No.149 - 我々は直感に裏切られる [科学]
前回のNo.148「最適者の到来」の続きです。我々は、日常感覚とは全くかけ離れた「数」や「量」の世界を想像し難いし、そういう世界についての日常感覚的な直感は "的外れ" になるというようなことを、前回の最後に書きました。
「最適者の到来」のテーマであった「進化」は、遺伝子型の変異が生物の表現型として現れ、自然選択の結果として最適者が残るというものです。このストーリーの発端になっている「遺伝子」とか「変異」とかは、いずれも生物の体内の分子レベルの話ですが、分子はその "サイズ" も "数" も我々が想像し難いような「小ささ」と「多さ」です。まず、そこを何とか想像してみたいと思います。
量の多さ:分子の数
簡単のために水の分子で考えてみます。コップ1杯の水を180g = 180ミリリットル(mL)とします。この中に水の分子はいくつあるでしょうか。
これは高校生で化学を習っている生徒なら即答できます。水を分子式で書くと H2O であり、分子量は 18(酸素=16、水素=1×2) なので「水 18g にはアボガドロ数だけの水分子が含まれる」ことになります。
なので、コップ1杯だとこれを10倍して、
になります。数字のカンマは10桁ごとにつけました。この水分子の「数の多さ」を想像することは、我々にとって非常に困難です。どこだったかは忘れたのですが、海の水に例えての説明を以前に読んだことがあります。卓抜な比喩だと思うので、それで想像してみたいと思います。
これは思考実験です。コップ1杯の水分子に「赤い色」をつけるというのが出発点です。水に赤い染料を混ぜるのではなく、分子そのものに赤い色をつける。もちろん現実にそんなことは出来ないのですが、あくまで思考実験として考えます。
(思考実験)
直観で答えるとすると、コップに入る「赤い色の水分子」は、あったとしても1個で、ほとんどの場合は無いと、多くの人は答えるのではないでしょうか。何しろ、世界中の海に均等に混ざってしまったのだから ・・・・・・。
この答は容易に計算できます。世界中にある海水の体積は約14億・立方キロメートルと推定されています。もう少し詳しくは、13.5億 とか 13.7億 とかの数字があります。ここでは13.5億・立方キロメートルとします。
です。立方キロメートルとは、縦・横・高さが 1 キロメートルの立方体の体積ということです。1 キロメートルは 1000メートル = 100,000(105)センチメートルなので、海の体積を立方センチメートル(=mL。ミリリットル)で表すには、1015 を掛けて、
となります。これがコップ何杯分に相当するかというと、180 mL で割り算をして、
となります。上の思考実験で「赤い水の分子」がふたたびコップに入る数(④)は、A/B ですから、
となります。つまり、世界中のありとあらゆる海のすべてが、表面から深海の底まで、コップ1杯あたり800個の赤い水分子で完全に埋め尽くされている状況です。これはちょっと想像を越えているのではないでしょうか。
分子の数はそれほど「多い」わけです。もちろん生命の進化に関わるような、DNAとかアミノ酸とかタンパク質、その他の生命体を構成している分子は、分子量で言うと数十から数百、数万になるものも珍しくありません。水分子とは比較にならない巨大分子であることは確かです。しかし、それでも「多い」。こういう超巨大な数の世界では我々の直感は働かないか、働いたとしても誤ってしまうこともありうることに注意すべきだと思います。
No.69「自己と非自己の科学(1)」で、人間の免疫システムの主役であるリンパ球の話を書きました。
これは "リンパ球" という細胞の話であり、分子よりは遙かに巨大なスケールでの現象です。それでも毎秒、100万個が死滅して100万個が生まれている。ちょっと想像しがたいような「数」の世界だということに注意すべきでしょう。
想像しがたいような数という意味で、前回の No.148「最適者の到来」で話題になったのは、遺伝子の組み合わせが超天文学的数字になるということでした。その「組み合わせの数」が我々の直感に合わない例の一つが、有名な「巡回セールスマン問題」です。
32都市を巡回するセールスマン
巡回セールスマン問題(Travelling Salesman Problem. TSP)とは次のような問題です。N 個の都市があり、すべての都市と都市の間は直通道路で結ばれていて、各道路の距離は分かっています。ある都市を起点とし、すべての都市を1度だけ訪問して起点の都市に戻る最短の経路は何か、というのがTSPです。
ありうるすべての経路の数を TSP(N) とすると、これは基本的には N 個の都市を一列に並べる順列の数なので、N!( = 1×2×3×・・・×N = Nの階乗 )ということになります。ただし一つの経路をとってみたとき、起点の都市を1だけ順にずらした N 個の経路は同じと数え、また逆経路も同じと数えるので、全体の数を 2*N で割り算する必要があります。つまり、
となります。TSPを解くには、TSP(N)個の経路を順に調べ、その経路長を計算して最小のものを選ぶという「総当たり法」がすぐに頭に浮かびます。
なので、4都市、5都市程度なら「総当たり法」で、電卓を用いて解を求めるのも十分可能です。
これが
となると、手計算での「総当たり法」は苦しくなります。しかしパソコンを使えば問題ありません。パソコンのプログラムが作れる人ならすぐにできるでしょう。EXCEL を使ってもよい。
10都市ぐらいならパソコンで十分に計算できます。ためしに実験してみました。国土地理院はホームページで「都道府県の県庁の相互直線距離」(精度は0.1km)を公開しています。このデータを使って、関東甲信越の1都・9県のTSPを解くことにします。パソコンで「総当たり法」のプログラムを作って実際にやってみると、約2秒(1.7秒)で解が求まりました。
このプログラムは、県庁間の距離(10県庁の相互の距離なので45ある)をセットする部分を除いて、純粋な解の探索部分は25行程度のシンプルなものです。いろいろと高速にする工夫をすれば、解を求める時間はもっと縮まるでしょう。おそらく普通の家庭のパソコンで1秒以内に答えが出る感じがします。
しかし表題にあげた32都市となると、最高速のコンピュータを使っても(総当たり法では)全く手に負えなくなります。32都市の巡回ルートを計算してみると、
となります。パソコンの発達で、こういった数字の計算だけならすぐにできるようになりました。
