピュータと共存していこうという意志です。確かに今回は教えられた、しかしその教えられたことをベースに、自分自身ももっと強くなるぞ、というような二人の意欲を感じます。コンピュータ技術と人間の知恵の相乗効果で、双方がレベルアップしていくという未来を感じさせる、爽やかなコメントでした。
コンピュータの歴史の転換点
アルファ碁の勝利を前にすると、AIは万能のように考えてしまう人が出てくると思いますが、それは違うでしょう。まず、アルファ碁は「人間の知恵の集積」がベースになっています。アルファ碁が機械学習に使った3000万の局面はあくまで近年のものだと思いますが、そのバックには「囲碁2000年の歴史」があり、アルファ碁はそこからスタートしているわけです。しかも人間なら3000万の局面を記憶する必要はなく、少量の過去の棋譜から類推・推量が可能です。
さらに囲碁は「情報が全部開示されている」ゲームですが、ゲームにはそうでないもの(たとえば麻雀)があります。またゲームを離れてAIを広く適用すること考えると、たとえば医療診断では情報は不完全なことが多いし、中には間違った情報があるかも知れない。医療診断にかかわらず、社会で行われている判断の多くはそうです。情報は不完全であり、しかもルールが変わったり、グレーだったりする。囲碁のルールは変わりませんが・・・・・・。AIを万能のように考えるのは大きな誤りでしょう。
とはいえ、アルファ碁がトッププロとの5番勝負に勝ったという「事件」は、非常に素晴らしいことだし、単にゲームの世界の話に留まらないと感じます。IBMのコンピュータがチェスの世界チャンピオンを負かしたことや、クイズ番組で優勝したことよりも格段に大きな事件でしょう。現代のデジタル・コンピュータのルーツは1946年のENIAC(ペンシルヴァニア大学。真空管式)と言われていますが、そうするとコンピュータには70年の歴史があることになります。そのコンピュータ70年の歴史の転換点がこの対局であり、後世の人から必ずそう言われると確信します。
人工知能(AI)のリスク
ディープマインド社は大きなブレークスルーを成し遂げました。しかし一般に科学技術には負の側面があることが多いわけです。ディープマインド社について非常に印象に残った逸話があります。グーグルに買収されるにあたって、ディープマインド社はグーグルに対し「AI倫理委員会」の設立を要求したという件です。
「人類はテクノロジーによって絶滅するだろう」というのは、ずいぶんペシミスティックな発言(ないしは人)ですが、核兵器の前例があるわけですね。AI専門家の重大な警告と受け取った方がいいでしょう。ふと、アーノルド・シュワルツネッガーを一躍スターにした「ターミネーター」を思い出しました。あの映画において、未来は人間とロボットの戦争状態になっているのですが、その発端は「人工知能が人間に核戦争をしかけた」という想定です。
しかし、AIのリスクはそういうことではないと思います。たとえばAI技術を使って新型の核兵器が開発できるかもしれません。現在の核兵器の開発は(条約加盟国は)実験ができず、コンピュータ・シミュレーションで開発されています。AIもコンピュータ技術の一種なのです。また、極めて効果的なサイバー攻撃(テロ)の手段がAI技術で生み出されるかもしれません。もっと一般には、AIを「活用」した犯罪はいくらでも考えられそうな気がします。
他の有用な科学技術と同様、AIも「光」とともに「影」を背負っているということでしょう。ディープマインドのレッグ氏の発言はそれを最も強い形で言ったと解釈できます。逆にいうと AI はそれだけ人間社会へのインパクトが強い技術である。そいういうことかと思いました。
ゲームが導いた革新
ディープマインド社が、自社の「強化学習」の有用性を検証するのに、米・アタリ社のビデオ・ゲームを使ったという話が出てきました。アタリ社は1972年に設立されたビデオ・ゲームの老舗です。設立者はノーラン・ブッシュネルという人ですが、彼は囲碁が大好きで、日本棋院の初段の免状を持っていました。社名の「アタリ」は囲碁用語の「アタリ」(次の手で相手の石が取れる状態)です。