現在の日本で最も早いコンピュータは、理化学研究所と富士通が開発した「京」で、1秒間に1京回の演算ができる性能をもっています。ここでの演算とは実数の加減乗除のことです。"京" は "兆" の1万倍、 "兆" は "億"の1万倍、"億" は "万"の1万倍なので、1京 = 1016 です。
宇宙の年齢は135億年と考えられています。つまり1.35 × 1010年です。これを秒に直すと、× 365 × 24 × 60 × 60 の掛け算をして、
です。従って、スーパーコンピュータ「京」が宇宙の年齢時間でどれだけの演算ができるかと言うと、
となります。これは「32都市の巡回ルート数」と同じオーダの数です。もちろん1回の演算で1つの巡回ルートの距離を計算できるわけではありません。数十~数百の演算が必要でしょう。つまり32都市の巡回セールスマン問題を「総当たり法」で解こうとすると、スーパーコンピュータ「京」を宇宙の年齢時間だけ動かしても絶対に不可能ということになります。
だだしこれは「巡回セールスマン問題」が解けないということではありません。「総当たり法」ではダメなわけで、現在の最新の研究では、数千都市までであれば何とか解がみつかる手法が発見されています。しかしこれが万のオーダーの都市になると解を求めるのは不可能になり、近似解(最短ルートの距離に極めて近いことが保証できる解)しか求まらないようです。
10都市ならパソコンで2秒で可能な「総当たり」が、32都市となると最新鋭のスーパー・コンピュータを135億年間ぶっ続けで使ったとしても不可能になる・・・・・・。これは常識的感覚からするとかなり意外な感じではないでしょうか。
組み合わせの数は、すぐに超天文学的数字になります。その「多さ」をベースに起こる事象を、我々は直感しにくい。有名な「バースデー・パラドックス」がその例です。
バースデー・パラドックス
いわゆる「バースデー・パラドックス」も、我々の直感が裏切られる有名な例です。「23人のクラスで、誕生日が同じ人がいる確率は ?」という問いの答えは「0.5を越える」というのが正解です。えっ!と思ってしまいますが、このウラには「組み合わせから発生する巨大な数どうしの比較」が潜んでいて、それが直感を裏切ることになるのです。
クラスの全員を区別して考えるとし、1年を365日に固定すると、23人クラスの誕生日の組み合わせ数は365の23乗になります。この数を B(23) と書くことにし、実際に計算してみると、
になります。これは天文学的に巨大な数ですが「全員が元旦生まれ」というような組み合わせも含まれていることを考えると、なんとなく納得できます。
一方、23人全員の誕生日が異なる組み合わせ数は、出席番号1番の人は365通り、2番の人は364通り、・・・・・・ となり、つまり 365 × 364 × ・・・・・・ × 343(23個の数字の掛け算)となります。この数を D(23)とし、実際に計算してみると、
となります。同じ誕生日の人がいる組み合わせ数は、B(23) から D(23) を引き算すればいいわけですから、この数を C(23) とすると、
です。従って同じ誕生日の人がいる確率は、23人のクラスの場合、
と計算でき、確かに確率は半分を越えます。ちなみにクラスの人数を変えて計算してみると、
となります。20人クラスだとしても確率は 41% もあります。これが40人クラスともなると 89% になり「ほぼ確実に誕生日が同じ人が、少なくとも1組はある」ことになります。
23人のクラスの場合、確率は本質的に59桁の数字どうしの割り算になります。全体の組み合わせの数は天文学的に大きいが、ある条件(=誕生日が同じ人がいる)を加えた組み合わせの数もまた天文学的に大きいのです。「バースデー・パラドックス」には「組み合わせから発生する巨大な数どうしの比較」が隠れていて、我々の "正しい直感" が働かないことになるのです。
カジノ・ゲーム
「バースデー・パラドックス」を応用して次のようなカジノ・ゲームを想定すると、より "直感との乖離" が明確になると思います。あなたはカジノで掛け金を積んでディーラーと対決します。

このゲームは、あなた(客)にとって有利でしょうか、それとも不利でしょうか。あなたが勝つ確率はどれぐらいでしょうか。
あなたは(おそらく)次のように考えると思います。2回目に「引いてはいけないカード」は1枚しかない。これは自分が圧倒的に有利である。また3回目も2枚だけを引かなければよい。つまり有利だ。最後の10回目を考えると「引いてはいけない」カードが9枚あるが「引いてもいいカード」は44枚もある。確かに9枚のどれかを引いてしまうこともあるだろうが、まだ随分自分が有利のはずである。もちろん、1回のチャレンジでは負けることもあるだろうが、何回もやれば自分がかなり有利なはずだ・・・・・・。
しかし事実は違います。「バースデー・パラドックス」により、このゲームは客が不利です。全部が違うカードである確率を Q とし、365日ではなく53枚なので53という添え字をつけて区別することにします。計算してみると、
となり、客が勝つ確率は 40% しかありません。ディーラーは客の1.5倍の確率で勝つのです。このゲームは、引く枚数が少ないほど客が有利になるのは当然なので、引く枚数を変えて計算してみると、
となって、引く枚数が9枚でもまだ客が不利です。8枚になって初めて客が有利になることが分かります。
このゲームに潜んでいる組み合わせの数は、オリジナルの「バースデー・パラドックス」よりは随分小さいものですが、それでも 17京とか 7京 という、日常では全く使わないオーダーの数です。しかしそんな巨大な数が潜んでいるとは、客は到底思えない。このゲームで客に明示されている「数」は、53(枚)と10(回)しかないのだから・・・・・・。そこに "正しい直感" が働かない理由があるのだと思います。
6次の隔たり
巡回セールスマン問題の "巡回ルート" は膨大な数になるわけですが、それが膨大になる原因は、都市と都市が直通道路で結ばれているという「完全な」ネットワークの存在です。つまり、ある都市からは別の任意の都市へ、ワンステップで(直通で)行けるという仮定です。
もちろん現実のネットワークは、道路にしろ航空路にしろ「完全」ではありません。また社会における人間関係(知人関係)や企業の取引関係のネットワークにおいて、1人、ないしは1社が持ちうる関係の数は、高々、数十から数百、多い企業でも数千から万のオーダーでしょう。しかしこういった現実のネットワークでも、ワンステップとはいかないが、数回の関係をたどれば「思いのほか遠いところ」まで行けることがあります。それは直感に反していることが多い。その典型が「6次の隔たり」仮説です。
以下、アルバート = ラズロ・バラバシ著『新ネットワーク思考』(NHK出版。2002)に従って、この仮説を概観してみます。バラバシ氏は米国・ノートルダム大学物理学科教授(当時)です。ここで言う「6次の隔たり」とは、
という仮説です。「あなたは世界中のすべての人と、たった6人を介することで、知り合いの関係でつながる」と言っている。この「世界のすべての人」の "数の多さ" と「6」という "小さな数" のミスマッチ感が、仮説の意外性を高めています。
この仮説を最初に述べたのは、ハンガリーの作家・カリンティが書いた小説『鎖』(1929)ですが、有名にしたのはハーバード大学教授のスタンレー・ミルグラムの実験で、それは1967年のことです。当時、ハーバードやMITでは社会ネットワークの研究が盛んで、ミルグラム教授もその一人でした。
この引用に出てくるケンブリッジとはもちろん、ハーバード大学のある、ボストンの北隣りの町です。
ミルグラム教授はカンザス州ウィチトーとネブラスカ州オマハの二つの町からランダムに住人を160人選び、フォルダーを送付しました。そのフォルダーには、手紙と目標人物の情報(写真、住所、氏名、プロフィール)、ハーバード大学宛のハガキの束がセットされていました。手紙には、アメリカ社会の人間関係に関する研究に協力してもらいたいとの主旨が書かれ、この手紙を受け取った人の名前を順に記入する名簿が用意されています。手紙では、調査への参加方法が次のように書かれていました。
ミルグラム教授は「手紙が1通も目標人物に届かず、実験が失敗に終わるのでは」と心配しました。というも、もし100もの "リンク"(出発点になる人と目標人物の間になる人)が必要だとしたら、その中には必ず「非協力的な人」がいるだろうと想定できるからです。
しかし結果は全く意外なものでした。数日後には最初の手紙が目標人物に届き、そのリンクはたったの2でした。そして最終的には160通のうちの42通が目標人物に届きました。中には10程度のリンクを必要としたものもありましたが、リンクの平均値は 5.5 だったのです。四捨五入すると 6 になります。
ただし、これを「6次の隔たり」の証明とするには難があります。まず、アメリカ国内に限られた実験であり、世界が相手ではないことです。また、届かなかった手紙が 118 あり、これをどう考えるかも問題です。たとえば 2 ステップ目で「非協力的な人」に当たってしまった場合もあるだろうし、20 ステップ目まで行って協力者が途絶えたということもあるでしょう。届いた手紙だけの平均値で議論するのは、理論というには弱い。実際、ミルグラム教授自身は「6次の隔たり」という言葉は使っていません。「6次の隔たり(6 degrees of Separation)」は、あくまで後の人がつけたものなのです。
とはいえ、ミルグラム教授の実験は「赤の他人が予想に反した短いリンクで知り合い同士」ということを明らかにしました。少なくとも、手紙が届いた42人の出発点の人と目標人物の間はそうなのです。ミルグラム教授の知人は「100人の人を介する必要があるだろう」と言ったわけですが、これが我々の直感的な感覚です。なにしろ、遠隔地に住む赤の他人同士なのだから・・・・・・。しかしそうではない。知人のネットワークというのはそういう性質をもっていて、世の中は「意外と狭い」のです。この「意外と狭い」ことを、ネットワーク理論では「スモールワールド」と呼んでいます。ミルグラム教授の実験も「スモールワールド実験」と呼ばれることがあります。
「6次の隔たり」は、現在の Facebook やミクシィなどの SNS(Social Networking Service)が成立する原理になっています。Web ニュースである「IT Media ニュース」の2011.11.23.付に次のような記事が載っています。
数字の記述がちょっと曖昧なのですが、Facebookのサイトに公開されている原文をみると「ペアの99.6%は5次の隔たり(相手が6人目)以下でつながり、92%は4次の隔たり(相手が5人目)以下でつなががっていた」が正確な説明です。
Facebookの平均値を四捨五入すると「4次の隔たり(相手が5人目)」ということになります。もちろんこれはFacebookのユーザという「ある種の特性」をもった集団での話であって、世界のすべての人に敷衍するわけにはいきません。しかし「任意の2人の友達関係のパスは意外と近い」ことは確かだと思います。
代謝のネットワーク
アルバート = ラズロ・バラバシ著『新ネットワーク思考』という本には、スモールワールドの性質をもつネットワークの数々の例が出ています。その中に第13章「生命の地図」と題された章があります。ここに、細胞内に存在する「代謝のネットワーク」の話が出てきます。
前回の No.148「最適者の到来」にも書いたように、代謝とは生命体で起きる化学反応です。たとえば
A + B → C + D
という代謝があった場合、AおよびBという生体分子は、CおよびDの生体分子とネットワークで結ばれていると考えます。これを「1次の隔たり」または「距離が1」と呼ぶことにします(友人関係の1次とは少し意味が違うことに注意)。大腸菌などの細菌は、細胞内のすべての代謝が判明しています。従ってそこに登場する分子をすべて洗い出すと、分子間の「代謝ネットワーク」が描けることになります。著者は、代謝がすべて判明している43種の生物の「代謝ネットワーク」を作成し、そこで分子間の「距離」がどうなっているかを調べました。
ここを引用した理由は、代謝のネットワークの「3次の隔たり」が直感に反するからではありません(そんな直感はできない)。そうではなく、前回の No.148「最適者の到来」で紹介したアンドレアス・ワグナー教授の名前が出てくるからです。彼は「代謝のネットワーク」を研究し、次に「代謝の遺伝子型ネットワーク」の研究へと進んだようです。
直感に反する「事実」
ここまで、前回の No.148「最適者の到来」の続きとして書いてきたのですが、進化論との直接の関係はありません。しかし、ここまでにあげた、