ひょっとしたらノーラン・ブッシュネルはゲーム会社を設立しながら、将来に囲碁プログラムが出てきて人間との対局が可能になり、それがアマチュア高段者なみになり、ついにはプロのトップ棋士を破るまでになることを夢見ていたのかもしれません。反対に、そんなことは夢想だにできなかったのかもしれない。しかし、囲碁プログラムがトップ棋士を破る日は、アタリ社が設立されてから 44年後にやってきた。IT技術の驚くべき進歩です。
さらにコンピュータ・ゲームつながりで言うと、アルファ碁を開発したディープマインド社のデミス・ハサビス氏は、ディープマインドを設立する前にゲーム会社を作っているのですね(小林雅一著『AIの衝撃』)。おそらく彼はゲームのプログラムを開発しながら、そのゲームをプレイするプログラムを作りたいと強く思ったのではないでしょうか。
囲碁、アタリ社、デミス・ハサビス、アルファ碁は、すべて「ゲーム」というキーワードで相互につながっています。人間社会を革新するかもしれない重要なAI技術が、ゲームとの深い関わりの中で生まれてきた。その中でも特に囲碁がAI技術者の挑戦意欲をかき立て、そこで実証された革新が社会に応用されようとしているわけです。
ゲームは「暇つぶし」であり「娯楽」ですが、同時に「頭脳のスポーツ」でもあり、また、それを職業とする人が成立するほど人間社会に根を下ろしたものです。しかしゲームはそれ以上のものでしょう。それは人間社会における革新を導く何かでもある。今回のアルファ碁の勝利で強く思ったのは、それが「ゲームに導かれた技術革新」だということでした。
ディープマインド社のアルファ碁が実現しているアルゴリズムの詳細を、次の二つの記事に書きました。合わせて参照ください。
| AIBOは最後のモルモットか | |||
| データの見えざる手(2) | |||
| インフルエンザの流行はGoogleが予測する |
の3つです。No.159 の "AIBO" は AI技術を利用したソニーの犬型ロボットで、1999年に発売が開始され、2006年に販売終了しました。さすがソニーと思える先進的な製品です。また、No.166「データの見えざる手(2)」で紹介したのは「ホームセンターの業績向上策」をAI技術を利用して見い出したという事例でした。さらにNo.173は、グーグルが人々の検索ワードを蓄積したビッグデータをもとに、AI技術を応用してインフルエンザの流行予測を行った例でした。
そのAI関連の継続で、今回はグーグルが2014年に買収した英国の会社、ディープマインド社について書きたいと思います。この会社がつくった「アルファ碁」というコンピュータ・プログラムは、囲碁の世界トップクラスの棋士と対戦して4勝1敗の成績をあげ、世界中で大変な話題になりました。
「アルファ碁」とイ・セドル九段の5番勝負
2016年3月、韓国のイ・セドル(李世乭)九段とディープマインド社の「アルファ碁」の5番勝負がソウル市内で行われ、「アルファ碁」の4勝1敗となりました。イ・セドル九段は世界のトップクラスの棋士であり(世界No.1とも、No.2とも言われる)、囲碁の世界では大変な強豪です。コンピュータはその棋士に "勝った" ことになります。

| ||
|
AlphaGo vs イ・セドル9段(右)第1局
(YouTube)
| ||
もっとも、これが真に "対等な勝負" なのかは疑問があります。それは、「アルファ碁」は世界のプロ棋士の過去の対局・数十万の棋譜を記憶しているが(数は推定。後述)、イ・セドル九段はもちろんそんな数の棋譜を知っているわけではないし、さらに「アルファ碁」の棋譜もほとんど知らなかったと想定できることです。想像ですが「アルファ碁」は過去のイ・セドル九段の全対局を "予習" したのではないでしょうか。ディープマインド社にとって(そしてグーグルにとって)イ・セドル九段に勝つことは会社の価値を上げる最大の見せ場になるからです。違うかもしれません。しかし「相手の手の内を知る」という意味で、双方には圧倒的な情報格差があったことは事実でしょう。