というような認識は、前回の「遺伝子型ネットワーク」の構造に通じるものがあると思うのです。我々は、日常的感覚とはまったくかけ離れた「数」や「量」が支配する世界を、直感的判断で考えてしまうことは避けなければならないと思います。そして、このような世界を解明する一つの武器が、前回のワグナー教授も駆使したコンピュータなのでした。
本文中に関東甲信越10都県の県庁間をつなぐ巡回セールスマン問題を解いた結果を記載しました。念のため、プログラム(Python で記述)を掲げておきます。これで間違いはないはずです。
「最適者の到来」のテーマであった「進化」は、遺伝子型の変異が生物の表現型として現れ、自然選択の結果として最適者が残るというものです。このストーリーの発端になっている「遺伝子」とか「変異」とかは、いずれも生物の体内の分子レベルの話ですが、分子はその "サイズ" も "数" も我々が想像し難いような「小ささ」と「多さ」です。まず、そこを何とか想像してみたいと思います。
量の多さ:分子の数
簡単のために水の分子で考えてみます。コップ1杯の水を180g = 180ミリリットル(mL)とします。この中に水の分子はいくつあるでしょうか。
これは高校生で化学を習っている生徒なら即答できます。水を分子式で書くと H2O であり、分子量は 18(酸素=16、水素=1×2) なので「水 18g にはアボガドロ数だけの水分子が含まれる」ことになります。
| ◆ | アボガドロ数 =6 × 1023 = 6000,0000000000, 0000000000(24桁の数) |
なので、コップ1杯だとこれを10倍して、
| ◆ | コップ1杯(180g)の水分子の数 = 60000,0000000000, 0000000000(25桁)= A |
になります。数字のカンマは10桁ごとにつけました。この水分子の「数の多さ」を想像することは、我々にとって非常に困難です。どこだったかは忘れたのですが、海の水に例えての説明を以前に読んだことがあります。卓抜な比喩だと思うので、それで想像してみたいと思います。
これは思考実験です。コップ1杯の水分子に「赤い色」をつけるというのが出発点です。水に赤い染料を混ぜるのではなく、分子そのものに赤い色をつける。もちろん現実にそんなことは出来ないのですが、あくまで思考実験として考えます。
(思考実験)
| ① | コップ1杯の水分子に「赤い色」をつける。 | ||
| ② | それを海岸にもっていき、海に捨てる。 | ||
| ③ | 「赤い色」のついた水の分子が世界中の海にまんべんなく均等に行き渡るように、海をかき混ぜる。もちろん、太平洋、インド洋、大西洋、地中海、北極海、南氷洋などの世界中の海のすべてであり、海の表面から海の底まで、世界で一番深いとされるマリアナ海溝(太平洋。深さ10,900メートル)の底まで、均等に「赤い色の水分子」が混ざるようにする。 | ||
| ④ | ふたたび(どこでもいいから)海岸に行き、コップ一杯の海水をすくう。そのとき「赤い色の水分子」は、いくつコップに入るだろうか ? |
直観で答えるとすると、コップに入る「赤い色の水分子」は、あったとしても1個で、ほとんどの場合は無いと、多くの人は答えるのではないでしょうか。何しろ、世界中の海に均等に混ざってしまったのだから ・・・・・・。
この答は容易に計算できます。世界中にある海水の体積は約14億・立方キロメートルと推定されています。もう少し詳しくは、13.5億 とか 13.7億 とかの数字があります。ここでは13.5億・立方キロメートルとします。
| ◆ | 海の体積(立方キロメートル)= 1350000000(10桁) |
です。立方キロメートルとは、縦・横・高さが 1 キロメートルの立方体の体積ということです。1 キロメートルは 1000メートル = 100,000(105)センチメートルなので、海の体積を立方センチメートル(=mL。ミリリットル)で表すには、1015 を掛けて、
| ◆ | 海の体積(mL)= 13500,0000000000, 0000000000(25桁) |
となります。これがコップ何杯分に相当するかというと、180 mL で割り算をして、
| ◆ | 海の体積はコップ何杯分か = 75,0000000000, 0000000000(22桁)= B |
となります。上の思考実験で「赤い水の分子」がふたたびコップに入る数(④)は、A/B ですから、
| ◆ | コップの「赤い水分子」の数 = 800 |
となります。つまり、世界中のありとあらゆる海のすべてが、表面から深海の底まで、コップ1杯あたり800個の赤い水分子で完全に埋め尽くされている状況です。これはちょっと想像を越えているのではないでしょうか。
分子の数はそれほど「多い」わけです。もちろん生命の進化に関わるような、DNAとかアミノ酸とかタンパク質、その他の生命体を構成している分子は、分子量で言うと数十から数百、数万になるものも珍しくありません。水分子とは比較にならない巨大分子であることは確かです。しかし、それでも「多い」。こういう超巨大な数の世界では我々の直感は働かないか、働いたとしても誤ってしまうこともありうることに注意すべきだと思います。
No.69「自己と非自己の科学(1)」で、人間の免疫システムの主役であるリンパ球の話を書きました。
|
これは "リンパ球" という細胞の話であり、分子よりは遙かに巨大なスケールでの現象です。それでも毎秒、100万個が死滅して100万個が生まれている。ちょっと想像しがたいような「数」の世界だということに注意すべきでしょう。
想像しがたいような数という意味で、前回の No.148「最適者の到来」で話題になったのは、遺伝子の組み合わせが超天文学的数字になるということでした。その「組み合わせの数」が我々の直感に合わない例の一つが、有名な「巡回セールスマン問題」です。
32都市を巡回するセールスマン
巡回セールスマン問題(Travelling Salesman Problem. TSP)とは次のような問題です。N 個の都市があり、すべての都市と都市の間は直通道路で結ばれていて、各道路の距離は分かっています。ある都市を起点とし、すべての都市を1度だけ訪問して起点の都市に戻る最短の経路は何か、というのがTSPです。
ありうるすべての経路の数を TSP(N) とすると、これは基本的には N 個の都市を一列に並べる順列の数なので、N!( = 1×2×3×・・・×N = Nの階乗 )ということになります。ただし一つの経路をとってみたとき、起点の都市を1だけ順にずらした N 個の経路は同じと数え、また逆経路も同じと数えるので、全体の数を 2*N で割り算する必要があります。つまり、
| TSP(N) = (N-1)! / 2 |
となります。TSPを解くには、TSP(N)個の経路を順に調べ、その経路長を計算して最小のものを選ぶという「総当たり法」がすぐに頭に浮かびます。
| TSP(4) = 3 TSP(5) = 12 |
なので、4都市、5都市程度なら「総当たり法」で、電卓を用いて解を求めるのも十分可能です。
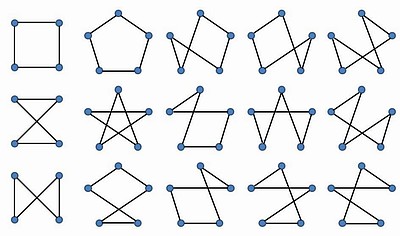
| ||
|
巡回セールスマン問題
4都市と5都市のすべての巡回経路 | ||
これが
| TSP(6) = 60 |
となると、手計算での「総当たり法」は苦しくなります。しかしパソコンを使えば問題ありません。パソコンのプログラムが作れる人ならすぐにできるでしょう。EXCEL を使ってもよい。
| ただし、すべての経路を漏れなく、かつ無駄は一切なしに調べるというプログラムは、ちょっと工夫が要ります。これは「プログラミング講座」の格好の演習問題になるでしょう。「再帰呼び出し」を使うとシンプルなプログラムになります(補記参照)。 |
10都市ぐらいならパソコンで十分に計算できます。ためしに実験してみました。国土地理院はホームページで「都道府県の県庁の相互直線距離」(精度は0.1km)を公開しています。このデータを使って、関東甲信越の1都・9県のTSPを解くことにします。パソコンで「総当たり法」のプログラムを作って実際にやってみると、約2秒(1.7秒)で解が求まりました。
| 181,440 | |||
| 東京 - 神奈川 - 千葉 - 茨城 - 栃木 - 新潟 - 長野 - 群馬 - 山梨 - 埼玉 - 東京 | |||
| 836.8 km | |||
| 2 秒 |
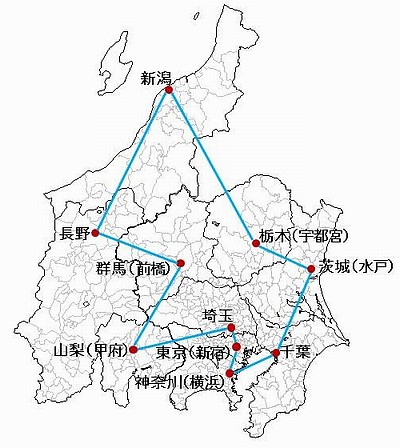
| ||
|
関東甲信越の県庁TSP
関東甲信越の1都・9県の都庁・県庁を直線で結ぶ「巡回セールスマン問題」の解。可能な経路の総数は 181,440 あるが、この程度の数なら「総当たり法」でも、パソコンで2秒以内に答えを出せる。最短経路の距離は 836.8km である。各県庁間の直線距離は国土地理院が公開しているデータを用いた。
| ||
このプログラムは、県庁間の距離(10県庁の相互の距離なので45ある)をセットする部分を除いて、純粋な解の探索部分は25行程度のシンプルなものです。いろいろと高速にする工夫をすれば、解を求める時間はもっと縮まるでしょう。おそらく普通の家庭のパソコンで1秒以内に答えが出る感じがします。
しかし表題にあげた32都市となると、最高速のコンピュータを使っても(総当たり法では)全く手に負えなくなります。32都市の巡回ルートを計算してみると、
| ◆ | 32都市の巡回ルート数 = TSP(32) = 4111,4193270889, 6140886278,1440000000(34桁) |
となります。パソコンの発達で、こういった数字の計算だけならすぐにできるようになりました。
現在の日本で最も早いコンピュータは、理化学研究所と富士通が開発した「京」で、1秒間に1京回の演算ができる性能をもっています。ここでの演算とは実数の加減乗除のことです。"京" は "兆" の1万倍、 "兆" は "億"の1万倍、"億" は "万"の1万倍なので、1京 = 1016 です。
宇宙の年齢は135億年と考えられています。つまり1.35 × 1010年です。これを秒に直すと、× 365 × 24 × 60 × 60 の掛け算をして、
| ◆ | 宇宙の年齢(秒)= 42573600,0000000000(18桁) |
です。従って、スーパーコンピュータ「京」が宇宙の年齢時間でどれだけの演算ができるかと言うと、
| ◆ | 「京」の宇宙年齢での演算回数 = 4257,3600000000, 0000000000,0000000000(34桁) |
となります。これは「32都市の巡回ルート数」と同じオーダの数です。もちろん1回の演算で1つの巡回ルートの距離を計算できるわけではありません。数十~数百の演算が必要でしょう。つまり32都市の巡回セールスマン問題を「総当たり法」で解こうとすると、スーパーコンピュータ「京」を宇宙の年齢時間だけ動かしても絶対に不可能ということになります。
だだしこれは「巡回セールスマン問題」が解けないということではありません。「総当たり法」ではダメなわけで、現在の最新の研究では、数千都市までであれば何とか解がみつかる手法が発見されています。しかしこれが万のオーダーの都市になると解を求めるのは不可能になり、近似解(最短ルートの距離に極めて近いことが保証できる解)しか求まらないようです。
10都市ならパソコンで2秒で可能な「総当たり」が、32都市となると最新鋭のスーパー・コンピュータを135億年間ぶっ続けで使ったとしても不可能になる・・・・・・。これは常識的感覚からするとかなり意外な感じではないでしょうか。
組み合わせの数は、すぐに超天文学的数字になります。その「多さ」をベースに起こる事象を、我々は直感しにくい。有名な「バースデー・パラドックス」がその例です。
バースデー・パラドックス
いわゆる「バースデー・パラドックス」も、我々の直感が裏切られる有名な例です。「23人のクラスで、誕生日が同じ人がいる確率は ?」という問いの答えは「0.5を越える」というのが正解です。えっ!と思ってしまいますが、このウラには「組み合わせから発生する巨大な数どうしの比較」が潜んでいて、それが直感を裏切ることになるのです。
クラスの全員を区別して考えるとし、1年を365日に固定すると、23人クラスの誕生日の組み合わせ数は365の23乗になります。この数を B(23) と書くことにし、実際に計算してみると、
| ◆ | 誕生日の組み合わせ数 = B(23) = 856516793,5315032123, 6814267844,3951526893, 5462236404,4189453125(59桁) |
になります。これは天文学的に巨大な数ですが「全員が元旦生まれ」というような組み合わせも含まれていることを考えると、なんとなく納得できます。
一方、23人全員の誕生日が異なる組み合わせ数は、出席番号1番の人は365通り、2番の人は364通り、・・・・・・ となり、つまり 365 × 364 × ・・・・・・ × 343(23個の数字の掛け算)となります。この数を D(23)とし、実際に計算してみると、