それに加えて、人間側には不利な面があります。それは「人間があるがゆえの弱点」です。まず、イ九段には "この対局に負けると囲碁2000年の歴史を汚す" というような精神的プレッシャーがあったと想像できます。また、第1局に負けたあとは当然、大きな焦りが出てきただろうし、人間には一般的に言って「体調が悪い」とか「疲れ」とか「集中力が切れる」とかの弱さがあります。機械にはこういった弱点は全くありません。単純には比較できない感じがします。
とはいえ従来、コンピュータ囲碁がトップクラスの棋士に勝てる日などいつになるか分からないと考えられていたものが、こんなにも早く勝利するとは素晴らしいことだと思います。報道で「機械が勝利するのにあと10年はかかると考えられていた」とありましたが、IT技術やコンピュータ技術がこれだけ急速に進歩する中で「10年はかかる」というのは「いつになるか分からない」と同じことでしょう。その意味で、ディープマインド社の技術は凄いと言えます。まるで生命の突然変異のように急激な進化を遂げたように感じます。
この「アルファ碁」を開発したディープマインドとはどういう会社でしょうか。
ディープマインドの設立
グーグルは2014年1月に英国・ディープマインド社を推定4億ポンド(約700億円)で買収しました。そのとき設立3年目に入っていたディープマインドは、まだ売り上げを出していなかったし、それどころか製品すら出していなかった。なぜグーグルは約700億円も投じてそんな会社を買収したのでしょうか。実績のないベンチャー・ビジネスに対する投資としては金額が大きすぎます。
ディープマインド社は 2011年に3人の共同創業者によってロンドンで設立されました。いずれも20~30代の青年です。その共同創業者の一人がデミス・ハサビス氏で、現在の最高経営責任者(CEO)であり、アルファ碁開発の中心人物です。イ・セドル九段との5番勝負の報道でも、たびたび登場しました。
以下、小林雅一著『AIの衝撃』(講談社 現代新書 2015)
|
この経歴をみるとハサビス氏はコンピュータ・サイエンスを学んだあと、脳の研究に取り組み、そのあとにディープマインド社を設立しています。おそらく新たなAI技術を確立するため海馬を研究し、そしてベンンチャー・ビジネスを起こすという長期的な考えがあったと想像されます。

| ||
|
ディープマインド社 デミス・ハサビスCEO
(sie : www.nature.com)
| ||
引用中で "ニューラルネット" と書かれているのは、脳の神経細胞(ニューロン)の機能を模擬したコンピュータ・プログラムです。その中でも、多段に構成したニューラルネット(ディープ・ニューラルネットワーク)を用いて機械に学習をさせる「深層学習(ディープ・ラーニング)」が、現在のAI研究の主流になっています。ハサビス氏がディープマインド社で開発したのは深層学習の一分野である「強化学習」と呼ばれるジャンルのプログラムです。では、引用にある「過去の経験から何かを学んで、それを未来の行動に反映させるニューラルネット」とはどういうものでしょうか。
|

| |||
この説明のポイントは「限定的なフィードバック」というところですね。プログラムが出した答えに対して、OK / NG などの簡潔なフィードバックを与えることで、プログラムが学習し、正しい答えを出すように自ら変化していく。OK / NG だけでなく、どの程度 OK か、どの程度ダメかという点数を教えるのも「限定的なフィードバック」と考えられます。とにかく「この点がダメだから、ここをもう少しこういう風に直したらいい」というような "微に入り細に渡る" フィードバックではなく「限定的なフィードバック」を返すことによって、ニューラルネットのプログラムを成長させる。ここがポイントでしょう。
ゲーム機でスカッシュを模した単純なゲームで遊ぶことを考えてみます。ビデオ画面にはボールが上方から投げられ、それを下辺にあるラケットを左ボタン・右ボタンを動かすだけで打ち返す。再び上・左・右の壁で跳ね返ってきたボールをまた打ち返す。ボールのスピードはだんだん早くなり、打ち返せなかったらゲーム終了。打ち返した数がポイントになり、そのポイントの多さを競う。そういうゲームを想定します。
とすると、ディープマインド社の「強化学習型のディープ・ラーニング = 深層強化学習」は次のようなことが出来ることになります。そのコンピュータ・プログラムに、0.1秒ごとのビデオ画面の画像データを送り込む。そうすると直前の数個の画面データを覚えていたコンピュータ・プログラムは、どのボタンを押すか(押し続けるか・離すか)を判断する。これを0.1秒ごとに繰り返す。ボールを打ち返せなければNGのフィードバックを与え、多く打ち返せるとOKのフィードバックをポイント分だけ与える。そうすると、初めはすぐにゲーム終了になるが、次第にコンピュータ・プログラムは玉を打ち返すようになる・・・・・・。
強化学習ができるということは、そういうことになります。当初、コンピュータ・プログラムはゲームのルールを知りません。次第に上達するということは、コンピュータ・プログラムがルールを「理解した」と考えてもいいわけです。
これは革新的な技術です。なぜなら、ゲームをしてフィードバックを返すということがすべてコンピュータ内部で出来るわけであり、24時間、365日、延々とゲームを繰り返えせるからです。そのたびに深層強化学習のプログラムは、少づつ "賢く" なっていく。ついには人間に追いつくでしょう。この "スカッシュ ゲーム" どおりのことがあったわけではありませんが、ごく簡略化して書くと、本質的にはこのようだと思います。
事実、ディープマインド社はゲームソフトで有名なアタリ社の商用ゲームで強化学習の有用性を実証したのです。
|
実はグーグルのディープマインド買収のきっかけになったのは、この「ビデオ・ゲームを人間並に(人間以上に)うまくやるAIプログラム」だったのです。
|
アルファ碁(AlphaGo)
ディープマインドが開発したアルファ碁の話です。「Nature ダイジェスト 2016年3月号」にその技術の紹介が載っていました。この号が発売された時点で、イ・セドル九段との対戦はまだ行われていません。アルファ碁は、2015年10月に囲碁の欧州チャンピオンに5戦5勝の成績をあげました。ディープマインド社はそれを踏まえ、「Nature誌 1月17日号」に「機械学習によって人工知能(AI)が囲碁をマスターした」との発表をしました。そのダイジェストが2016年3月号の記事です。
まず大切なことがあります。従来のボード・ゲームのプログラムは、そのゲーム専用のものでした。チェスの世界チャンピオンを破ったIBMのディープ・ブルー、日本で多く開発されているコンピュータ将棋のソフト、欧米や日本で盛んな囲碁ソフトなどは皆そうです。しかしアルファ碁は違います。
|
小林雅一『AIの衝撃』にも、アタリ社が開発した卓球ゲームをAIがマスターしたことが書かれていました。それと同じ種類のプログラムが囲碁をマスターしたというわけです。もちろん、基本的な囲碁のルール(たとえば、ダメを打てるのは相手の石を取る時だけとか、コウはすぐには取り返せないとか、地の多さで勝敗を決めるとか・・・・・・)は覚え込ませる必要があります。しかし基本的にはビデオ・ゲームをプレイするのと同じアルゴリズムで囲碁をするというわけです。ここは重要だと思います。というのも、汎用アルゴリズムであるからには他のゲームにも応用が利くし、さらにはゲームを越えて各種の社会問題にも適用できる可能性を示唆しているからです。「Nature ダイジェスト」には、囲碁をマスターした具体的なやりかたが書かれています。
|
ここの説明のポイントは、
| 何層にも重ねられたニューラルネットワークを使った、ディープラーニング(深層学習)を使って、盤面の形勢を判断する手法を確立した |
というところです。日本で盛んなコンピュータ将棋のプログラムからの類推で考えますと、コンピュータ将棋で第一に重要なのは、局面の形勢(優劣)を判断する「評価関数」を作ることです。コンピュータ将棋の初期において、評価関数は将棋の知識のあるプログラム開発者の "手作り" でした。つまり、どういう変数を使い、どのような演算をして局面の優劣を的確に判断できる「評価値」を導くのか、それはプログラム開発者の将棋の経験にたよっていました。