| ◆ | 全員の誕生日が異なる組み合わせ数 = D(23)= 422008193,0209235987, 2395663074,9089572537, 4976070077,6448000000(59桁) |
となります。同じ誕生日の人がいる組み合わせ数は、B(23) から D(23) を引き算すればいいわけですから、この数を C(23) とすると、
| ◆ | 同じ誕生日の人がいる組み合わせ数 = C(23) = B(23) - D(23) = 434508600,5105796136, 4418604769,4861954356, 0486166326,7741453125(59桁) |
です。従って同じ誕生日の人がいる確率は、23人のクラスの場合、
| ◆ | 同じ誕生日の人がいる確率 = P(23) = C(23) / B(23) = 0.50729723 |
と計算でき、確かに確率は半分を越えます。ちなみにクラスの人数を変えて計算してみると、
| P(20) = 0.41143838 P(25) = 0.56869970 P(30) = 0.70631624 P(35) = 0.81438323 P(40) = 0.89123180 |
となります。20人クラスだとしても確率は 41% もあります。これが40人クラスともなると 89% になり「ほぼ確実に誕生日が同じ人が、少なくとも1組はある」ことになります。
23人のクラスの場合、確率は本質的に59桁の数字どうしの割り算になります。全体の組み合わせの数は天文学的に大きいが、ある条件(=誕生日が同じ人がいる)を加えた組み合わせの数もまた天文学的に大きいのです。「バースデー・パラドックス」には「組み合わせから発生する巨大な数どうしの比較」が隠れていて、我々の "正しい直感" が働かないことになるのです。
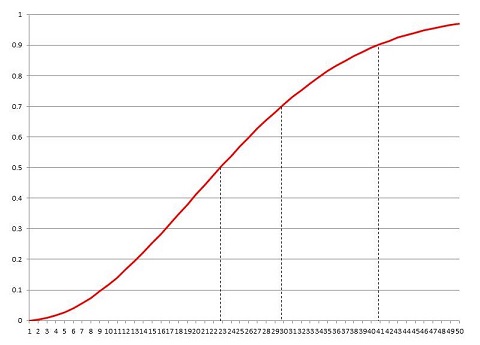
| ||
|
バースデー・パラドックス
横軸はクラスの人数。縦軸は、少なくとも1組の誕生日が同じ生徒がいる確率。23人クラスで確率は0.5を超える。30人クラスで0.7を超え、41人クラスで0.9を超える。
| ||
カジノ・ゲーム
「バースデー・パラドックス」を応用して次のようなカジノ・ゲームを想定すると、より "直感との乖離" が明確になると思います。あなたはカジノで掛け金を積んでディーラーと対決します。
| ① | ディーラーは、ジョーカーを含む53枚のトランプのカードをよくシャッフルし、裏にしてテーブルの上に広げます。 | ||
| ② | あなた(客)はどれでもいいから1枚を選び、そのカードを表にします。 | ||
| ③ | ディーラーは、表になった1枚のカードを覚えておくため、別のトランプの1組から同じカードを選び、テーブルの隅に表にして置きます。 | ||
| ④ | あなたは選んだカードを、裏になっているカードの任意の場所に裏にして返します。 | ||
| ⑤ | ①のシャッフルから④までの手順を、最初の1回を含めて合計10回繰り返します。 | ||
| ⑥ | 10回カードを引いて同じカードを1枚も引かなかったら、あなたの勝ちになり、掛け金は2倍になって帰ってきます。1度でも同じカードを引いてしまったら、その時点であなたの負けで、掛け金は没収されます。もちろん不正は一切ありません。 |
このゲームは、あなた(客)にとって有利でしょうか、それとも不利でしょうか。あなたが勝つ確率はどれぐらいでしょうか。
あなたは(おそらく)次のように考えると思います。2回目に「引いてはいけないカード」は1枚しかない。これは自分が圧倒的に有利である。また3回目も2枚だけを引かなければよい。つまり有利だ。最後の10回目を考えると「引いてはいけない」カードが9枚あるが「引いてもいいカード」は44枚もある。確かに9枚のどれかを引いてしまうこともあるだろうが、まだ随分自分が有利のはずである。もちろん、1回のチャレンジでは負けることもあるだろうが、何回もやれば自分がかなり有利なはずだ・・・・・・。
しかし事実は違います。「バースデー・パラドックス」により、このゲームは客が不利です。全部が違うカードである確率を Q とし、365日ではなく53枚なので53という添え字をつけて区別することにします。計算してみると、
| B53(10) = 17488747,0365513049(18桁) D53(10) = 7075833,2701056000(17桁) Q53(10) = D53(10) / B53(10) = 0.40459349 |
となり、客が勝つ確率は 40% しかありません。ディーラーは客の1.5倍の確率で勝つのです。このゲームは、引く枚数が少ないほど客が有利になるのは当然なので、引く枚数を変えて計算してみると、
| Q53(9) = 0.48735125 Q53(8) = 0.57399147 |
となって、引く枚数が9枚でもまだ客が不利です。8枚になって初めて客が有利になることが分かります。
このゲームに潜んでいる組み合わせの数は、オリジナルの「バースデー・パラドックス」よりは随分小さいものですが、それでも 17京とか 7京 という、日常では全く使わないオーダーの数です。しかしそんな巨大な数が潜んでいるとは、客は到底思えない。このゲームで客に明示されている「数」は、53(枚)と10(回)しかないのだから・・・・・・。そこに "正しい直感" が働かない理由があるのだと思います。
6次の隔たり
巡回セールスマン問題の "巡回ルート" は膨大な数になるわけですが、それが膨大になる原因は、都市と都市が直通道路で結ばれているという「完全な」ネットワークの存在です。つまり、ある都市からは別の任意の都市へ、ワンステップで(直通で)行けるという仮定です。
もちろん現実のネットワークは、道路にしろ航空路にしろ「完全」ではありません。また社会における人間関係(知人関係)や企業の取引関係のネットワークにおいて、1人、ないしは1社が持ちうる関係の数は、高々、数十から数百、多い企業でも数千から万のオーダーでしょう。しかしこういった現実のネットワークでも、ワンステップとはいかないが、数回の関係をたどれば「思いのほか遠いところ」まで行けることがあります。それは直感に反していることが多い。その典型が「6次の隔たり」仮説です。