この状況を一変させ、コンピュータ将棋がプロの棋士を破るまでになったのは、2005年に公開された Bonanza(ボナンザ)が契機でした。Bonanzaは当時カナダのトロント在住の学者(専門は化学)、保木邦仁氏が開発したプログラムですが、画期的だったのは評価関数の作成に「機械学習」を取り入れたことです。つまり保木氏はプロ棋士の棋譜を6万局以上集め、統計で用いる回帰分析の手法で評価関数を作り出したのです。この関数に使われた変数は1万以上と言います。
将棋の平均手数を120手とすると(これはいろんな説があります。仮に、ということです)、6万局の棋譜には720万の局面があることになります。この720万の局面には、それぞれ一つ前の局面があります。そこからプロが1手を指してその局面になったわけです。ということは、プロが指さなかった多数の手(将棋のルールでは可能な手)があることになり、その多数の手によって実際には現れなかった局面が仮定できます。評価関数としては「実際には現れなかった局面」より「実際に現れた局面」の評価が高くなるように変数を決め、関数を調整するということになります。
もちろんプロと言えども「最善手」を常に指せるわけではないし、中には「悪手」もあるでしょう。しかし悪手といっても「プロが指した悪手」です。アマチュアの悪手とはわけが違う。さらに6万局の中には「アマチュアでもやらないようなポカミス」が混じっていることもありうる。しかしそのような手はプロである限りごく少数であり、評価関数の大勢には影響しないでしょう。
重要なことは、こういった機械学習の手法で評価関数を作るのに将棋の棋力はあまりいらないことです。保木氏は著書(「ボナンザ VS 勝負脳」角川書店
以上を踏まえてアルファ碁の話に戻りますと、上の引用の中に、
| 盤面データから形勢に関する抽象的な情報を抽出した |
と書かれているのは、コンピュータ将棋で言うと「評価関数を作った」ということと同等でしょう。それをディープマインド社はニューラルネットワークを用い、深層学習の手法で行った。その手順は引用にあるように、
| 画素に基づいて画像を分類するプログラムと同様 |
なわけです。グーグルがネット上に公開されている大量の猫の写真をもとに深層学習で「与えられた画像が、猫か猫でないか」を判別するプログラムを作ったと話題になったことがありました。また深層学習を使った手書き文字の認識プログラムも同じです。人間は猫の特徴やアルファベットの各文字の特徴をプログラムに教えず、プログラムが深層学習で判別能力をつけていく。アルファ碁もそれと同様です。囲碁のある局面は、19×19の合計361の交点に白石があるか、黒石があるか、何もないかのパターンです。そのパターンを入力すると、形勢判断ができる。そういうプログラム(ニューラルネットワーク)を深層学習で作ったことになります。
プロ棋士の3000万通りの局面と書かれています。囲碁の平均手数を仮に200とすると、15万局の棋譜ということになります。囲碁の自由度の多さを考えると、コンピュータ将棋・Bonanzaが機械学習に使った6万局と比べて少ないと感じますが、これがプロ棋士の棋譜を集められる限界だったのかもしれません。
|
ここでディープマインドの得意技術である「強化学習」が出てきます。「強化学習」とは、先に引用した小林雅一『AIの衝撃』に書かれている通りですが、その強化学習はプログラム同士の自己対局で行ったわけです。もともとアルファ碁が機械学習で "評価関数" を作る際に用いたプロの対局は15万局程度と推定されるのですが、自己対局による強化学習ではそれより遙かに多い対局数をこなしたと想像できます。このあたりに、強化学習というAI技術のメリットが現れていると思います。強化学習を終えたアルファ碁は「市販の(最強の)囲碁プログラムと同等の強さ」になったようです。
このあとは「読みの力」をつける作業です。ふたたびコンピュータ将棋から考えますと、評価関数に続く第二のポイントは「指し手の探索アルゴリズム」です。先手に(評価の高い)数手が考えられ、それぞれの手について後手にも数手が考えられるとすると、これを続けていくことで、いわゆる「ゲーム木(ツリー)」ができます。この「ゲーム木」を探索する必要がある。このとき、先手も後手も最善を尽くすと仮定します。数手~数十手先の「先手にとっての評価が高い局面」を探索するのですが、しかしその先手有利の局面が直前の後手の「悪手」で引き起こされたのなら、それは読みから排除しなければならない(双方が最善の原則)。というように、先々どうなるかを読んで次の一手を決める必要があります。
「ゲーム木」は先読みの数が増えるとすぐに膨大な数になるので、制限時間内にどこまで先を読むか、どの手を評価してどの手を評価しない(読まない)のか、プログラムが判断する必要があります。もちろんコンピュータの性能にも大きく依存します。この「ゲーム木の探索アルゴリズム」の優劣が、プログラムの強さを決める第二のポイントです。上の引用における
| 次にハサビスらはこの探索アプローチを次に打つ手を選択して碁盤を読む能力と組み合わせた |
のところは、この「ゲーム木の探索」のことを言っているのですが、少々分かりにくい文章です。まず「この探索アプローチ」とは、文のつながり上、「市販の囲碁プログラム(手筋のシミュレーションによって最良の手を選択する)の探索アプローチ」だと理解できます。そして「次に打つ手を選択して碁盤を読む能力」とは、強化学習の結果得られた「盤面の意味を読み取って最良の一手を選択する術」のことだと読めます。つまりアルファ碁は、強化学習で得られたディープマインド独自の "評価関数" と、市販の(最強の)囲碁プログラムと同等の「ゲーム木探索アルゴリズム」を組み合わせたということでしょう。もちろんここで書いた "評価関数" は、多層に重ねられたニューラルネットワーク(ディープ・ニューラルネットワーク)で実現されているものです。
以上の「Nature ダイジェスト」の記事を総括すると、ディープマインドのアルファ碁の独自性とは、
| ① | 局面の優劣の判断にディープラーニング(深層学習)による機械学習を用いた | ||
| ② | さらにディープマインド独自の強化学習によって正確な優劣判断ができるようになった |
の二つだと読み取れます。つまり一言で言うと「深層強化学習」です。このうち、①の深層学習は他の囲碁プログラムにも実装例があるようです(例:フェイスブック開発のdarkforest)。ということは、最初に紹介した小林氏の『AIの衝撃』にあった「ディープマインドが専門とするAI技術は、ディープラーニングの中でも強化学習と呼ばれる細分化された領域」というところに戻るわけです。そこがアルファ碁の強さの秘密だと判断できます。もっと詳しい技術情報が Wikipedia などのネットで公開されているのですが、細かくなるので割愛したいと思います。
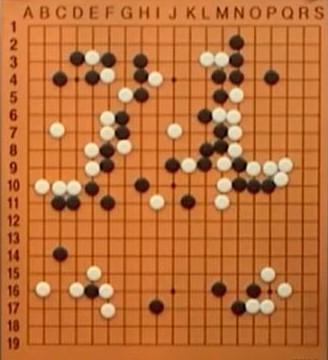
| ||
|
アルファ碁(黒)対 イ・セドル九段(白)第4局
白78(K9)が打たれた局面 イ・セドル九段がアルファ碁に唯一勝ったのが第4局だが、上の図はイ・セドル九段が白78(K9)のワリコミを打った局面。ライブ中継の解説を担当していたマイケル・レドモンド九段は白78を予想していなかったが、打たれた瞬間 "Exciting" と評していた。イ・セドル九段が放った勝負手である。レドモンド九段の解説にあったように、この手は白H6のキリを睨んでいて、黒の応手は難しい。黒にシノギの筋はあるのだが、その読みが簡単ではない。 これ以降、アルファ碁は疑問手を続発し、明らかな悪手も加わって、アルファ碁の投了で終わった。イ・セドル九段の白78は人間の創造力を見せつけた一手だった。 (YouTube)
| ||
以降、この対局とディープマインドについて強く印象に残った4点をまとめます。「囲碁に新しい風を吹き込む」「コンピュータの歴史の転換点」「人工知能のリスク」「ゲームが導いた革新」の4つの視点です。
囲碁に新しい風を吹き込む
まず「アルファ碁」とイ・セドル九段の5番勝負ですが、この対局に関する各種の報道で印象的だったのは、勝負を観戦した日本のトップ・プロの感想でした。第5局(アルファ碁の勝ち)についての朝日新聞(2016.3.24 夕刊)の記事からです。
| 「勉強になりました。右辺を広げる手の中には、いままでの感覚とはかけ離れたものがあった。弟子が打ったら、しかり飛ばすような」(王 銘琬 九段) | |||