以下、アルバート = ラズロ・バラバシ著『新ネットワーク思考』(NHK出版。2002)に従って、この仮説を概観してみます。バラバシ氏は米国・ノートルダム大学物理学科教授(当時)です。ここで言う「6次の隔たり」とは、
| 世界中のどの2人をとっても、6人を介することで知人同士で繋がる |
という仮説です。「あなたは世界中のすべての人と、たった6人を介することで、知り合いの関係でつながる」と言っている。この「世界のすべての人」の "数の多さ" と「6」という "小さな数" のミスマッチ感が、仮説の意外性を高めています。
この仮説を最初に述べたのは、ハンガリーの作家・カリンティが書いた小説『鎖』(1929)ですが、有名にしたのはハーバード大学教授のスタンレー・ミルグラムの実験で、それは1967年のことです。当時、ハーバードやMITでは社会ネットワークの研究が盛んで、ミルグラム教授もその一人でした。
|
この引用に出てくるケンブリッジとはもちろん、ハーバード大学のある、ボストンの北隣りの町です。
ミルグラム教授はカンザス州ウィチトーとネブラスカ州オマハの二つの町からランダムに住人を160人選び、フォルダーを送付しました。そのフォルダーには、手紙と目標人物の情報(写真、住所、氏名、プロフィール)、ハーバード大学宛のハガキの束がセットされていました。手紙には、アメリカ社会の人間関係に関する研究に協力してもらいたいとの主旨が書かれ、この手紙を受け取った人の名前を順に記入する名簿が用意されています。手紙では、調査への参加方法が次のように書かれていました。
| ① | 名簿に自分の名前を記入してください。それによってこの手紙を次に受け取る人は、手紙の差出人が分かります。 | ||
| ② | ハガキを1枚とり、必要事項を記入してハーバード大学に返送してください。切手は不要です。これによりハーバード大学は、手紙が目標人物に近づいていく過程を追跡できます。 | ||
| ③ | もしもあなたが目標人物を個人的に知っているなら、この手紙を含むフォルダーを直接、目標人物に送付してください。これは、過去において目標人物に直接会ったことがあり、ファーストネームで呼び合う関係である場合にのみ実行してください。 | ||
| ④ | 目標人物を個人的に知らない場合は、直接、目標人物に連絡を取らないでください。その代わりに、このフォルダー(手紙、ハガキを含む一切)を、あなたよりも目標人物をよく知っていそうな人物に送付してください。フォルダーを送付してよい相手は、友人、親戚、知り合いですが、ファーストネームで呼び合う関係でなければなりません。 |

| |||
|
バラバシ著
「新ネットワーク思考」 | |||
しかし結果は全く意外なものでした。数日後には最初の手紙が目標人物に届き、そのリンクはたったの2でした。そして最終的には160通のうちの42通が目標人物に届きました。中には10程度のリンクを必要としたものもありましたが、リンクの平均値は 5.5 だったのです。四捨五入すると 6 になります。
ただし、これを「6次の隔たり」の証明とするには難があります。まず、アメリカ国内に限られた実験であり、世界が相手ではないことです。また、届かなかった手紙が 118 あり、これをどう考えるかも問題です。たとえば 2 ステップ目で「非協力的な人」に当たってしまった場合もあるだろうし、20 ステップ目まで行って協力者が途絶えたということもあるでしょう。届いた手紙だけの平均値で議論するのは、理論というには弱い。実際、ミルグラム教授自身は「6次の隔たり」という言葉は使っていません。「6次の隔たり(6 degrees of Separation)」は、あくまで後の人がつけたものなのです。
とはいえ、ミルグラム教授の実験は「赤の他人が予想に反した短いリンクで知り合い同士」ということを明らかにしました。少なくとも、手紙が届いた42人の出発点の人と目標人物の間はそうなのです。ミルグラム教授の知人は「100人の人を介する必要があるだろう」と言ったわけですが、これが我々の直感的な感覚です。なにしろ、遠隔地に住む赤の他人同士なのだから・・・・・・。しかしそうではない。知人のネットワークというのはそういう性質をもっていて、世の中は「意外と狭い」のです。この「意外と狭い」ことを、ネットワーク理論では「スモールワールド」と呼んでいます。ミルグラム教授の実験も「スモールワールド実験」と呼ばれることがあります。
「6次の隔たり」は、現在の Facebook やミクシィなどの SNS(Social Networking Service)が成立する原理になっています。Web ニュースである「IT Media ニュース」の2011.11.23.付に次のような記事が載っています。
|
数字の記述がちょっと曖昧なのですが、Facebookのサイトに公開されている原文をみると「ペアの99.6%は5次の隔たり(相手が6人目)以下でつながり、92%は4次の隔たり(相手が5人目)以下でつなががっていた」が正確な説明です。
Facebookの平均値を四捨五入すると「4次の隔たり(相手が5人目)」ということになります。もちろんこれはFacebookのユーザという「ある種の特性」をもった集団での話であって、世界のすべての人に敷衍するわけにはいきません。しかし「任意の2人の友達関係のパスは意外と近い」ことは確かだと思います。
代謝のネットワーク
アルバート = ラズロ・バラバシ著『新ネットワーク思考』という本には、スモールワールドの性質をもつネットワークの数々の例が出ています。その中に第13章「生命の地図」と題された章があります。ここに、細胞内に存在する「代謝のネットワーク」の話が出てきます。
前回の No.148「最適者の到来」にも書いたように、代謝とは生命体で起きる化学反応です。たとえば
A + B → C + D
という代謝があった場合、AおよびBという生体分子は、CおよびDの生体分子とネットワークで結ばれていると考えます。これを「1次の隔たり」または「距離が1」と呼ぶことにします(友人関係の1次とは少し意味が違うことに注意)。大腸菌などの細菌は、細胞内のすべての代謝が判明しています。従ってそこに登場する分子をすべて洗い出すと、分子間の「代謝ネットワーク」が描けることになります。著者は、代謝がすべて判明している43種の生物の「代謝ネットワーク」を作成し、そこで分子間の「距離」がどうなっているかを調べました。
|