| 「こう打てばいいんだよ、と教えてくれているような感じでした。空間や中央の感覚が人間と違う。懐が深い」(井山 裕太 名人) |
二人の意見に共通しているのは、アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということです。これには、なるほどと思いました。
囲碁は最終的には地の多少を争うゲームです。地は隅が作りやすく、その次に作りやすいのが辺で、中央が一番作りにくい。手を読むのも、特に序盤から中盤にかけては、隅→辺→中央の順に読みにくくなります。中央はいちばん手が広い(=たくさんの選択肢がありうる)からです。中央が読みにくいということから、中央を打つときには "感覚" に頼ることが多くなる。この "感覚" がくせ者です。それは先生から弟子へと(王九段が言うように、弟子は先生に叱り飛ばされながら)受け継がれてきたものでしょう。さらには先人から現代の棋士へと受け継がれてきた。その囲碁の歴史で醸成されてきた "感覚" は、果たしてどの程度まで正しいのか。中央の手を読むより、隅や辺の手を精密に読むことに慣れた人間の "感覚" がどこまで正当化できるのか、ということがあると思うのです。
アルファ碁にとって、隅・辺・中央の違いはありません。盤面全体を一つのパターンとしてとらえて最善手を見つけようとする。辺の打ち方で20手先を読むのも、中央の打ち方で20手先を読むのも変わらない。中央の手が広ければ、読みの探索範囲が増えます。従って読みを省略する手は相対的に増えるでしょうが、読む "深さ" は、隅や辺と変わらないはずです。
アルファ碁は空間や中央の打ち方にプロ棋士とは違った "感覚" を示したということは、はからずも今までのプロ棋士たちの囲碁研究で「手薄だった」部分が露呈したということではないでしょうか。アルファ碁はそれを明らかにした。上に引用した王九段も井上名人もそれを感じたのではと思います。
二人の発言から感じるのは、囲碁の世界においてもコンピュータと共存していこうという意志です。確かに今回は教えられた、しかしその教えられたことをベースに、自分自身ももっと強くなるぞ、というような二人の意欲を感じます。コンピュータ技術と人間の知恵の相乗効果で、双方がレベルアップしていくという未来を感じさせる、爽やかなコメントでした。
コンピュータの歴史の転換点
アルファ碁の勝利を前にすると、AIは万能のように考えてしまう人が出てくると思いますが、それは違うでしょう。まず、アルファ碁は「人間の知恵の集積」がベースになっています。アルファ碁が機械学習に使った3000万の局面はあくまで近年のものだと思いますが、そのバックには「囲碁2000年の歴史」があり、アルファ碁はそこからスタートしているわけです。しかも人間なら3000万の局面を記憶する必要はなく、少量の過去の棋譜から類推・推量が可能です。
さらに囲碁は「情報が全部開示されている」ゲームですが、ゲームにはそうでないもの(たとえば麻雀)があります。またゲームを離れてAIを広く適用すること考えると、たとえば医療診断では情報は不完全なことが多いし、中には間違った情報があるかも知れない。医療診断にかかわらず、社会で行われている判断の多くはそうです。情報は不完全であり、しかもルールが変わったり、グレーだったりする。囲碁のルールは変わりませんが・・・・・・。AIを万能のように考えるのは大きな誤りでしょう。
とはいえ、アルファ碁がトッププロとの5番勝負に勝ったという「事件」は、非常に素晴らしいことだし、単にゲームの世界の話に留まらないと感じます。IBMのコンピュータがチェスの世界チャンピオンを負かしたことや、クイズ番組で優勝したことよりも格段に大きな事件でしょう。現代のデジタル・コンピュータのルーツは1946年のENIAC(ペンシルヴァニア大学。真空管式)と言われていますが、そうするとコンピュータには70年の歴史があることになります。そのコンピュータ70年の歴史の転換点がこの対局であり、後世の人から必ずそう言われると確信します。
人工知能(AI)のリスク
ディープマインド社は大きなブレークスルーを成し遂げました。しかし一般に科学技術には負の側面があることが多いわけです。ディープマインド社について非常に印象に残った逸話があります。グーグルに買収されるにあたって、ディープマインド社はグーグルに対し「AI倫理委員会」の設立を要求したという件です。