ここを引用した理由は、代謝のネットワークの「3次の隔たり」が直感に反するからではありません(そんな直感はできない)。そうではなく、前回の No.148「最適者の到来」で紹介したアンドレアス・ワグナー教授の名前が出てくるからです。彼は「代謝のネットワーク」を研究し、次に「代謝の遺伝子型ネットワーク」の研究へと進んだようです。
直感に反する「事実」
ここまで、前回の No.148「最適者の到来」の続きとして書いてきたのですが、進化論との直接の関係はありません。しかし、ここまでにあげた、
| ◆ | 組み合わせの数は、考える以上に膨大な数になる。 | ||
| ◆ | 全体の組み合わせの数は膨大になるが、特定の条件をつけた組み合わせの数も直感に反して膨大になる(ことがある) | ||
| ◆ | ネットワークでつながったもの同士が、意外にも短い経路でつながっている(ことががある) |
というような認識は、前回の「遺伝子型ネットワーク」の構造に通じるものがあると思うのです。我々は、日常的感覚とはまったくかけ離れた「数」や「量」が支配する世界を、直感的判断で考えてしまうことは避けなければならないと思います。そして、このような世界を解明する一つの武器が、前回のワグナー教授も駆使したコンピュータなのでした。
| 巡回セールスマン問題 |
本文中に関東甲信越10都県の県庁間をつなぐ巡回セールスマン問題を解いた結果を記載しました。念のため、プログラム(Python で記述)を掲げておきます。これで間違いはないはずです。
# 関東甲信越10都県の県庁の相互間距離
# 出典:国土地理院「都道府県庁間の距離」単位:km
# (https://www.gsi.go.jp/KOKUJYOHO/kenchokan.html)
#
distance_matrix = [
[], # 茨城=0 (この行は参照されない)
[ 56.3] , # 栃木=1
[124.5, 76.2] , # 群馬=2
[ 89.7, 81.4, 79.5] , # 埼玉=3
[ 86.8, 108.8, 129.6, 51.2] , # 千葉=4
[ 99.3, 98.8, 96.4, 19.0, 40.2] , # 東京=5
[122.9, 25.9, 117.1, 45.4, 47.0, 27.2] , # 神奈川=6
[214.5, 66.8, 167.7, 233.7, 273.2, 252.7, 277.9] , # 新潟=7
[185.3, 155.0, 92.1, 100.0, 141.0, 101.7, 100.3, 251.7], # 山梨=8
[205.9, 152.6, 83.9, 158.7, 209.9, 172.8, 187.5, 157.7, 115.0] # 長野=9
# 茨城 栃木 群馬 埼玉 千葉 東京 神奈川 新潟 山梨
]
pref = ["茨城", "栃木", "群馬", "埼玉", "千葉",
"東京", "神奈川", "新潟", "山梨", "長野"]
cities = len(pref)
# ルートの生成
def genRoute(n):
if n == 3:
yield [0, 1, 2] # 必ず都市 0 から開始。3都市のルートは1つ。
else:
for route in genRoute(n-1):
for i in range(1, n):
new_route = route.copy()
new_route.insert(n-i, n-1) # 新都市(n-1)を既知ルートに挿入
yield new_route
# メインプログラム
min_distance = 1000.0 * cities # ダミーの値
route_count = 0
history = {}
for route in genRoute(cities):
route_count += 1
distance = 0.0
for i in range(cities):
start, end = route[i], route[(i + 1) % cities]
if start < end:
start, end = end, start # 必ず start > end に
distance += distance_matrix[start][end]
if distance >= min_distance:
break
if distance < min_distance:
min_distance, min_route = distance, route
history[tuple(route)] = distance
# 結果出力
min_route_name = "→".join( [pref[min_route[i]] for i in range(cities)])
print(f"ルート総数 = {route_count}")
print(f"最短ルート\n = {tuple(min_route)}\n = ({min_route_name})")
print(f"最短距離 = {min_distance:.1f} km")
print(f"ルート探索履歴 = ")
for r, d in history.items(): print(f" {r} = {d:.1f}")
(実行結果)
ルート総数 = 181440
最短ルート
= (0, 1, 7, 9, 2, 8, 3, 5, 6, 4)
= (茨城→栃木→新潟→長野→群馬→山梨→埼玉→東京→神奈川→千葉)
最短距離 = 836.8 km
ルート探索履歴 =
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9) = 1181.1
(0, 1, 2, 3, 4, 5, 6, 7, 9, 8) = 1066.5
(0, 1, 2, 3, 4, 5, 6, 8, 7, 9) = 1046.2
(0, 1, 2, 3, 4, 5, 6, 8, 9, 7) = 918.1
(0, 1, 2, 7, 9, 8, 3, 4, 5, 6) = 914.4
(0, 1, 7, 9, 2, 8, 3, 4, 5, 6) = 898.3
(0, 1, 2, 7, 9, 8, 3, 4, 6, 5) = 897.6
(0, 1, 7, 9, 2, 8, 3, 4, 6, 5) = 881.5
(0, 1, 2, 7, 9, 8, 3, 5, 6, 4) = 852.9
(0, 1, 7, 9, 2, 8, 3, 5, 6, 4) = 836.8
2015-07-04 12:17
nice!(0)
トラックバック(0)