|
「人類はテクノロジーによって絶滅するだろう」というのは、ずいぶんペシミスティックな発言(ないしは人)ですが、核兵器の前例があるわけですね。AI専門家の重大な警告と受け取った方がいいでしょう。ふと、アーノルド・シュワルツネッガーを一躍スターにした「ターミネーター」を思い出しました。あの映画において、未来は人間とロボットの戦争状態になっているのですが、その発端は「人工知能が人間に核戦争をしかけた」という想定です。
しかし、AIのリスクはそういうことではないと思います。たとえばAI技術を使って新型の核兵器が開発できるかもしれません。現在の核兵器の開発は(条約加盟国は)実験ができず、コンピュータ・シミュレーションで開発されています。AIもコンピュータ技術の一種なのです。また、極めて効果的なサイバー攻撃(テロ)の手段がAI技術で生み出されるかもしれません。もっと一般には、AIを「活用」した犯罪はいくらでも考えられそうな気がします。
他の有用な科学技術と同様、AIも「光」とともに「影」を背負っているということでしょう。ディープマインドのレッグ氏の発言はそれを最も強い形で言ったと解釈できます。逆にいうと AI はそれだけ人間社会へのインパクトが強い技術である。そいういうことかと思いました。
ゲームが導いた革新
ディープマインド社が、自社の「強化学習」の有用性を検証するのに、米・アタリ社のビデオ・ゲームを使ったという話が出てきました。アタリ社は1972年に設立されたビデオ・ゲームの老舗です。設立者はノーラン・ブッシュネルという人ですが、彼は囲碁が大好きで、日本棋院の初段の免状を持っていました。社名の「アタリ」は囲碁用語の「アタリ」(次の手で相手の石が取れる状態)です。
| つまり「アタリ」は日本語(=当たり)です。囲碁は中国が発祥ですが、近代囲碁が発達したのは日本で、そのため英語の囲碁用語も「ハネ」「シチョウ」「ダメヅマリ」など、日本語が多い。そもそも、英語で囲碁を示す Go は「碁」の日本語発音です。 |
ひょっとしたらノーラン・ブッシュネルはゲーム会社を設立しながら、将来に囲碁プログラムが出てきて人間との対局が可能になり、それがアマチュア高段者なみになり、ついにはプロのトップ棋士を破るまでになることを夢見ていたのかもしれません。反対に、そんなことは夢想だにできなかったのかもしれない。しかし、囲碁プログラムがトップ棋士を破る日は、アタリ社が設立されてから 44年後にやってきた。IT技術の驚くべき進歩です。
さらにコンピュータ・ゲームつながりで言うと、アルファ碁を開発したディープマインド社のデミス・ハサビス氏は、ディープマインドを設立する前にゲーム会社を作っているのですね(小林雅一著『AIの衝撃』)。おそらく彼はゲームのプログラムを開発しながら、そのゲームをプレイするプログラムを作りたいと強く思ったのではないでしょうか。
囲碁、アタリ社、デミス・ハサビス、アルファ碁は、すべて「ゲーム」というキーワードで相互につながっています。人間社会を革新するかもしれない重要なAI技術が、ゲームとの深い関わりの中で生まれてきた。その中でも特に囲碁がAI技術者の挑戦意欲をかき立て、そこで実証された革新が社会に応用されようとしているわけです。
ゲームは「暇つぶし」であり「娯楽」ですが、同時に「頭脳のスポーツ」でもあり、また、それを職業とする人が成立するほど人間社会に根を下ろしたものです。しかしゲームはそれ以上のものでしょう。それは人間社会における革新を導く何かでもある。今回のアルファ碁の勝利で強く思ったのは、それが「ゲームに導かれた技術革新」だということでした。
| 補記 : アルファ碁のロジック |
ディープマインド社のアルファ碁が実現しているアルゴリズムの詳細を、次の二つの記事に書きました。合わせて参照ください。
| アルファ碁の着手決定ロジック(1) | |||
| アルファ碁の着手決定ロジック(2) |
(2016.6.24)
2016-04-16 09:45
nice!(0)
トラックバック(0)



